
参数高效微调 - 概述
简介
对于预训练数据涉及较少的垂直领域,大语言模型需要对这些领域及相应的下游任务进行适配。上下文学习和指令微调是进行下游任务适配的有效途径,但它们在效果或效率上存在缺陷。为弥补这些不足,参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术应运而生。
下游任务适配
大语言模型通过在大规模数据集上进行预训练,能够积累丰富的世界知识,并获得处理多任务的能力。但由于开源大语言模型训练数据有限,因此仍存在知识边界,导致其在垂直领域(如医学、金融、法学等)上的知识不足,进而影响在垂直领域的性能表现。
因此,需要进行下游任务适配才能进一步提高其在垂直和细分领域上的性能。主流的下游任务适配方法有两种:
- 上下文学习(In-context learning)
- 指令微调(Instruction Tuning)
上下文学习
核心思想是将不同类型的任务都转化为生成任务,通过设计Prompt来驱动大语言模型完成这些下游任务。
上下文学习能有效利用大语言模型的能力,但它缺点也很明显:
- 上下文学习的性能和微调依旧存在差距,并且Prompt 设计需要花费大量的人力成本,不同Prompt 的最终任务性能有较大差异;
- 上下文学习虽然完全不需要训练,但在推理阶段的代价会随Prompt 中样例的增多快速增加。
指令微调
在对模型进行任务指令的学习,使其能更好地理解和执行各种自然语言处理任务的指令。指令微调需首先构建指令数据集,然后在该数据集上进行监督微调。
- 指令数据构建:指令数据通常包含指令(任务描述)、示例(可选)、问题和回答
- 监督微调:通过上述方法构建完数据集后,可以用完全监督的方式对预训练模型进行微调,在给定指令和输入的情况下,通过顺序预测输出中的每个token来训练模型。

参数高效微调
参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)旨在避免微调全部参数,减少在微调过程中需要更新的参数数量和计算开销,从而提高微调大语言模型的效率。
主流的PEFT 方法可以分为三类:
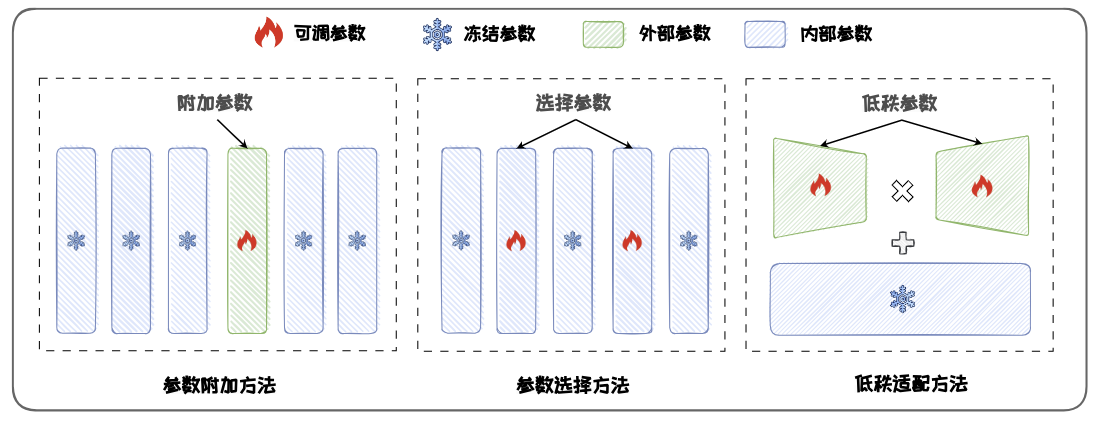
参数附加方法
参数附加方法(Additional Parameters Methods)在模型结构中附加新的、较小的可训练模块。在进行微调时,将原始模型参数冻结,仅微调这些新加入的模块,从而来实现高效微调。这些模块通常称为适应层(Adapter Layer)。它们被插入到模型的不同层之间,用于捕获特定任务的信息。由于这些新增的适应层参数量很小,所以参数附加方法能够显著减少需要更新的参数量。典型方法包括:适配器微调(Adapter-tuning)、提示微调(Prompt-tuning)、前缀微调(Prefix-tuning) 和代理微调(Proxy-tuning)等。
参数选择方法
参数选择方法(Parameter Selection Methods)仅选择模型的一部分参数进行微调,而冻结其余参数。这种方法利用了模型中仅有部分参数对下游任务具有决定性作用的特性,“抓住主要矛盾”,仅微调这些关键参数。选择性地微调这些关键参数,可以在降低计算负担的同时提升模型的性能。典型的方法包括:BitFit、Child-tuning以及FishMask等。
低秩适配方法
低秩适配方法(Low-rank Adaptation Methods)通过低秩矩阵来近似原始权重更新矩阵,并冻结原始参数矩阵,仅微调低秩更新矩阵。由于低秩更新矩阵的参数数量远小于原始的参数更新矩阵,因此大幅节省了微调时的内存开销。
优势
参数高效微调有以下优势:
- 计算效率高:PEFT 技术减少了需要更新的参数数量,从而降低了训练时的计算资源消耗;
- 存储效率高:通过减少需要微调的参数数量,PEFT 显著降低了微调模型的存储空间,特别适用于内存受限的设备;
- 适应性强:PEFT 能够快速适应不同任务,而无需重新训练整个模型,使得模型在面对变化环境时具有更高的灵活性。