
序列到序列学习
参考文献
概念
在自然语言处理(NLP)领域,Seq2Seq(Sequence-to-Sequence)模型是一种强大的框架,专门用于处理输入和输出都是序列的任务。自从 2014 年由 Google 的研究团队提出以来,Seq2Seq 模型已经彻底改变了机器翻译、文本摘要、对话系统等多个 NLP 领域。
Seq2Seq 模型是一种端到端的深度学习框架,专门设计用于将一个序列(如句子)转换为另一个序列。它的核心思想是接受可变长度的输入序列,并生成可变长度的输出序列,这两个序列的长度可以不同。
典型应用场景
Seq2Seq 模型在以下任务中表现出色:
- 机器翻译:中文句子 → 英文中文句子
- 文本摘要:长文本 → 短摘要
- 对话系统:用户输入 → 系统回复
- 语音识别:音频序列 → 文字
- 代码生成:自然语言描述 → 程序代码
仔细观察,这些生成任务有两个鲜明的共同点:
- 输入和输出都是序列:无论是词、字还是更细粒度的子词,它们都以序列的形式存在。
- 序列长度是动态可变的:输入和输出的长度没有固定比例,一句中文翻译成英文,长度可能更长,也可能更短。
面对这种“可变长度序列”到“可变长度序列”的映射挑战,传统的模型架构显得有些力不从心。为此,研究者们提出了一个强大而优雅的解决方案——Seq2Seq(Sequence to Sequence,序列到序列)模型。
基本架构
Seq2Seq 模型由两大核心组件构成:
编码器(Encoder):它的角色如同一位“倾听者”或“阅读者”。它逐词“阅读”整个输入序列,吸收其全部信息,并将其整合、浓缩成一个固定长度的上下文向量。
- 这个向量可以看作是整个输入序列的“思想精华”或“语义摘要”,承载了生成目标序列所需的所有关键信息。
- 所有维度都参与编码,即使输入很短,整个向量也是“满的”(非零、有信息)。
解码器(Decoder):它的角色则像一位“创作者”或“讲述者”。解码器以编码器产出的上下文向量为起点,如同拥有了一个完整的故事蓝图,开始逐步地、一个字一个字地生成目标序列。
- 在生成的每一步,它都会参考已生成的部分,并不断回顾最初的“蓝图”,以确保输出的连贯性与准确性。
这种“编码-解码” 的模式,巧妙地解决了输入与输出序列长度可变、结构自由的难题。上下文向量成为了连接两个序列的“语义桥梁”,使得从一种语言到另一种语言、从长文到摘要、从问题到答案的智能生成成为可能。
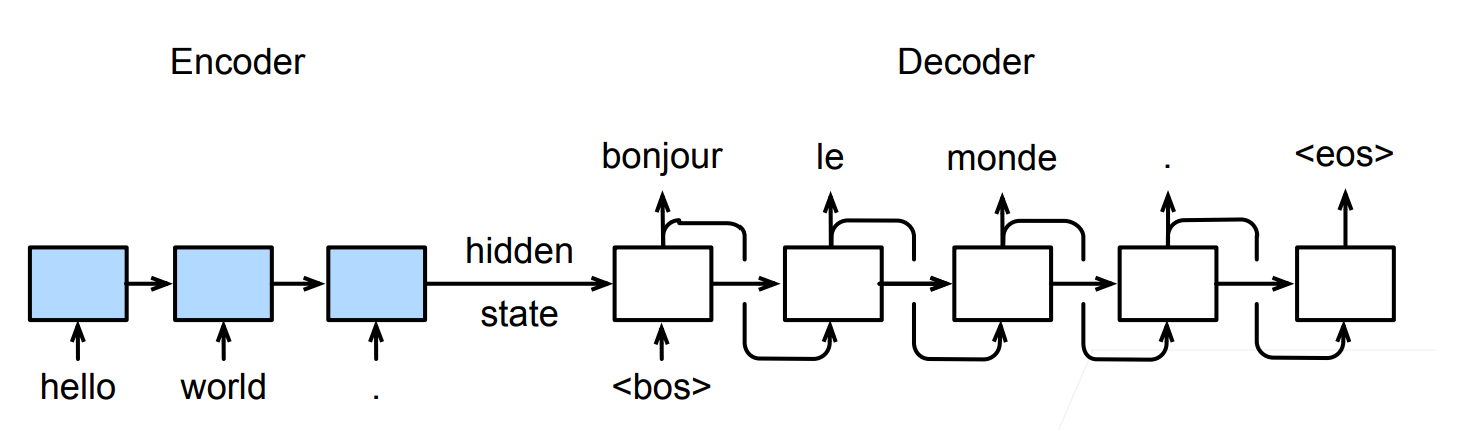
编码器
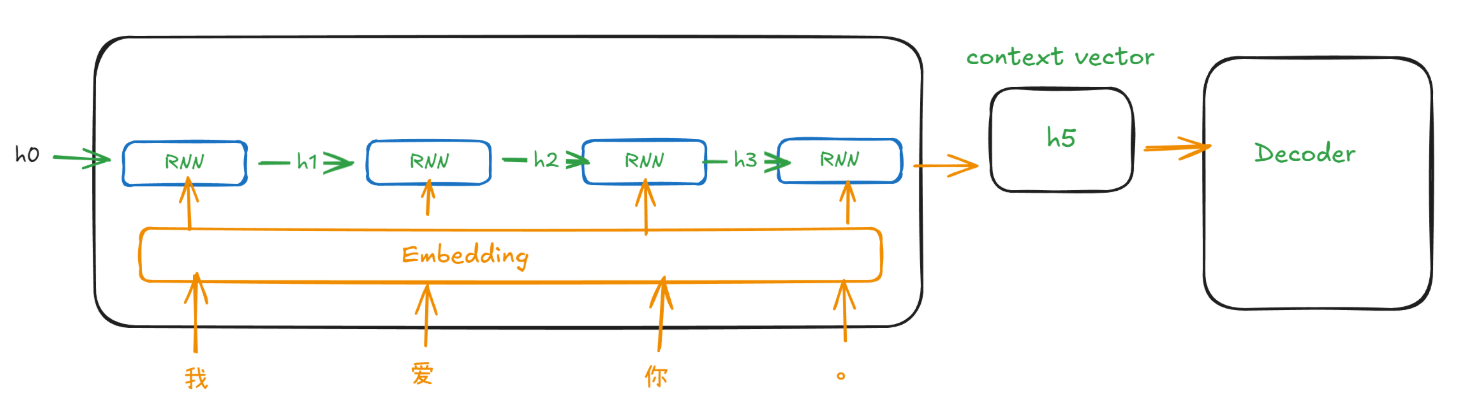
编码器通常由 RNN、LSTM 或 GRU 等序列模型构成,其任务是将输入语句的语义信息提取并压缩成一个上下文向量。
可以将其理解为一次有记忆的逐词阅读:
- 编码器从第一个词开始处理,生成初始的隐藏状态,代表“此刻的理解”。
- 每读入一个新词,就结合当前隐藏状态更新状态,如同滚雪球般累积之前的所有信息。
- 当读到句末时,最后的隐藏状态就包含了全句的语义精髓,我们将其作为上下文向量,传递给解码器作为生成的蓝图。
在模型处理输入序列时,循环神经网络会依次接收每个 token 的输入,并在每个时间步步更新隐藏状态。每个隐藏状态都携带了截止到当前位置为止的信息。随着序列推进,信息不断累积,最终会在最后一个时间步形成一个包含整句信息的隐藏状态。最后的隐藏状态就会作为上下文向量(context vector),传递给解码器,用于指导后续的序列生成。
解码器
解码器是模型的“创作者”。它同样基于 RNN 架构,其任务是基于编码器传来的上下文向量,逐步“写出”目标序列。
它的工作是一个典型的自回归生成过程:
- 启动:以上下文向量为初始状态,并接收起始符
<sos>作为首个输入。 - 生成:在每一步,它根据当前状态和上一步生成的词,预测下一个词,并将该词作为下一步的输入,如此循环,确保连贯。
- 结束:当模型生成结束符
<eos>时,整个过程停止。
在生成开始时,循环神经网络以上下文向量作为初始隐藏状态,并接收一个特殊的起始标记 <sos>(start of sentence)作为第一个时间步的输入,用于预测第一个 token。
随后,在每一个时间步,模型都会根据前一时刻的隐藏状态和上一步生成的 token,预测当前的输出。这种“将前一步的输出作为下一步输入”的方式被称为自回归生成(Autoregressive Generation),它确保了生成结果的连贯性。
编码器-解码器细节
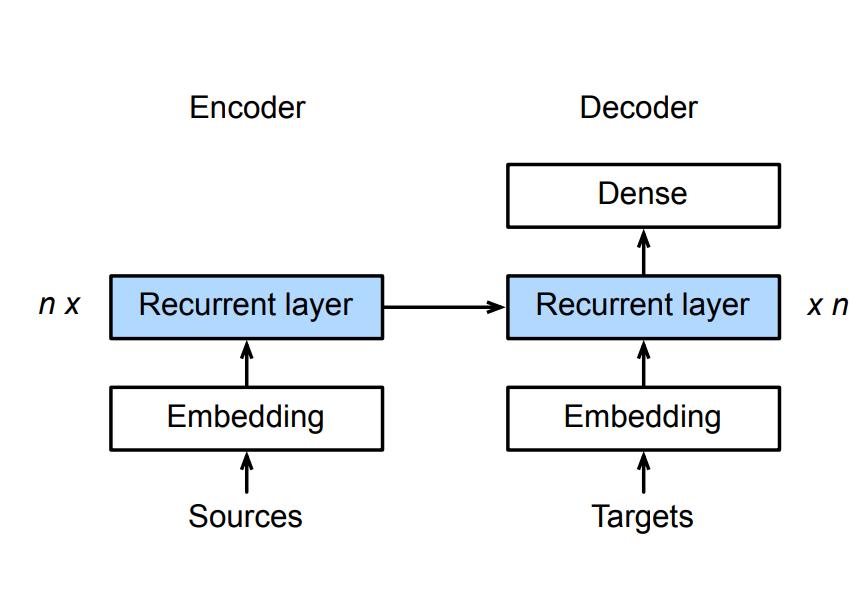
- 编码器是一个RNN,读取输入句子
- 可以是双向
- 解码器使用另外一个RNN来输出
- 编码器是没有输出蹭到RNN
- 编码器最后时间步的隐状态用作解码器的初始隐状态
模型训练机制
数据准备:为句子标定起止点
训练的第一步是为目标语句明确起点和终点。我们会在每个目标句(如英文句子)的开头添加一个特殊的 **<sos>(序列起始)** 标记,在句末添加 **<eos>(序列结束)** 标记。
例如:
- 原始句子:I like you.
- 训练格式:
<sos>I like you .<eos>
这两个标记是模型学会生成流程的“信号灯”:<sos>告诉解码器“从这里开始写”,<eos>则指示“在这里结束”。
前向传播:编码与解码的协作
训练时,数据会依次通过模型的两大部分:
- 编码器:它接收源语言序列(如:中文“我爱你”),通过词嵌入层和 RNN/LSTM,逐步将整句的语义压缩成一个上下文向量。这个向量是源句的**“思想摘要”**。
- 解码器:它的任务是根据这个“摘要”生成目标语句。
- 解码器以该上下文向量作为初始的“创作思路”(隐藏状态),并接收
<sos>作为第一个输入,开始预测序列。
- 解码器以该上下文向量作为初始的“创作思路”(隐藏状态),并接收
这里存在一个关键区别:训练策略(Teacher Forcing)与推理策略(自回归)不同。
- 推理时:模型采用自回归方式,即每一步的输入都是自己上一步的预测结果。这就像真实考试,必须独立作答。
- 训练时:为了加速收敛和稳定学习,常采用 Teacher Forcing 策略。即解码器每一步的输入,是真实目标序列中对应位置的前一个词(Ground Truth)。这就像有老师在一旁,每一步都提示你正确的上一个词是什么,让你能更快地学会整体的句子结构和对应关系。
训练时,解码器的生成是逐步进行的,因此每一步(每个时间步)我们都能计算一个损失值,衡量模型对当前词的预测精度。而整个句子的总损失,就是所有这些时间步的损失值之和。
通俗理解:这好比老师批改一篇由模型“逐词写就”的作文。老师不会只给最终分数,而是对每一个用词的对错都进行打分,最后将所有词的扣分(损失)累加起来,得到这篇“作文”的总扣分。模型的目标,就是在整个训练集上,最小化这个“总扣分”,从而学会用更准确的词汇,写出更流畅的句子。
通过这种“逐步计算,累加求和” 的损失计算方式,模型得以从每个词的细粒度反馈中学习,最终优化其从理解到生成的整体能力。
计算出总损失后,模型的“学习”才真正开始。我们需要告诉模型如何调整内部参数,才能在下次写得更好。这就是反向传播和优化的环节。
模型推理机制
训练完成后,Seq2Seq 模型便进入了它的“实战阶段”——推理。这一过程旨在利用已学习到的知识,为全新的输入序列动态生成相应的目标序列。
推理的核心流程如下:
- 编码器:信息的一次性封装
推理阶段编码器的处理流程与训练时完全一致:
- 输入序列经过分词、词嵌入等预处理。
- 然后由 RNN/LSTM/GRU 构成的编码器网络逐步处理序列,最终将整句的语义信息浓缩成一个固定长度的上下文向量。
- 最后这个向量被传递给解码器,作为其生成过程初始“语义蓝图”和隐藏状态。
此阶段编码器的工作是确定性的,仅执行一次,为后续的生成奠定基础。
- 解码器:自回归的创意之旅
推理的核心与魅力在于解码器的生成过程。它采用自回归生成方式,过程如下:
启动:解码器以编码器传来的上下文向量为初始状态,并接收起始标记
<sos> 作为第一个“起笔”信号。循环生成:在每一步,解码器根据当前隐藏状态和上一步生成的词,预测下一个词的概率分布。上一步生成的词会立即成为下一步的输入,如此循环往复。
终止:生成过程持续进行,直到模型输出结束标记
<eos> ,或达到预设的最大生成长度,标志着句子创作完成。
- 生成策略:如何在每一步做出“选择”?
在自回归的每一步,解码器输出的是一个覆盖整个词表的概率分布。如何从这个分布中选出一个具体的词,直接决定了生成结果的质量和风格。常见的选择策略主要有两种:
| 策略 | 机制 | 优点 | 缺点 |
|---|---|---|---|
| 贪心解码 | 每一步都无条件选择当前概率最高的词。 | 简单高效,计算速度快。 | 容易陷入局部最优,生成结果可能生硬、缺乏多样性,且一旦选错难以回头。 |
| 穷举搜索 | 试图遍历所有可能的序列组合,计算每一条完整序列的联合概率,最后选出概率最大的那一条。 | 如果算力无限且能遍历完,它一定能找到概率最高的完美序列。 | 计算成本大,不可行。 |
| 束搜索 | 每一步保留得分最高的 k 个候选序列(k 为束宽),在扩展中持续评估,最后选择总体得分最高的完整序列。 | 全局视野更优,生成质量通常更高、更流畅。 | 计算和内存开销较大,且 k 值越大,代价越高。 |
在实际应用中,贪心解码常用于对速度要求极高的场景或作为基线方法;而束搜索因其更好的生成质量,成为机器翻译等任务中的主流选择。
此外,还有采样(如 Top-k、Top-p 采样)等策略,常用于追求多样性和创造性的对话、故事生成等任务。
至此,一个完整的 Seq2Seq 模型完成了从理解输入到创造性输出的全过程。