
搜索策略
在序列到序列(Seq2Seq)模型中,解码器(Decoder)在生成目标序列时,需要从巨大的词汇空间中找到概率最高的序列。由于可能的序列组合呈指数级增长,直接找到全局最优解通常是不可能的。因此,我们使用不同的搜索策略来近似最优解。
常见的搜索策略:贪心搜索(Greedy Search)、穷举搜索(Exhaustive Search / Brute Force) 和 束搜索(Beam Search)。
贪心搜索 (Greedy Search)
贪心搜索是最简单的策略。在每一个时间步 ,模型只选择当前条件概率最大的那个词作为输出,并将其作为下一步的输入。它一旦做出选择,就永不回退。
在每个时间步,贪心搜索选择具有最高条件概率的词元:
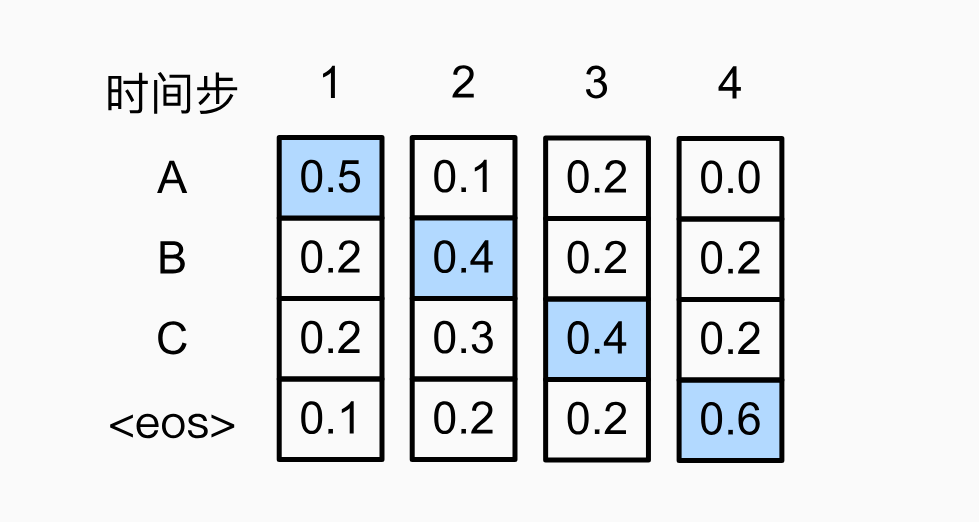
- 优点:
- 速度极快:计算复杂度最低,每个时间步只需计算一次前向传播并取最大值。
- 内存占用小:只需要维护一条路径。
- 缺点:
- 容易陷入局部最优:因为它只看眼前利益(当前步概率最大),忽略了长远的全局概率。有时候选择一个当前概率稍低的词,可能会开启后续更高概率的序列,但贪心搜索无法做到这一点。
- 缺乏多样性:生成的文本往往比较保守、重复或平庸。
- 适用场景: 对实时性要求极高、对生成质量要求不苛刻的场景,或者作为其他复杂搜索的基线。
穷举搜索 (Exhaustive Search)
穷举搜索(也称为暴力搜索)试图遍历所有可能的序列组合,计算每一条完整序列的联合概率,最后选出概率最大的那一条。
- 优点:
- 理论上的全局最优:如果算力无限且能遍历完,它一定能找到概率最高的完美序列。
- 缺点:
- 计算不可行:假设词汇表大小为 ,序列长度为 ,搜索空间大小为 。例如 ,,组合数就是 ,这在现有计算机算力下是完全不可能完成的。
- 适用场景:
- 仅用于理论分析或极短序列(如 或 )的教学演示。在实际的 NLP 任务中几乎从不使用。
束搜索 (Beam Search)
束搜索是贪心搜索和穷举搜索之间的折中方案,也是目前工业界最常用的解码策略。 它不只是一条路走到黑(像贪心),也不遍历所有路(像穷举),而是维护一个大小为 (称为 Beam Width,束宽)的候选序列集合。
执行步骤
- 初始化:在 时,计算所有词汇的概率,保留概率最高的 个词,形成 条路径。
- 扩展:在 时,对这 条路径分别尝试接上词汇表中的每一个词,产生 个候选序列。
- 剪枝:计算这 个序列的累积概率,只保留总分最高的 个序列,丢弃其余的。
- 重复:重复上述过程直到所有路径都生成结束符()或达到最大长度。
示例:
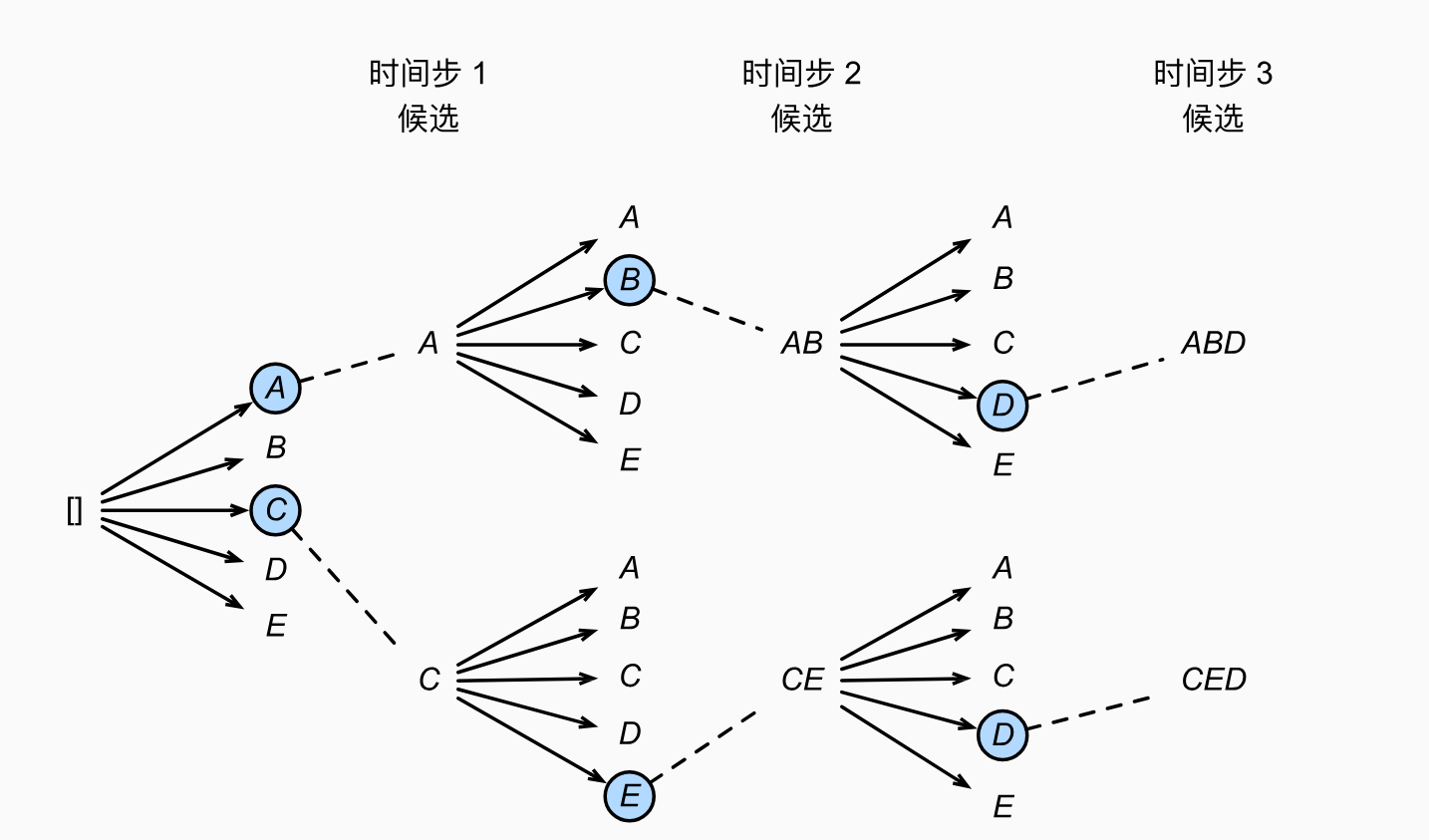
- 优点:
- 平衡了效率与质量:通过调整束宽 ,可以在计算成本和生成质量之间灵活权衡。 越大,越接近穷举搜索的效果; 时退化为贪心搜索。
- 避免局部最优:允许暂时选择概率不是最高的词,以换取后续更高的整体概率。
- 缺点:
- 非并行化:由于每一步依赖上一步的结果,难以像编码过程那样完全并行加速。
- 可能产生重复:在某些情况下(特别是 较大时),束搜索倾向于生成重复的短语或循环。
- 不是全局最优:依然不能保证找到绝对的全局最优解,只是比贪心好很多。
- 适用场景: 机器翻译、文本摘要、对话系统等大多数需要高质量生成的 Seq2Seq 任务的标准配置。
总结
| 特性 | 贪心搜索 (Greedy) | 穷举搜索 (Exhaustive) | 束搜索 (Beam Search) |
|---|---|---|---|
| 核心逻辑 | 每步选最大概率 | 遍历所有可能 | 保留前 个最佳路径 |
| 计算复杂度 | (极低) | (指数级,不可行) | (中等) |
| 全局最优性 | 差 (易陷局部最优) | 完美 (理论上的) | 较好 (近似全局最优) |
| 内存消耗 | 低 | 极高 (爆内存) | 中 (取决于 ) |
| 生成多样性 | 低 | 高 (包含所有可能) | 中 (受 限制) |
| 实际应用 | 快速原型、实时要求极高 | 基本不用 | 主流标准 (翻译/摘要) |