
语言模型基础 - 语言模型的评测
概述
得到一个语言模型后,需要对其生成能力进行评测,以判断其优劣。
评测语言模型生成能力的方法可以分为两类。
- 第一类方法不依赖具体任务,直接通过语言模型的输出来评测模型的生成能力,称之为内在评测(Intrinsic Evaluation)。
- 第二类方法通过某些具体任务,如机器翻译、摘要生成等,来评测语言模型处理这些具体生成任务的能力,称之为外在评测(Extrinsic Evaluation)。
内在评测
在内在评测中,测试文本通常由与预训练中所用的文本独立同分布的文本构成,不依赖于具体任务。最为常用的内部评测指标是困惑度(Perplexity)。其度量了语言模型对测试文本感到“困惑”的程度。
设测试文本为stest=w1:N 。语言模型在测试文本stest上的困惑度PPL可由下式计算:
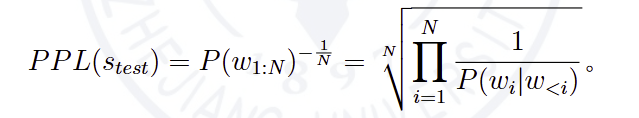
由上式可以看出,如果语言模型对测试文本越“肯定”(即生成测试文本的概率越高),则困惑度的值越小。而语言模型对测试文本越“不确定”(即生成测试文本的概率越低),则困惑度的值越大。
外在评测
在外在评测中,测试文本通常包括该任务上的问题和对应的标准答案,其依赖于具体任务。通过外在评测,可以评判语言模型处理特定任务的能力。外在评测方法通常可以分为基于统计指标的评测方法和基于语言模型的评测方法两类。
基于统计指标的评测
- 构造统计指标来评测语言模型的输出与标准答案间的契合程度,并以此作为评测语言模型生成能力的依据。
基于语言模型的评测
- 基于上下文词嵌入(Contex-tual Embeddings)的评测方法(BERTScore)
- BERTScore 在BERT 的上下文词嵌入向量的基础上,计算生成文本sgen 和参考文本sref 间的相似度来对生成样本进行评测。从精度(Precision),召回(Recall)和F1 量度三个方面对生成文档进行评测。
- 基于生成模型的评测方法(G-EVAL)
- 。G-EVAL 通过提示工程(Prompt Engineering)引导GPT-4 输出评测分数。
- 基于上下文词嵌入(Contex-tual Embeddings)的评测方法(BERTScore)