
大语言模型架构 - 非Transformer 架构
概述
Transformer 结构是当前大语言模型的主流模型架构,其具备构建灵活、易并行、易扩展等优势。但是,Transformer 也并非完美。其并行输入的机制会导致模型规模随输入序列长度平方增长,导致其在处理长序列时面临计算瓶颈。
为了提高计算效率和性能,解决Transformer 在长序列处理中的瓶颈问题,可以选择基于RNN的语言模型。RNN 在生成输出时,只考虑之前的隐藏状态和当前输入,理论上可以处理无限长的序列。然而,传统的RNN 模型(如GRU、LSTM 等)在处理长序列时可能难以捕捉到长期依赖关系,且面临着梯度消失或爆炸问题。为了克服这些问题,近年来,研究者提出了两类现代RNN 变体,分别为状态空间模型(StateSpace Model,SSM)和测试时训练(Test-Time Training,TTT)
状态空间模型SSM
SSM 的思想源自于控制理论中的动力系统。其通过利用一组状态变量来捕捉系统状态随时间的连续变化,这种连续时间的表示方法天然地适用于描述长时间范围内的依赖关系。
RWKW
RWKV(Receptance Weighted Key Value)是一种结合了循环神经网络(RNN)和Transformer优点的新型语言模型架构。它最初由彭博(BlinkDL)等人提出,旨在解决传统Transformer在长序列处理中计算和内存开销大的问题,同时保留其强大的建模能力。
RWKV架构:
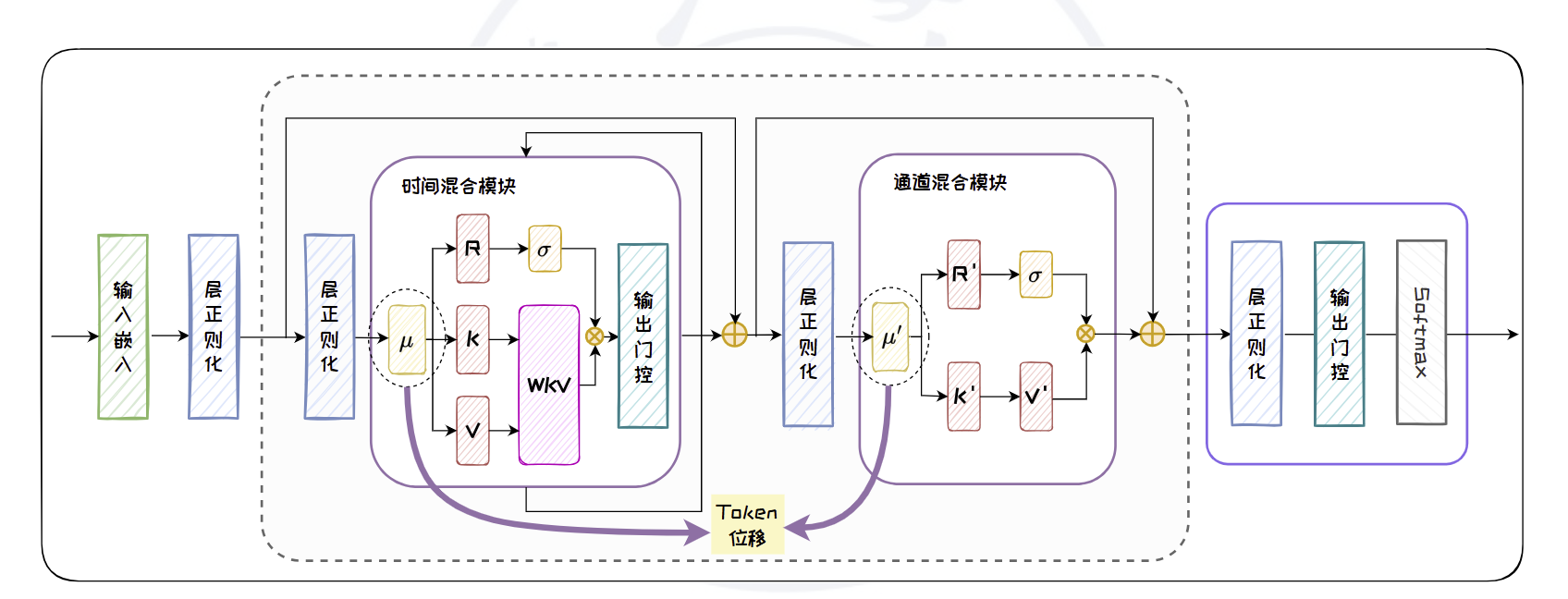
核心思想
RWKV 的关键创新在于:
- 将注意力机制重写为一种可递归的形式,从而实现线性时间复杂度(O(N))和常数级内存占用(推理时),类似于 RNN;
- 同时,在训练阶段仍可以像 Transformer 一样并行处理整个序列(利用时间混合和通道混合机制);
- 使用“Receptance”、“Key”、“Value”等门控机制来动态控制信息流,类似注意力中的 query-key-value,但以更高效的方式实现。
主要组件
RWKV 模型由多个 RWKV Block 堆叠而成,每个 block 包含两个核心子模块:
- Time Mixing(时间混合):
- 利用当前 token 和前一个 token 的信息进行插值(通过 learnable 的 time-mixing 参数)。
- 类似于 RNN 中的状态传递,但可并行训练。
- 引入 “receptance”(r)、“key”(k)、“value”(v)三个向量:
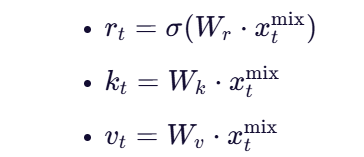
- Channel Mixing(通道混合):
- 类似于前馈网络(FFN),但同样引入时间维度上的状态缓存,提升效率。
其中,状态更新公式(简化版)为:

这样就避免了显式计算所有历史 token 对之间的注意力权重。
优势
- ✅ 训练可并行:像 Transformer 一样支持全序列并行训练;
- ✅ 推理高效:状态可递归更新,内存占用恒定,适合部署;
- ✅ 支持超长上下文:理论上可处理无限长序列(实践中已支持数百万 token);
- ✅ 开源生态活跃:有 Hugging Face 集成、GGUF 量化、本地运行工具(如 rwkv.cpp)等。
应用与变体
- RWKV-4 / RWKV-5 / RWKV-6:不断迭代改进,增加多头机制、更好的位置编码等;
- World Models:用于强化学习中的环境建模;
- 多模态扩展:如 RWKV-Vision;
- 本地大模型:因推理轻量,适合在 CPU 或手机上运行。
与 Transformer 对比
| 特性 | Transformer | RWKV |
|---|---|---|
| 时间复杂度(推理) | O(N²) | O(N) |
| 内存占用(推理) | O(N) | O(1)(仅需保存状态) |
| 并行训练 | 是 | 是 |
| 长程依赖建模 | 依赖位置编码/窗口 | 天然支持(RNN式状态) |
| 硬件友好性 | 需 GPU | CPU 友好 |
Mamba
Mamba基于SSM 架构,提出了选择机制(Selection Mechanism)和硬件感知算法(Hardware-aware Algorithm),前者使模型执行基于内容的推理,后者实现了在GPU上的高效计算,从而同时保证了快速训练和推理、高质量数据生成以及长序列处理能力。
Mamba架构:
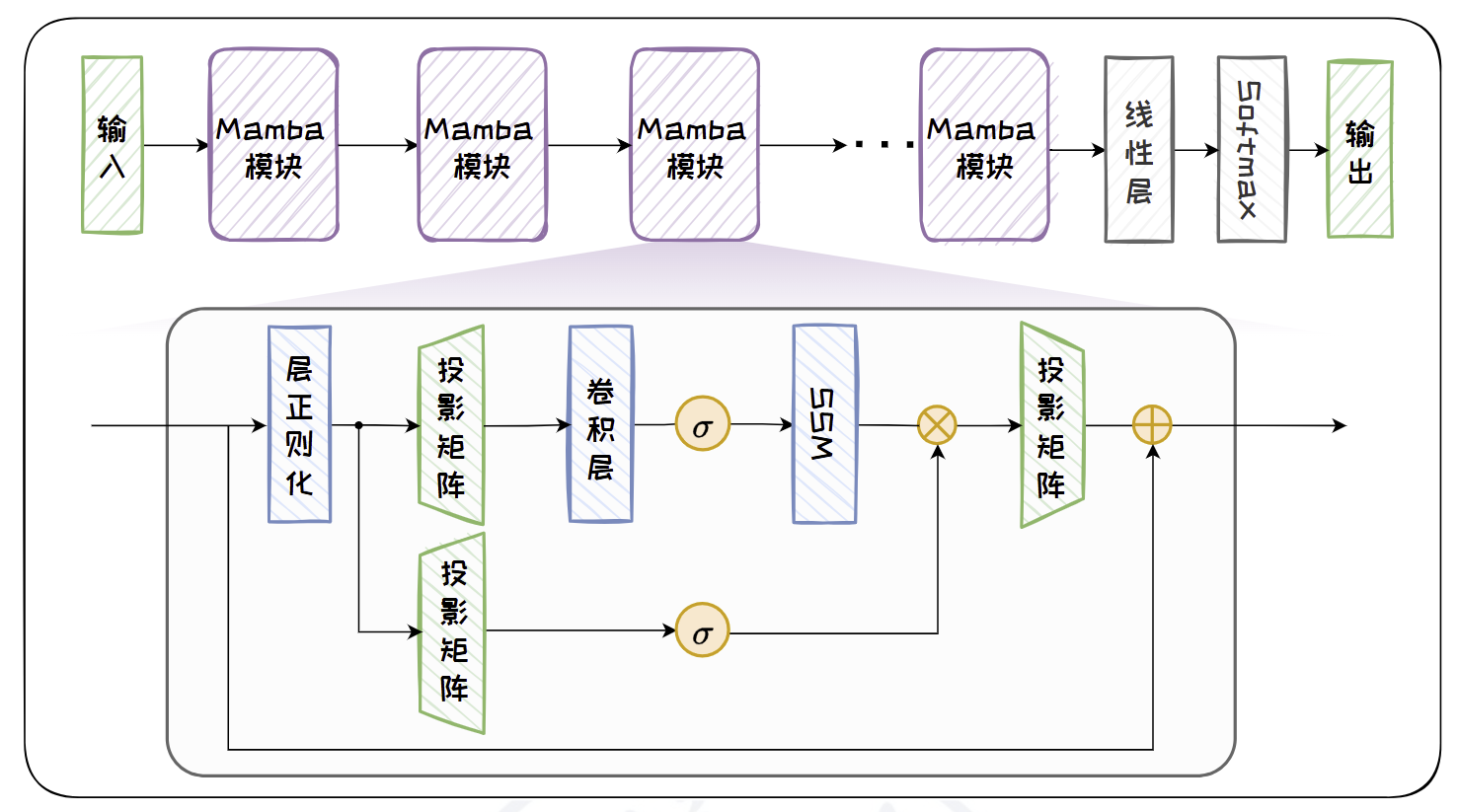
选择性状态空间方程
连续时间 SSM 的标准形式:
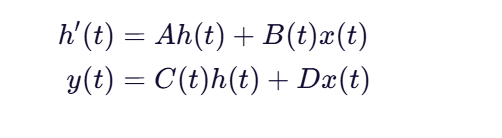
Mamba 的关键创新在于:A, B, C 不再是固定矩阵,而是 token 的函数:
- 模型可以根据输入内容选择保留或忽略哪些信息,实现“选择性记忆”。
硬件感知设计(Hardware-Aware Algorithm)
Mamba 重新设计了 SSM 的计算流程,使其:
- 在训练时支持全序列并行(不像传统 RNN 只能串行);
- 利用 CUDA 内存融合(kernel fusion)减少 IO 开销;
- 避免中间状态频繁读写显存,大幅提升 GPU 利用率。
这使得 Mamba 在实际运行中比理论复杂度预测的还要快。
线性复杂度 + 长上下文
- 时间复杂度:O(L)(L 为序列长度)
- 内存占用:O(L)(训练),O(1)(推理,只需保存状态)
- 支持 百万级 token 上下文(如 1M+ tokens),远超标准 Transformer(通常 ≤ 32K)
🆚 Mamba vs Transformer vs RWKV
| 特性 | Transformer | RWKV | Mamba |
|---|---|---|---|
| 注意力机制 | 显式 softmax attention | 隐式 RNN-style attention | 选择性状态空间 |
| 训练并行性 | ✅ 完全并行 | ✅ 完全并行 | ✅ 完全并行 |
| 推理复杂度 | O(N²) | O(N) | O(N) |
| 推理内存 | O(N) | O(1) | O(1) |
| 长序列建模 | 受限(需稀疏/滑窗) | 优秀 | 极强(原生支持) |
| 内容选择性 | ✅(通过 Q-K 匹配) | ✅(通过 receptance) | ✅(通过 B/C 输入依赖) |
| 硬件优化 | 成熟 | 良好(CPU 友好) | 极致 GPU 优化 |