
SDD
参考文献
概念
SSD (Single Shot MultiBox Detector,单发多框检测器),是一种经典的单阶段(One-Stage)目标检测算法。它由 Wei Liu 等人在 2016 年提出,旨在解决传统两阶段算法(如 Faster R-CNN)速度慢、难以实时的痛点,同时保持较高的检测精度。
SSD 的核心思想是端到端:只需一次前向传播(Single Shot),即可直接从输入图像中预测出多个物体的类别和位置(多框,MultiBox)。
核心设计理念
SSD 结合了 YOLO 的回归思想(速度快)和 Faster R-CNN 的锚框(Anchor/Prior Box)机制(精度高),主要特点包括:
- 单阶段检测:不需要像 R-CNN 系列那样先生成候选区域(Region Proposals),而是直接在全图上密集采样预测。
- 多尺度特征图检测:这是 SSD 最关键的创新。它在卷积神经网络的不同层级(不同分辨率的特征图)上分别进行检测。
- 浅层特征图(分辨率高,即比较大的特征图):负责检测小物体。
- 深层特征图(分辨率低,即小的特征图,感受野大):负责检测大物体。
- 这种金字塔结构有效解决了单一特征图难以兼顾大小物体的问题。
采用了多尺度的特征图,其基本架构如图所示:
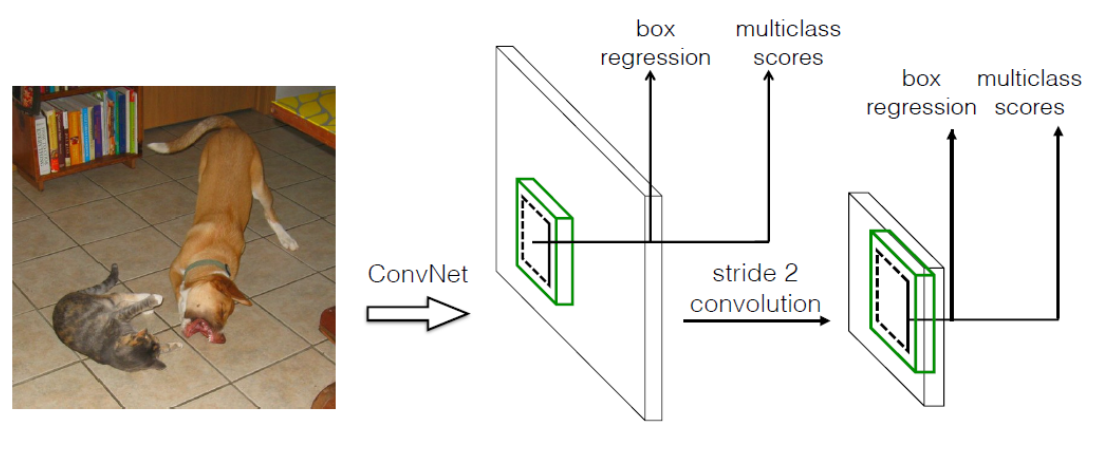
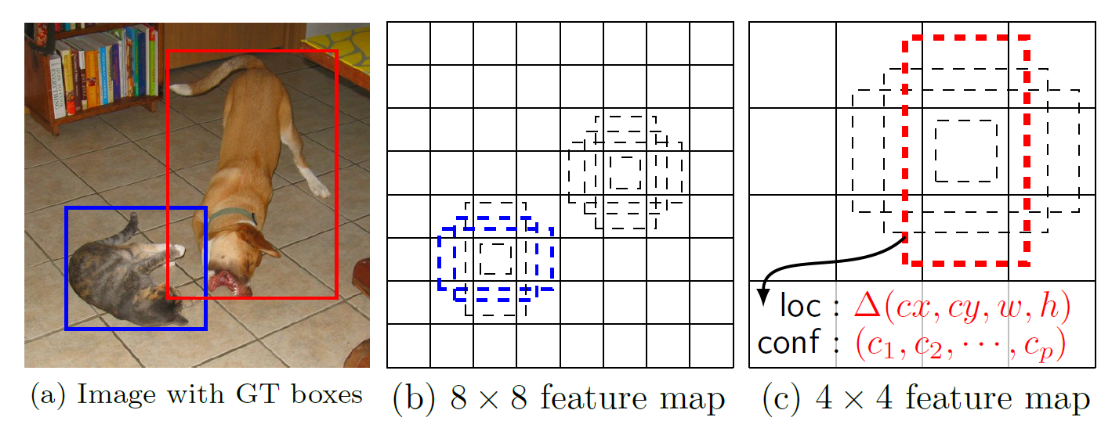
设置先验框:借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
- 如图所示,可以看到每个单元使用了4个不同的先验框,图片中猫和狗分别采用最适合它们形状的先验框来进行训练。
网络架构组成
典型的 SSD 模型(如 SSD300 或 SSD512)通常包含以下部分:
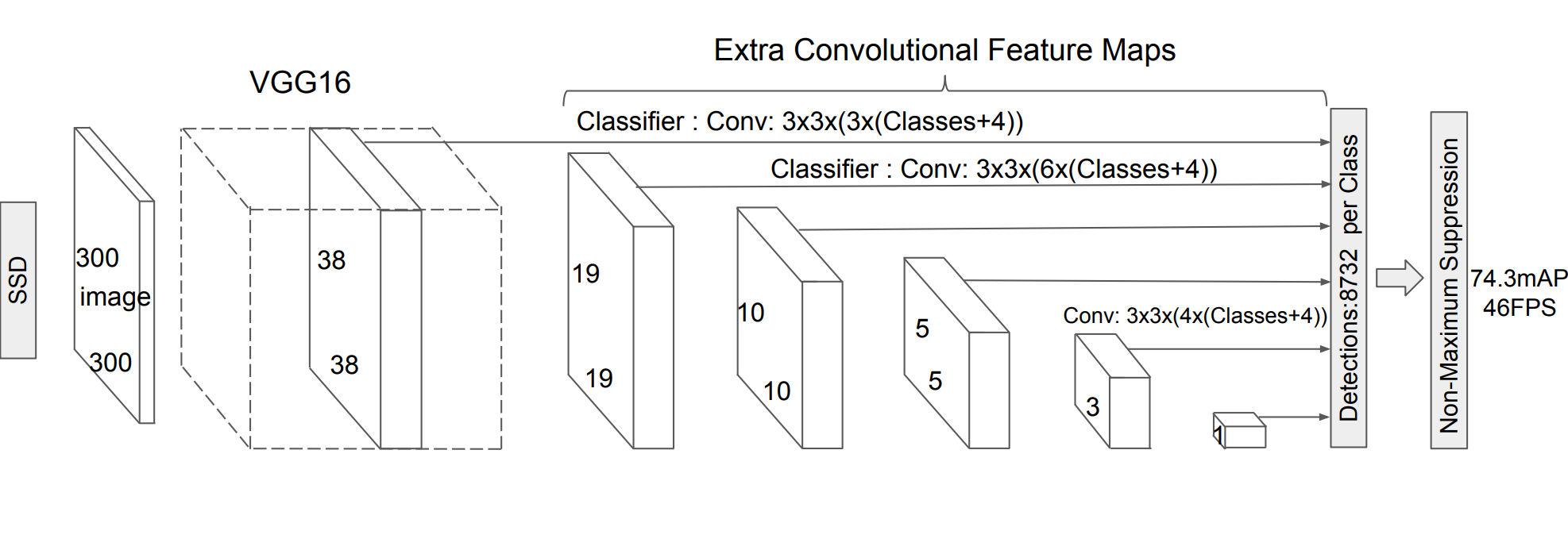
基础网络 (Base Network):
- 通常使用预训练的 VGG16作为骨干,用于提取图像特征。
- 修改点:将 VGG16 原有的全连接层(fc6, fc7)转换为卷积层,以保留空间信息并适应任意尺寸输入。
辅助特征层 (Auxiliary Feature Layers):
- 在基础网络后添加一系列逐渐减小的卷积层。
- 这些层生成的特征图尺寸依次递减(例如:38×38, 19×19, 10×10, 5×5, 3×3, 1×1),构成了特征金字塔。
预测头 (Prediction Heads):
- 对于每一个特征图上的每个像素点,都会预设一组默认框(Default Boxes / Prior Boxes)。
- 每个默认框对应两个预测输出:
- 类别分数 (Class Scores):预测该框内属于各个类别的概率(包括背景类)。
- 边界框偏移 (Offset):预测相对于默认框的中心点坐标和长宽的修正值。
关键工作机制
默认框 (Default Boxes / Anchors)
- 在每个特征图的每个单元格(cell)上,生成多个不同尺度 (Scale) 和 宽高比 (Aspect Ratio) 的默认框。
- 例如,在 38×38 的特征图上,每个点可能生成 4 个或 6 个不同形状的框。
- 随着特征图层级的加深,默认框的基准尺寸逐渐变大,以匹配不同大小的目标。
训练过程
- 正负样本匹配:计算默认框与真实标签框(Ground Truth)的 IoU(交并比)。IoU 超过阈值(如 0.5)的视为正样本,其余大部分视为负样本(背景)。
- 难例挖掘 (Hard Negative Mining):由于背景框(负样本)数量远多于目标框(正样本),会导致类别不平衡。SSD 在训练时只选取损失最大的那些负样本参与反向传播,使正负样本比例保持在约 1:3。
- 损失函数:总损失 = 定位损失 (Localization Loss) + 置信度损失 (Confidence Loss)。
- 定位损失通常使用 Smooth L1 Loss 回归坐标偏移。
- 置信度损失通常使用 Softmax Loss 进行分类。
预测过程
- 输入图像经过网络,得到所有默认框的类别分数和位置偏移。
- 利用偏移量修正默认框的位置。
- 非极大值抑制 (NMS, Non-Maximum Suppression):
- 剔除置信度低于阈值的框。
- 对于同一类物体,如果多个框重叠严重(IoU 高),只保留置信度最高的一个,去除冗余检测框。
- 输出最终的检测结果。
优缺点分析
优点:
- 速度快:单阶段结构,无候选区域生成步骤,适合实时应用(如视频流检测)。
- 精度较高:多尺度特征图策略显著提升了对小目标的检测能力,优于早期的 YOLO v1/v2。
- 易于部署:结构简单,全卷积网络,便于在各种硬件上优化。 |
缺点:
- 小目标检测仍有局限:虽然比 YOLO v1 好,但在极小目标上仍不如两阶段算法(如 FPN+Faster R-CNN)。
- 默认框依赖:性能高度依赖于默认框的尺寸和比例设置,需要针对特定数据集进行调整。 |
应用场景
由于其高效的特性,SSD 广泛应用于对实时性要求较高的场景:
- 自动驾驶:实时检测行人、车辆、交通标志。
- 智能安防:视频监控中的人脸检测、异常行为识别。
- 移动端应用:配合 MobileNet 等轻量骨干网络,可在手机、嵌入式设备上运行(如 MobileNet-SSD)。
- 无人机导航:快速识别障碍物。
总结
SSD 是目标检测发展史上的里程碑式算法。它成功地在速度和精度之间找到了一个优秀的平衡点,其多尺度特征图检测的思想也被后续许多先进算法(如 RetinaNet, YOLO v3+, EfficientDet)所继承和发扬。