
语言模型基础 - 语言模型的采样方法
概述
语言模型的输出为一个向量,该向量的每一维代表着词典中对应词的概率。在采用自回归范式的文本生成任务中,语言模型将依次生成一组向量并将其解码为文本。将这组向量解码为文本的过程被成为语言模型解码。解码过程显著影响着生成文本的质量。当前,两类主流的解码方法可以总结为(1). 概率最大化方法; (2).随机采样方法
概率最大化方法

基于概率最大化的解码方法旨在最大化P (wN+1:N+M ),以生成出可能性最高的文本。该问题的搜索空间大小为M^D,是NP-Hard问题。
贪心搜索
贪心搜索在在每轮预测中都选择概率最大的词,即
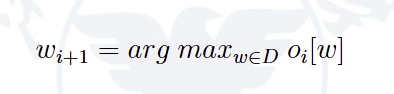
贪心搜索只顾“眼前利益”,忽略了“远期效益”。当前概率大的词有可能导致后续的词概率都很小。贪心搜索容易陷入局部最优,难以达到全局最优解。
波束搜索(Beam Search)


贪心搜索与波束搜索的对比
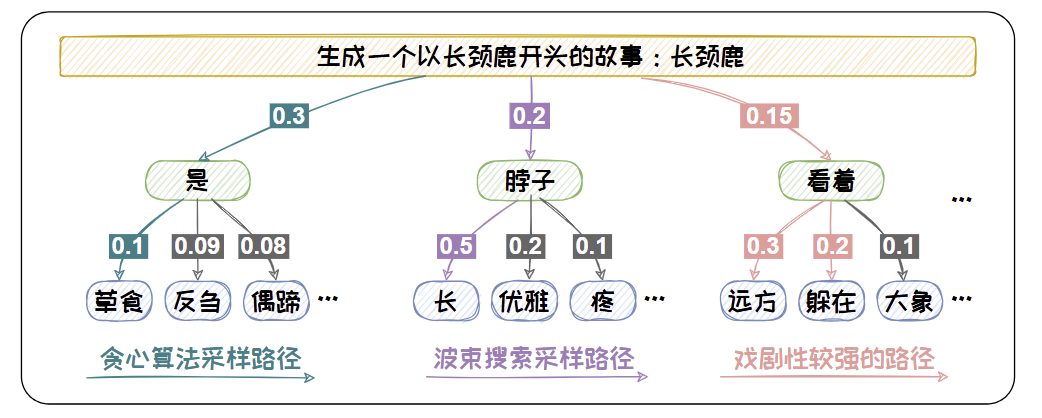
但是,概率最大的文本通常是最为常见的文本。这些文本会略显平庸。在开放式文本生成中,无论是贪心搜索还是波束搜索都容易生成一些“废话文学”—重复且平庸的文本。
为了提升生成文本的新颖度,可以在解码过程中加入一些随机元素。这样的话就可以解码到一些不常见的组合,从而使得生成的文本更具创意,更适合开放式文本任务。
随机采样方法
为了增加生成文本的多样性,随机采样的方法在预测时增加了随机性。
Top-K 采样

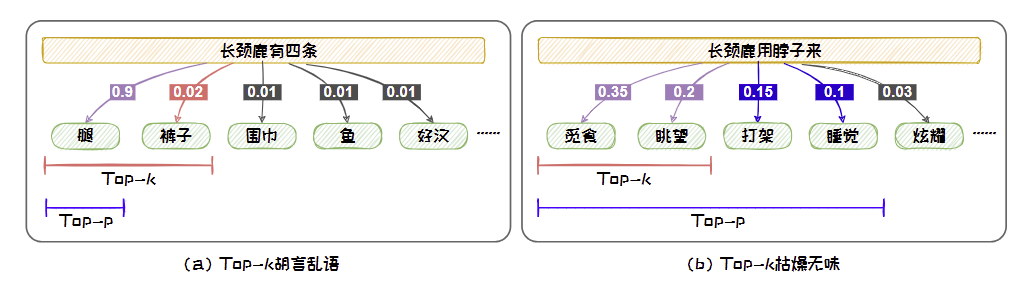
Top-K 采样可以有效的增加生成文本的新颖度。但是,将候选集设置为固定的大小K将导致上述分布在不同轮次的预测中存在很大差异。
- 当候选词的分布的方差较大的时候,可能会导致本轮预测选到概率较小、不符合常理的词,从而产生“胡言乱语”。
- 当候选词的分布的方差较小的时候,甚至趋于均匀分布时,固定尺寸的候选集中无法容纳更多的具有相近概率的词,导致候选集不够丰富,从而导致所选词缺乏新颖性而产生“枯燥无趣”的文本。
优点:
- 生成结果更稳定,避免荒谬或不合理的词语
- 计算效率高,易于理解和实现
- 适合需要一致性输出的场景,如问答、摘要生成
缺点:
- 若 K 值过小,可能遗漏合理但概率略低的词,导致输出单调
- 若 K 值过大,随机性增强,但可能降低文本质量
Top-P 采样
Top-P 是根据概率累积值动态选择词。它设定一个概率阈值 P(如 0.9),然后从概率最高的词开始累加,直到总和达到 P,仅保留这些词进行采样。

应用阈值作为候选集选取的标准之后,Top-P 采样可以避免选到概率较小、不符合常理的词,从而减少“胡言乱语”。并且,其还可以容纳更多的具有相近概率的词,增加文本的丰富度,改善“枯燥无趣”。
优点:
- 更灵活,能适应不同分布的输出,避免固定数量带来的局限
- 在低概率词较多时仍能保留合理选项,提升多样性
- 实践中常比 Top-K 表现更优
缺点:
- 选择的词数量不固定,难以预测
- 对 P 值敏感,需精细调参
Temperature 机制
引入Temperature 机制可以对解码随机性进行调节。Temperature 机制通过对Softmax函数中的自变量进行尺度变换,然后利用 Softmax 函数的非线性实现对分布的控制。设Temperature 尺度变换的变量为T。

温度控制整个概率分布的“平滑度”。高温度(如 1.0 以上)会使概率分布变平,让原本低概率的词也有机会被选中,从而提升创造性;低温度(如 0.1 以下)则使概率分布更尖锐,高概率词被优先选择,输出更确定、更保守。
优点:
- 简单直观,调节全局随机性
- 适用于需要风格控制的场景,如写诗、创意写作
缺点:
- 过高温度可能导致逻辑混乱、语法错误
- 过低温度则使输出机械、缺乏变化
总结
- Top-K 适合控制范围,提升稳定性
- Top-P 更智能,动态适应分布
- Temperature 调节整体风格,影响生成的“自由度”
在实际应用中,常将三者结合使用,如 Top-K + Top-P + Temperature,以在可控性与创造性之间找到最佳平衡。