
大语言模型架构 - Decoder-only
概述
通过自回归方法逐字生成文本,不仅保持了长文本的连贯性和内在一致性,而且在缺乏明确输入或者复杂输入的情况下,能够更自然、流畅地生成文本。
GPT系列模型
InstructGPT,其也是ChatGPT 的前身。它通过引入了人类反馈强化学习(Reinforcement Learning from Human Feedback, RLHF),显著提升了模型对用户指令的响应能力。
在人类反馈强化学习中,人类评估者首先提供关于模型输出质量的反馈,然后使用这些反馈来微调模型。
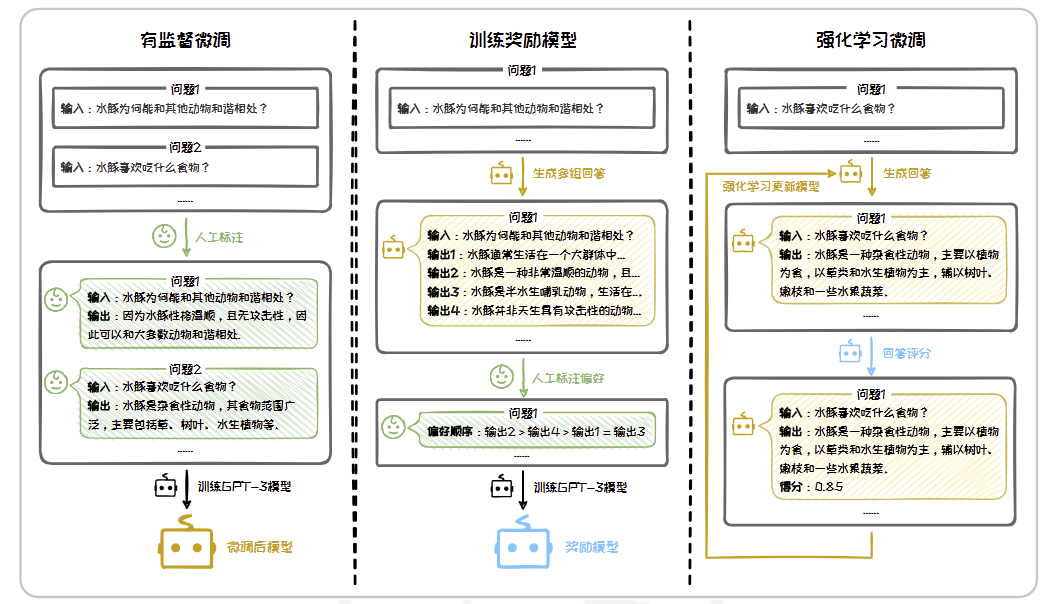
具体过程:
- 有监督微调:收集大量“问题-人类回答”对作为训练样本,对大语言模型进行微调。
- 训练奖励模型:针对每个输入,让模型生成多个候选输出,并由人工对其进行质量评估和排名,构成偏好数据集。用此偏好数据集训练一个奖励模型,使其可以对输出是否符合人类偏好进行打分。
- 强化学习微调:基于上一步中得到的奖励模型,使用强化学习方法优化第一步中的语言模型,即在语言模型生成输出后,奖励模型对其进行评分,强化学习算法根据这些评分调整模型参数,以提升高质量输出的概率。
LLAMA 系列语言模型
LLaMA(Large Language Model Meta AI)是由Meta AI 开发的一系列大语言模型,其模型权重在非商业许可证下向学术界开放,推动了大语言模型的“共创”和知识共享。
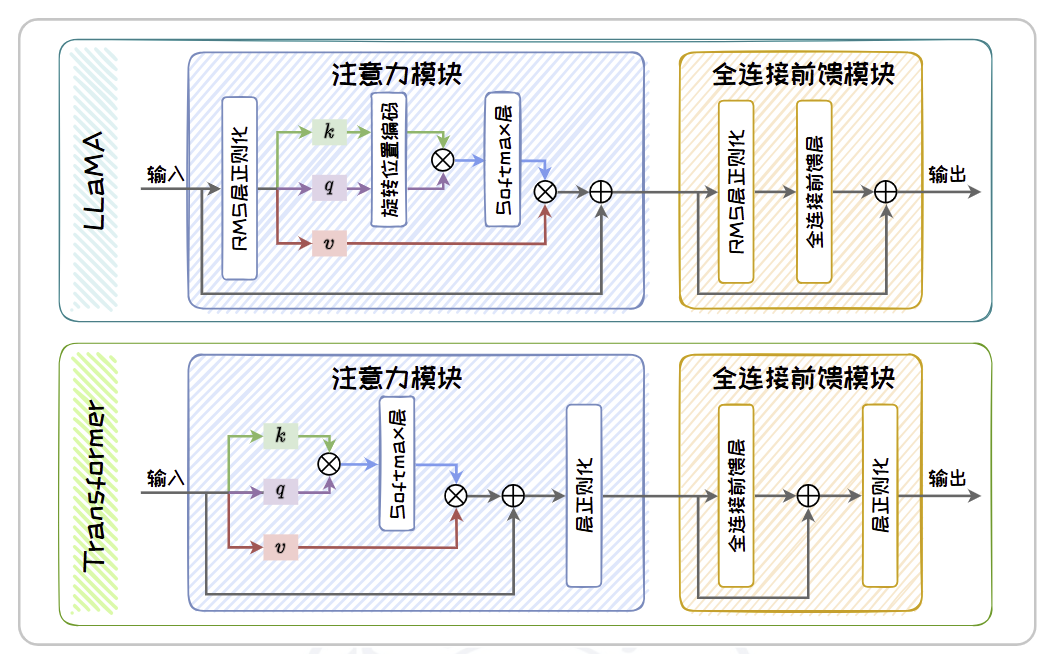
LLaMA 在Transformer 原始词嵌入模块、注意力模块和全连接前馈模块上进行了优化。在词嵌入模块上,为了提高词嵌入质量,LLaMA1 参考了GPTNeo的做法,使用**旋转位置编码(Rotary Positional Embeddings, RoPE)**替代了原有的绝对位置编码,从而增强位置编码的表达能力,增强了模型对序列顺序的理解。在注意力模块上,LLaMA1 参考了PaLM的做法,将Transformer 中的RELU 激活函数改为SwiGLU 激活函数。并且,LLaMA1 在进行自注意力操作之前对查询(query)以及键(key)添加旋转位置编码。在全连接前馈模块上,LLaMA1 借鉴了GPT-3中的Pre-Norm 层正则化策略,将正则化应用于自注意力和前馈网络的输入。