
批量归一化
参考文章
知识积累
| 欠拟合(Underfitting) | 过拟合(Overfitting) | |
|---|---|---|
| 训练误差 | 高 | 很低 |
| 测试误差 | 高 | 很高 |
| 原因 | 模型太简单 / 学得不够 | 模型太复杂 / 学得太“死” |
| 解决方向 | 增强模型能力 / 增加特征 | 降低复杂度 / 增加数据 / 正则化 |
| 类比 | 学生没学会基础知识 | 学生死记硬背,不会举一反三 |
提出背景
正则化有助于防止模型过度拟合,学习过程变得更加高效。有几个正则化工具:
- Early Stopping
- 在训练过程中监控验证集性能,当验证误差不再下降(甚至开始上升)时,提前终止训练。
- dropout
- 在训练过程中,随机将一部分神经元的输出置零(如 50%概率),迫使网络不依赖于特定神经元,增强鲁棒性。
- 权重初始化技术 (Weight Initialization Techniques)
- 在训练开始前,以合适的方式(如 Xavier、He 初始化)设置网络权重的初始值,使信号在前向/反向传播中保持稳定(避免梯度消失或爆炸)。
- 批量归一化 (Batch Normalization)。
- 对每个 mini-batch 的激活值进行标准化(减均值、除标准差),再通过可学习的缩放和平移参数恢复表达能力。
概念
归一化是一种数据预处理工具,用于将数值数据调整为通用比例而不扭曲其形状。通常,当我们将数据输入机器或深度学习算法时,倾向于将值更改为平衡的比例。规范化是为了确保模型可以适当地概括数据。
现在回到 Batch Normalization,这是一个通过在深度神经网络中添加额外层来使神经网络更快、更稳定的过程。新层对来自上一层的层的输入执行标准化和规范化操作。
通过一个例子来理解批量归一化过程,我们有一个深度神经网络,如下图所示。
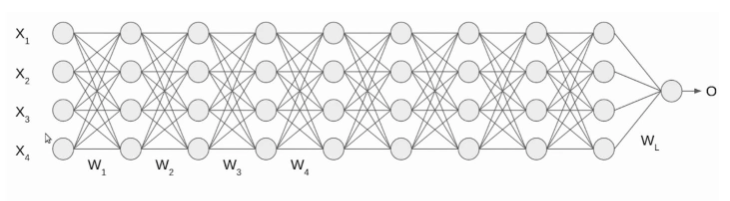
当输入通过第一层时,输入 X 和权重矩阵 W 进行点积计算,再经过 sigmoid 函数。以此类推。第一层计算方式应用到每一层,最后一层记录为 L,如图所示。输入 X 随时间归一化,输出将不再处于同一比例。
当数据经过多层神经网络并经过 L 个激活函数时,会导致数据发生内部协变量偏移(Internal Covariate Shift)。在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化,这一过程被称作 Internal Covariate Shift。
工作原理
先将输入归一化,然后执行重新缩放和偏移。
输入归一化
归一化是将数据转换为均值为零和标准差为 1 的过程。
计算隐藏激活的均值
- m 是 h 层神经元的数量。下一步就是计算隐藏激活的标准差。
- m 是 h 层神经元的数量。下一步就是计算隐藏激活的标准差。
计算隐藏激活的标准差
每个输入中减去平均值,除以标准差和平滑项 (ε) 的总和。
平滑项 (ε) 一个非常小的常数,防止分母零值来确保运算中的数值稳定。
归一化后的隐藏激活值:
其中, 是 层神经元的数量, 是一个非常小的常数,用于防止分母为零。
重新缩放与偏移
在最后的操作中,将对输入进行重新缩放和偏移。重新缩放参数 γ (gamma) 和偏移参数 β (beta)。
这样,每个神经元的输出都遵循整个批次的标准正态分布。为此,每个输入中减去平均值,除以标准差和平滑项 (ε) 的总和。平滑项 (ε) 一个非常小的常数,防止分母零值来确保运算中的数值稳定。
具体步骤
BN步骤主要分为4步:
- 求每一个训练批次数据的均值;
- 求每一个训练批次数据的方差;
- 使用求得的均值和方差对该批次的训练数据做归一化,获得0-1分布;
- 尺度变换和偏移
- 重新缩放参数 γ (gamma) 和偏移参数 β (beta)。
使用
标准做法:放在“线性变换之后、激活函数之前”
Linear (或 Conv) → BatchNorm → Activation (如 ReLU)