
深度学习之残差神经网络(ResNet)
参考文章
概念
ResNet,其全称为Residual Network(残差网络),是一种深度学习的网络结构,由微软研究院的何凯明等人于2015年提出。ResNet最大的创新在于引入了“残差模块”(Residual Block),有效地解决了深度神经网络训练中的梯度消失和表示瓶颈问题,使得网络的层数可以达到前所未有的深度,如1000层以上。
为什么需要 ResNet?
在 ResNet 出现之前,深度学习领域有一个直觉性的共识:网络越深(层数越多),性能应该越好。因为更深的网络可以学习到更复杂、更抽象的特征。
然而,实验发现,当网络深度增加到一定程度(例如超过 20 层)后,会面临两个主要问题:
- 梯度消失/爆炸:在反向传播过程中,梯度会随着层数的增加而指数级地减小或增大,导致浅层的网络权重无法有效更新。
- 注意:这个问题很大程度上可以通过**归一化初始化(如 Xavier 初始化)和归一化层(如 Batch Normalization)**来缓解。
- 网络退化:这是 ResNet 要解决的核心问题。即使在梯度问题被解决后,实验发现,更深的网络在训练集和测试集上的表现反而都比更浅的网络要差。 这不仅仅是过拟合,因为它在训练集上的误差也更高了。
- “网络退化” 现象表明:更深的网络并没有更容易地学习到“恒等映射”(即输出等于输入),而恒等映射对于一个深层网络来说,至少应该能做到和浅层网络一样好。
实验现象:
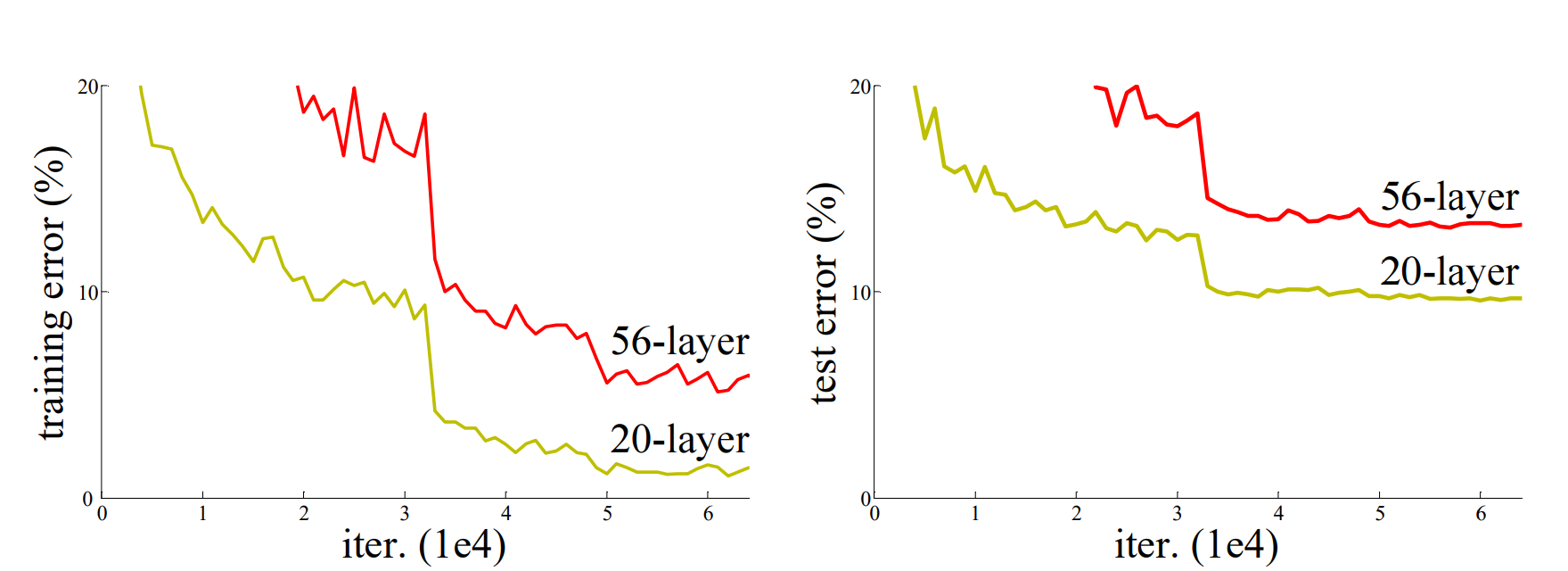
图 1. CIFAR-10 数据集上的训练误差(左)和测试误差(右)分别使用 20 层和 56 层“普通”网络。更深的网络具有更高的训练误差,因此也具有更高的测试误差。
对于以上问题而言,除了十分棘手的梯度消失/梯度爆炸,以及过拟合的问题之外,一个十分严峻的挑战在于负优化问题(degradation)。也就是说,56层的神经网络相比于20层,新增加的36层是对神经网络的“恶化”,它们非但没有起到自己应有的作用,反而扭曲了网络空间,升高了training error。
由此一个想法自然而然的产生:如果这36层神经网络是恒等映射(identity mapping),那么56层的神经网络不就和20层的一样好了吗?
更进一步呢?如果这36层神经网络相比于恒等映射再好上那么一点点(更接近最优函数),那么不就起到了正优化的作用了吗?ResNet的insight由此诞生。
核心思想:捷径连接
ResNet 的作者何恺明等人提出了一个革命性的想法:既然直接让网络学习一个复杂的映射 H(x)很困难,那么我们不如让它学习这个映射与输入 x 之间的“残差”。
他们重新定义了网络需要学习的目标。假设期望的底层映射为(H(x)),我们让堆叠的非线性层去拟合另一个映射:
那么,原始的映射就被转换为了:
如下图所示:
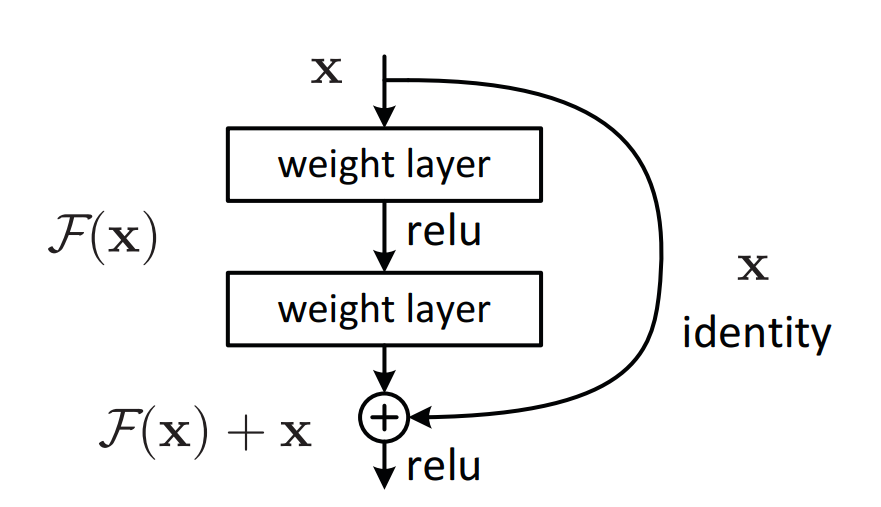
这个 “+ x” 的操作就是捷径连接,也叫跳跃连接。它直接将输入 x“抄近道”跳过了若干层(在 ResNet 中通常是 2 层或 3 层),与这些层的输出 ( F( x ) ) 进行逐元素相加。
由此可见,我们所需要的函数由两部分组成:恒等函数和残差函数。恒等函数的存在,避免了“负优化”问题,而残差函数则起到了“锦上添花”的作用。
残差块的结构
ResNet是由多个残差块 堆叠而成的。最基本的残差块(针对ResNet-34及更浅的模型)结构如下:
1、数据流过两个卷积层(通常伴有Batch Normalization 和 ReLU 激活函数)。
2、同时,输入x通过一条捷径直接跳接到第二个卷积层之后。
3、将捷径传来的x与卷积层的输出 ( F( x ) ) 进行逐元素相加。
4、将相加后的结果再通过一个ReLU激活函数输出。
对应到神经网络中,残差块的数学表达式可以写成:
当输入和输出的维度不一致时(例如,下采样时特征图尺寸减半、通道数翻倍),捷径连接需要执行一个线性投影来匹配维度。此时,捷径部分会通过一个1x1的卷积核W'进行运算:
经典的ResNet架构
ResNet论文提出了几种不同深度的版本,如ResNet-18, ResNet-34, ResNet-50, ResNet-101, ResNet-152。其中的数字代表的是带权重的层数。
1、ResNet-34及以下:使用基本残差块(两个3x3卷积层)。
2、ResNet-50及以上:使用瓶颈残差块,结构为1x1 -> 3x3 -> 1x1。
第一个1x1卷积用于降维,减少计算量。
第二个1x1卷积用于升维,恢复通道数。
这种设计在保持甚至提升性能的同时,大幅减少了参数和计算量。
所有版本都遵循类似的设计模式:开始时是一个普通的卷积和池化层,然后是4个阶段(每个阶段由多个残差块组成),每个阶段结束后特征图空间尺寸减半、通道数翻倍,最后是一个全局平均池化层和一个全连接层用于分类。