
YOLO
参考文献
概念
YOLO (You Only Look Once) 是目前世界上最流行、应用最广泛的单阶段(One-Stage)实时目标检测算法系列。
与 SSD 类似,YOLO 也将目标检测任务重构为一个单一的回归问题,直接从图像像素到边界框坐标和类别概率。但 YOLO 系列以其极致的速度和不断进化的精度著称,尤其是从 v3 版本开始,它成为了工业界和学术界的首选基准模型之一。
演变与里程碑
早期奠基 (v1 - v2)
- YOLO v1 (2016):开山之作。速度极快,但定位精度较差,尤其是对小物体和密集物体的检测效果不佳。它将图像分为 7×7网格,每个网格只预测 2 个框。
- YOLO v2 (YOLO9000, 2017):引入了锚框 (Anchor Boxes) 机制(借鉴 Faster R-CNN),使用了更深的网络结构(Darknet-19),并提出了多尺度训练。Batch Normalization 的加入显著提升了收敛速度和精度。
成熟与爆发 (v3 - v5)
- YOLO v3 (2018):里程碑版本。
- 骨干网络:使用 Darknet-53(引入残差连接)。
- 多尺度预测:借鉴 SSD 和 FPN 思想,在三个不同尺度的特征图上进行预测,极大地提升了对小物体的检测能力。
- 分类器:将 Softmax 改为独立的 Logistic 分类器,支持多标签分类(一个物体属于多个类别)。
- YOLO v4 (2020):集大成者。没有改变主干架构,而是系统性地整合了各种“技巧”(Bag of Freebies & Bag of Specials),如 Mosaic 数据增强、CmBN、SAM (Spatial Attention Module)、CIoU Loss 等,在速度和精度上全面超越 v3。
- YOLO v5 (2020):由 Ultralytics 公司发布(非原作者 Joseph Redmon)。
- 工程化极致:首次将模型部署变得极其简单,支持 PyTorch 原生,内置自动锚框计算、超参数进化等。
- 结构创新:引入了 Focus 结构(后期被替换)、CSPNet (Cross Stage Partial Network) 来减少计算量并增强梯度传播。
- 虽然学术创新性有争议,但其易用性和生态完善度使其成为工业界落地最快的版本。
现代革新 (v6 - v10+)
- YOLO v6 / v7 / v8:
- YOLO v8 (2023):Ultralytics 推出。最大的变化是Anchor-Free(无锚框)设计,简化了模型结构;解耦头(Decoupled Head)分离分类和回归任务;引入了新的损失函数。目前是最主流的通用版本。
- YOLO v9 (2024):提出了可编程梯度信息 (PGI) 和 辅助可逆分支 (GELAN),旨在解决深度网络中的信息瓶颈问题。
- YOLO v10 (2024):清华大学团队提出。主打无NMS训练 (NMS-Free Training),通过一致性双重分配策略,彻底消除了推理阶段的非极大值抑制(NMS)延迟,进一步提升了实时性。
网络架构
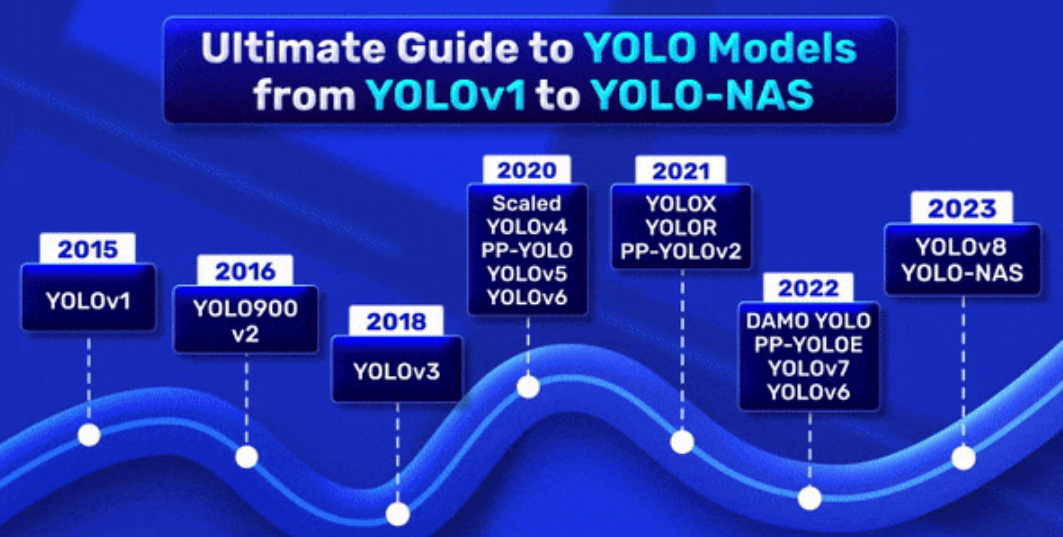
YOLO的核心架构是一个卷积神经网络(CNN),通常包括多层卷积、池化和全连接层。YOLOv1使用了一个简单的卷积网络,而后续版本(如YOLOv3、YOLOv4)则引入了更复杂的特征提取器(如Darknet-53、CSPNet)以提高检测精度。YOLOv1的架构如下:
单阶段模型遵循特定的设计模式,即“骨干-颈部-头部”。然而,YOLOv1 中没有“颈部”的概念,只有骨干和头部。YOLOv1 的架构灵感来源于 GoogleNet,包含 24 个卷积层和两个全连接层。其中,前 20 个卷积层构成骨干,其余层连接到另外两个全连接层,作为检测头部。YOLOv1 没有使用 Inception 模块,而是在骨干中使用了一个 1×1 卷积层和 3×3 卷积层。这有助于在不降低空间维度的情况下减少通道数,从而显著降低参数数量。
工作原理
YOLO的工作原理基于将目标检测任务转化为一个回归问题。具体来说:
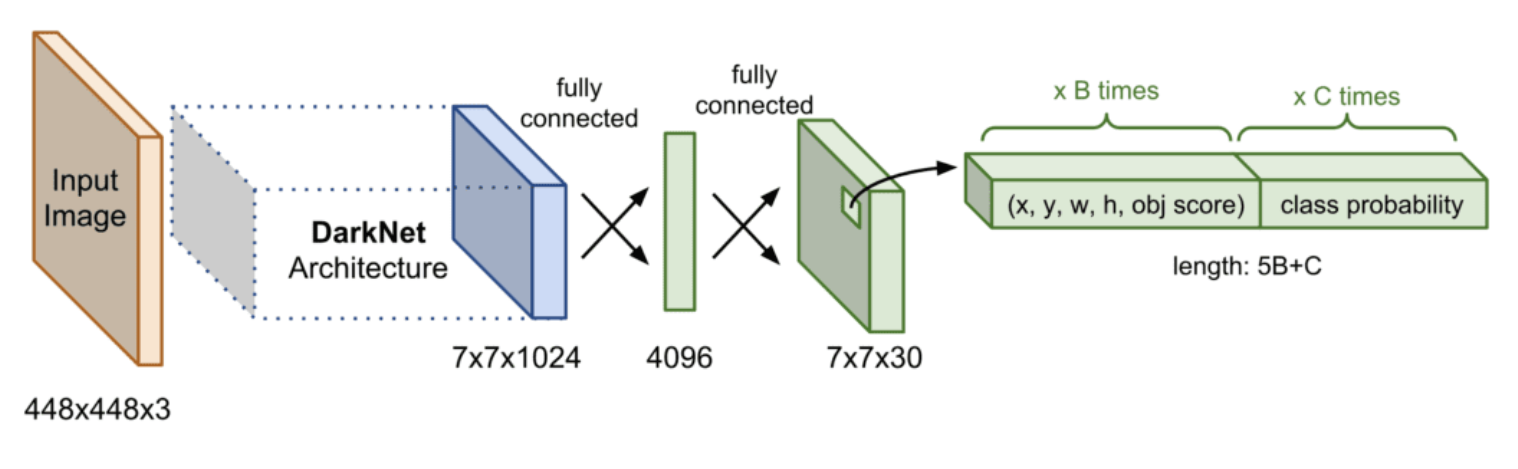
- YOLO模型将输入图像划分为S×S的网格,每个网格预测 (B) 个边界框坐标和与边界框相关的目标概率(objectness score),以及 (C) 个类别概率。(预测结果被编码为一个 S x S x ( B x 5 + C) 的张量。这也意味着每个网格单元只能预测一个物体。)
- 模型的输出是一系列边界框、类别标签以及对应的置信度分数。
- YOLO通过一次性处理整个图像,生成所有目标的检测结果,这种方法显著提高了检测速度。
对于边界框坐标,YOLO 预测边界框的中心 ((x, y)) 以及宽度 (w) 和高度 (h)。中心坐标相对于网格单元,因此范围在 0 到 1 之间;宽度和高度相对于图像尺寸,也在 0 到 1 之间。目标概率(objectness score)表示边界框内是否包含物体,其计算公式为:
公式说明:
- :该网格单元包含物体的概率。
- :预测框与真实框的交并比(Intersection over Union, IoU)。
由于检测头需要预测边界框坐标、目标概率(objectness score)以及物体类别,因此 YOLOv1 的损失函数分为三个部分:定位损失(localization loss)、置信度损失(confidence loss)和分类损失(classification loss)。