
模型编辑 - 定位编辑法
概述
定位编辑首先定位知识存储在神经网络中的哪些参数中,然后再针对这些定位到的参数进行精确的编辑。
知识存储位置
ROME(Rank-One Model Editing)通过因果跟踪实验和阻断实验发现知识存储于模型中间层的全连接前馈层。
具体地,因果跟踪实验的步骤如下:
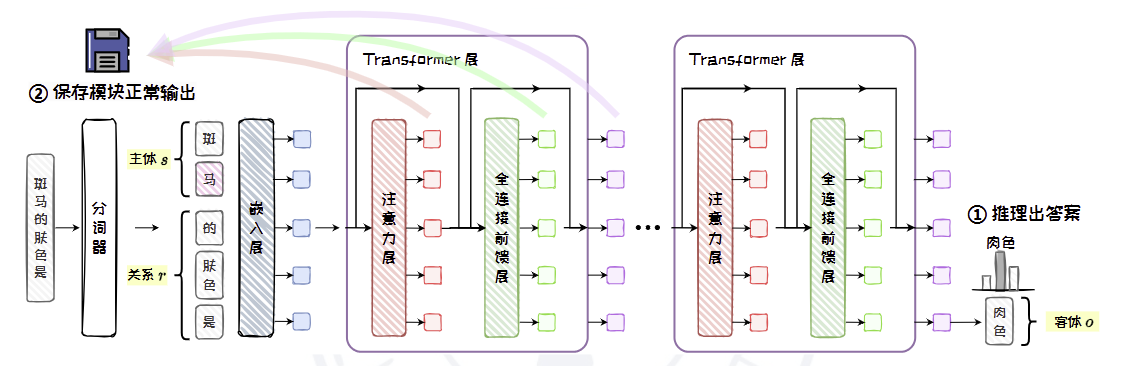
- 正常推理:将q输入语言模型,让模型预测出o。在此过程中,保存模型内部的所有模块的正常输出,用于后续恢复操作。
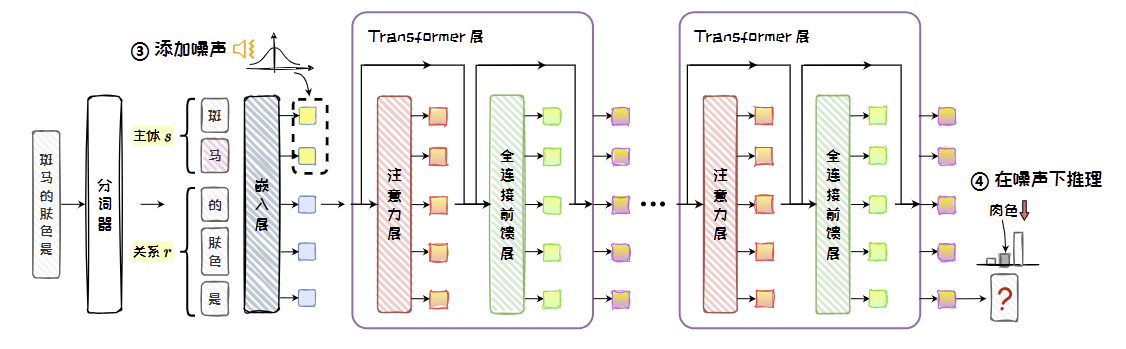
- 干扰推理:向s部分的嵌入层输出添加噪声,破坏其向量表示。在这种破坏输入的情况下,让模型进行推理,在内部形成被干扰的混乱状态。
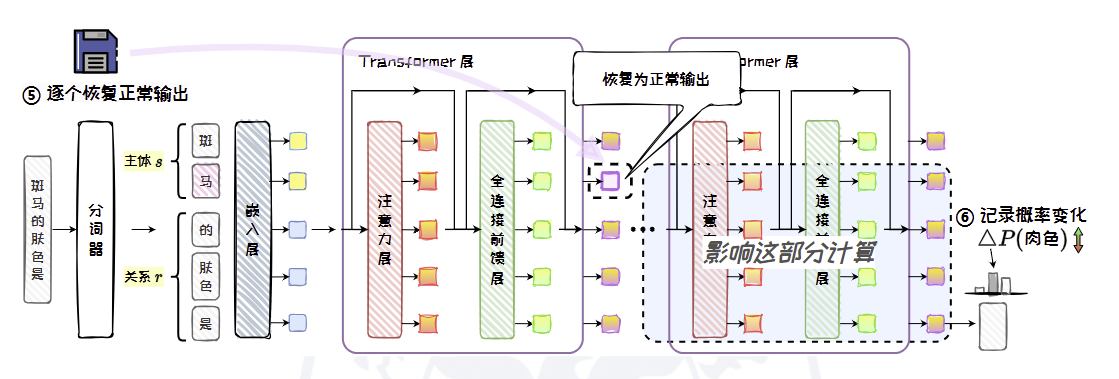
- 恢复推理:在干扰状态下,对于输入问题的每一个Token q(i),将q(i) 在每一层的输出向量分别独立地恢复为未受噪声干扰的“干净”状态,并进行推理。
以问题“斑马的肤色是”为例,其因果跟踪过程如下:
当输入问题“斑马的肤色是”时,模型会推理出答案“肉色”(假设该模型不知道正确答案是黑色)。此时,保存所有模块在正常推理过程中的输出:
然后,在嵌入层对s="斑马"的每个Token 的嵌入向量添加噪声,接着在噪声干扰下进行推理。此时,由于内部的输出状态被破坏,模型将不能推理出答案“肉色”。
最后,对"斑马的肤色是"的每个Token 在每一层的输出向量,分别独立地恢复为正常推理时的值,再次进行推理,记录结果中答案” 肉色” 的概率变化,作为该位置的因果效应强度。
实验结果揭示了一个新的发现:模型的中间层Transformer在处理s 的最后一个Token s(−1) (如示例中的“马”)时,表现出显著的因果效应。
在恢复某一层Transformer 处理s(−1) 的输出后,将后续的全连接前馈层(或注意力层)冻结为干扰状态,即隔离后续的全连接前馈层(或注意力层)计算,然后观察模型性能的下降程度。通过这种方法,能够明确全连接前馈层在模型性能中的关键作用。
比较阻断前后的因果效应,ROME 发现如果没有后续全连接前馈层的计算,中间层在处理s(−1) 时就会失去因果效应,而末尾层的因果效应几乎不受全连接前馈层缺失的影响。而在阻断注意力层时,模型各层处理s(−1) 时的因果效应只有较小的下降。
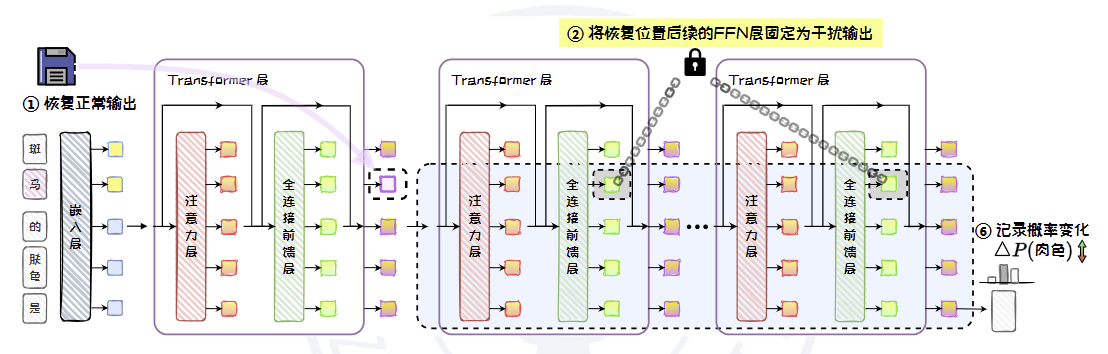
基于上述因果跟踪及阻断实验的结果,ROME 认为在大语言模型中,知识存储于模型的中间层,其关键参数位于全连接前馈层,而且特定中间层的全连接前馈层在处理主体的末尾Token时发生作用。
精准知识编辑
ROME 编辑方法主要包括三个步骤:
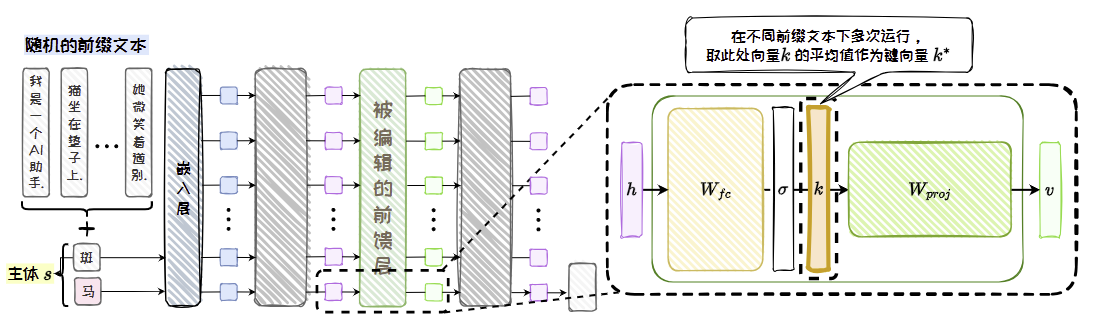
- 确定键向量;
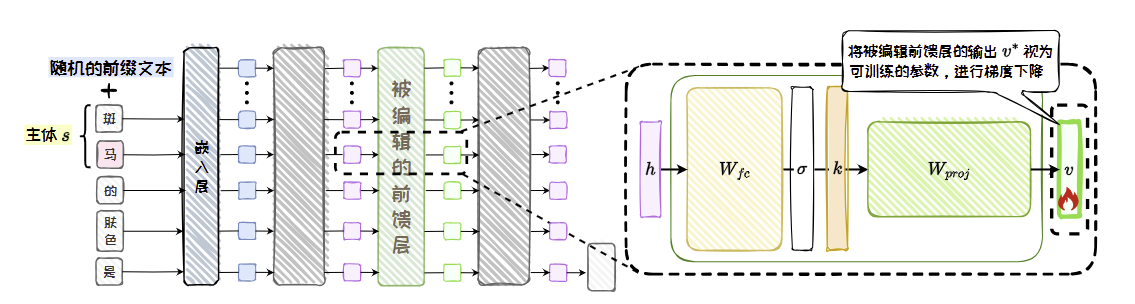
- 优化值向量;
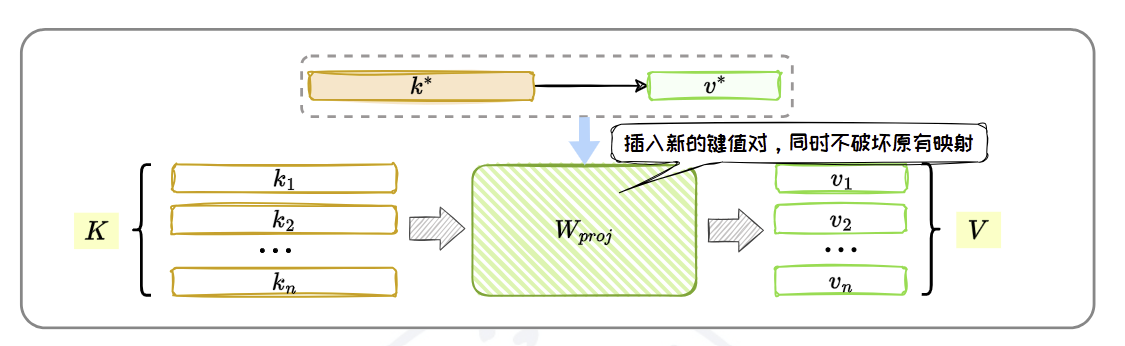
- 插入知识。
核心思想
ROME 基于一个关键的观察:在Transformer模型中,许多知识(特别是事实性知识)以“键值对”的形式存储在网络的前馈神经网络(FFN)层中。
- 键(Key):通常对应一个主题或实体(例如,“苹果公司的CEO”)。
- 值(Value):则对应这个主题的具体属性(例如,“蒂姆·库克”)。
ROME的目标是,在不影响模型其他能力的前提下,精准地替换或插入一个这样的“键值对”。
关键技术原理
定位关键层和神经元:首先,通过分析确定存储目标知识的特定FFN层。通常是在模型的中间层。
将编辑问题建模为最小二乘问题:ROME的核心创新在于,它将编辑任务形式化为一个数学优化问题:
- 目标:修改FFN层中的一个权重矩阵
W(通常是权重矩阵的某一行或某一列),使得对于给定的提示(例如:“苹果公司的CEO是”),模型的内部激活向量经过修改后的权重计算后,能直接输出我们想要的新答案(例如:“蒂姆·库克”)的表示。 - 约束:这个修改必须最小化对模型其他所有行为的干扰。也就是说,对于其他不相关的输入,模型的激活和输出应该几乎不变。
- 目标:修改FFN层中的一个权重矩阵
秩为一的更新:为了解决上述优化问题,ROME推导出,对权重矩阵
W的最优更新是一个秩为一的矩阵(即,这个更新矩阵可以由一个列向量和一个行向量相乘得到:ΔW = u v^T)。- 为什么是“Rank-One”:因为理论上,更新一个特定的“键值对”知识,只需要在一个非常低维(几乎是一维)的空间里调整权重。这使得更新极其高效和精准。
计算更新向量:通过解一个封闭形式的方程(基于最小二乘法),可以精确计算出更新向量
u和v,而无需迭代训练。这个计算过程很快。
ROME的工作流程
- 指定编辑内容:用户提供一个编辑描述,通常以三元组形式:
(主体,关系,新值)。例如:(苹果公司, CEO, 蒂姆·库克)。 - 生成上下文:方法会自动生成或使用一组关于该主体的标准提示(如“{主体}的CEO是”)。
- 定位与计算:模型在这些提示上运行,ROME算法定位关键层,并计算所需的秩一更新
ΔW。 - 应用更新:将
ΔW加到原始的权重矩阵W上,完成编辑:W_new = W_old + ΔW。
优势与特点
- 精确性:能够非常精准地改变模型对特定问题的回答。
- 高效性:只需修改极少数参数(一个秩一矩阵),速度快,计算成本低。
- 局部性:理想情况下,只影响与编辑主题直接相关的查询,对模型的其他知识干扰很小。
- 持久性:修改直接写入模型权重,是永久性的,不同于上下文学习那种临时性调整。