
RAG - 生成增强
何时增强
判断是否需要增强的核心在于判断大语言模型是否具有内部知识。
外部观测法,
- 通过Prompt 直接询问模型是否具备内部知识,或应用统计方法对是否具备内部知识进行估计,这种方法无需感知模型参数。
- 问询方式
- Prompt 直接询问大语言模型是否含有相应的内部知识
- 反复询问大语言模型同一个问题观察模型多次回答的一致性
- 通过翻看大语言模型的“教育经历”,即训练数据来判断其是否具备内部知识。
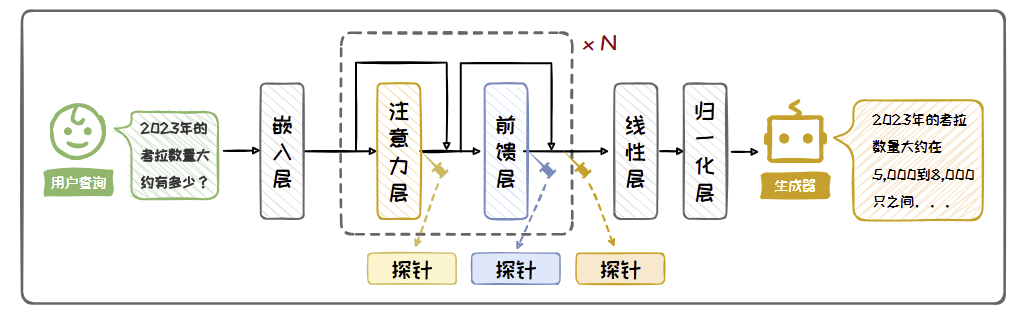
内部观测法
- 通过检测模型内部神经元的状态信息来判断模型是否存在内部知识,这种方法需要对模型参数进行侵入式的探测。
- 由于模型的内部知识检索主要发生在中间层的前馈网络中,因此在处理包含或不包含内部知识的不同问题时,模型的中间层会展现出不同的动态变化。基于这一特性,我们可以训练分类器进行判别,这种方法被称为探针。
- 通过检测模型内部神经元的状态信息来判断模型是否存在内部知识,这种方法需要对模型参数进行侵入式的探测。
何处增强
得益于大语言模型的上下文学习能力、注意力机制的可扩展性以及自回归生成能力,其输入端、中间层和输出端都可以进行知识融合操作。
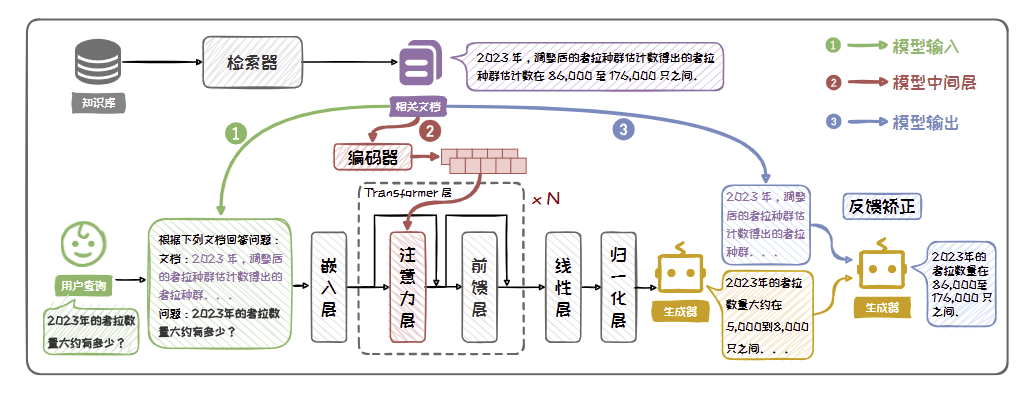
- 在输入端,可以将问题和检索到的外部知识拼接在Prompt中,然后输入给大语言模型
- 在中间层,可以采用交叉注意力将外部知识直接编码到模型的隐藏状态中;
- 在输出端,可以利用外部知识对生成的文本进行后矫正。
在输入端增强
良好的Prompt 设计和外部知识排序,可以使模型更好地理解、利用外部知识。模型可以直接从输入的上下文中提取到所需信息,无需复杂的处理或转换。
在中间层增强
利用注意力机制的灵活性,先将检索到的外部知识转换为向量表示,然后将这些向量插入通过交叉注意力融合到模型的隐藏状态中。这种方法能够更深入地影响模型的内部表示,可能有助于模型更好地理解和利用外部知识。同时,由于向量表示通常比原始文本更为紧凑,这种方法可以减少对模型输入长度的依赖。
在输出端增强
利用检索到的外部知识对大语言模型生成的文本进行校准,是一种后处理的方法。在此类方法中,模型首先在无外部知识的情况下生成一个初步回答,然后再利用检索到的外部知识来验证或校准这一答案。校验过程基于生成文本与检索文本的知识一致性对输出进行矫正。矫正可以通过将初步回答与检索到的信息提供给大模型,让大模型检查并调整生成的回答来完成。
多次增强
对于复杂问题和模糊问题,难以通过一次检索增强就确保生成正确,多次迭代检索增强在所难免。
- 处理复杂问题时,常采用分解式增强的方案。该方案将复杂问题分解为多个子问题,子问题间进行迭代检索增强,最终得到正确答案。
- 处理模糊问题时,常采用渐进式增强的方案。该方案将问题的不断细化,然后分别对细化的问题进行检索增强,力求给出全面的答案,以覆盖用户需要的答案。
分解式增强
DEMONSTRATE–SEARCH–PREDICT(DSP)是一种具有代表性的分解式增强框架。它的核心思想是:将一个复杂的问答任务分解为三个清晰的阶段,以模拟人类解决问题时的思维过程,从而显著提高模型回答的准确性和可解释性。该框架主要包含以下三个模块:
- DEMONSTRATE(示范/分解)
- 目标:将原始问题分解为一系列可执行的子步骤。
- 方法:通过提供几个“问题 → 推理步骤”的示例(few-shot prompting),引导模型学会如何拆解问题。
- 关键:这些示例展示了如何将模糊或复杂的查询转化为具体的、有序的行动指令。
示例:
原始问题:“为什么20世纪初的飞机飞行距离很短?”
分解后步骤:
1. 搜索“20世纪初飞机使用的发动机类型”。
2. 搜索“早期飞机燃料效率”。
3. 搜索“当时航空材料对重量的影响”。
4. 综合信息,解释飞行距离受限的原因。
- SEARCH(搜索/检索)
- 目标:根据上一步生成的子问题,调用外部知识源进行检索。
- 方法:使用传统搜索引擎(如Bing、Google)或向量数据库,获取与每个子问题相关的文档或段落。
- 作用:弥补LLM知识截止和幻觉问题,引入最新、准确的外部信息。
示例:
子问题:“20世纪初飞机使用的发动机类型”
检索结果:“早期飞机多使用活塞式发动机,功率低,油耗高。”
- PREDICT(预测/生成)
- 目标:基于检索到的信息,生成最终答案。
- 方法:将原始问题、分解步骤和检索到的证据输入LLM,让其综合所有信息进行推理并输出答案。
- 特点:答案不再是凭空生成,而是有据可依,可追溯。
示例:
最终答案:“20世纪初的飞机飞行距离短,主要是因为其使用的活塞式发动机功率有限且燃料效率低,同时机身材料较重,导致续航能力不足。”
渐进式增强
在处这样的模糊问题时,可以对问题进行渐进式地拆解、细化,然后对细化后的问题进行检索,利用检索到的信息增强大模型。
TREE OF CLARIFICATIONS (TOC),中文可译为 “澄清之树” 或 “疑问树”,是一种用于提升大型语言模型(LLM)在面对模糊、歧义或信息不完整查询时表现的交互式提示框架。
TOC 的工作流程:
- 识别歧义(Ambiguity Detection)
- 生成澄清问题(Generate Clarifying Questions)
- 构建树状结构(Tree Structure)
- 收敛到明确意图(Converge to Intent)
- 生成最终回答(Final Answer Generation)
降本增效
检索出的外部知识通常包含大量原始文本。将其通过Prompt 输入给大语言模型时,会大幅度增加输入Token 的数量,从而增加了大语言模型的推理计算成本。此问题可从去除冗余文本与复用计算结果两个角度进行解决。
去除冗余文本
去除冗余文本的方法主要分为三类:
- Token 级别的方法
- 通过对Token 进行评估,对文本中不必要的Token 进行剔除。
- 子文本级别的方法
- 通过对子文本进行打分,对不必要的子文本成片删除。
- 全文本级别的方法
- 直接从整个文档中抽取出重要信息,以去除掉冗余信息。
复用计算结果
为了避免对每个Token 都重新计算前面的Key 和Value 的结果,可以将之前计算的Key和Value的结果进行缓存(即KV-cache),在需要是直接从KV-cache中调用相关结果,从而避免重复计算。