参数高效微调 —— 低秩适配方法
简介
低秩适配方法(Low-rank Adaptation Methods)通过低秩矩阵来近似原始权重权更新矩阵,并仅微调低秩矩阵,以大幅降低模型参数量。
LoRA
低秩适配(Low-rank Adaptation, LoRA)提出利用低秩矩阵近似参数更新矩阵来实现低秩适配。该方法将参数更新矩阵低秩分解为两个小矩阵。在微调时,通过微调这两个小矩阵来对大语言模型进行更新,大幅节省了微调时的内存开销。
核心原理:

在训练过程中,固定预训练模型的参数,仅微调B和A的参数。因此,在训练时,LoRA 涉及的更新参数数量为r×(d+k),远小于全量微调d×k。
✅ 主要优势
| 优势 | 说明 |
|---|---|
| 参数效率高 | 仅需训练少量参数(例如,7B 模型用 LoRA 可减少 90%+ 可训练参数) |
| 无推理延迟 | 推理时可将 ( W + AB ) 合并回原权重,完全不影响速度 |
| 内存占用低 | 训练时只需存储低秩矩阵和梯度,显著降低显存需求 |
| 支持多任务/多适配器 | 可为不同任务保存不同的 (A,B) 对,按需切换(类似“插件”) |
| 兼容性强 | 可应用于 Transformer 的 Q、K、V、O 投影层等 |
LoRA 相关变体
| 方法 | 核心创新 | 可训练参数 | 优势场景 |
|---|---|---|---|
| LoRA | 基础低秩更新 | 低 | 通用、平衡 |
| DoRA | 分离幅值与方向 | 同 LoRA | 高精度任务(数学、推理) |
| PiSSA | SVD 初始化主子空间 | 同 LoRA | 低秩高效收敛 |
| VeRA | 固定投影 + 对角缩放 | 极低 | 超轻量部署 |
| MoRA | 高有效秩非线性结构 | 同 LoRA | 复杂任务(代码、逻辑) |
| AdaLoRA | 动态秩分配 | 同 LoRA | 参数预算敏感场景 |
| Q-LoRA | 4-bit 量化 + LoRA | 低 | 极限显存下微调大模型 |
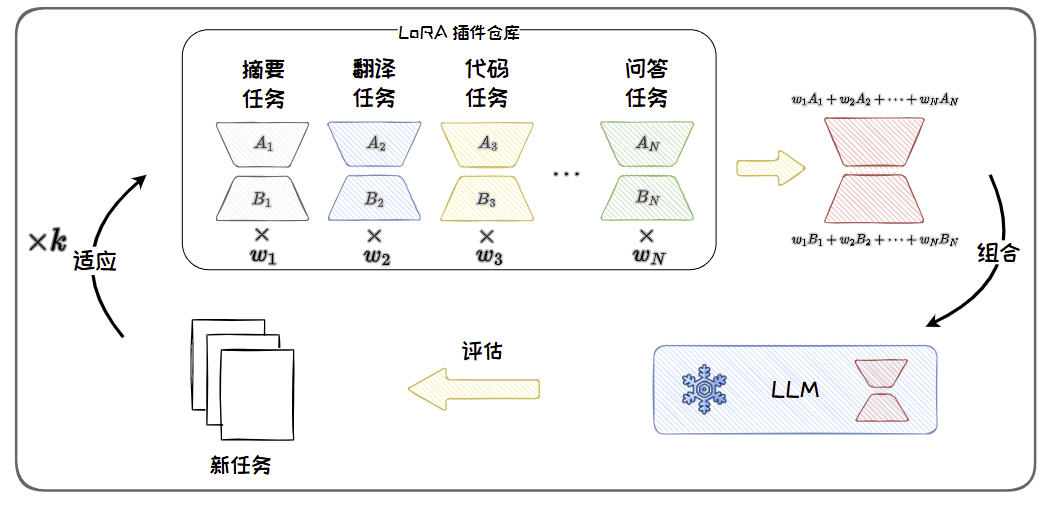
基于LoRA 插件的任务泛化
在 LoRA 微调结束后,我们可以将参数更新模块 B 和 A 从模型上分离出来,并封装成参数插件。这些插件具有即插即用、不破坏原始模型参数和结构的优良性质。可以在不同任务上训练的各种LoRA 模块,将这些模块插件化地方式保存、共享与使用。
LoRAHub 提供了一个可用的多LoRA 组合的方法框架。其可将已有任务上得到的LoRA 插件进行组合,从而获得解决新任务的能力。