
语义分割
参考文献
概念
图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。
语义分割即对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中。
语义分割和实例分割的区别
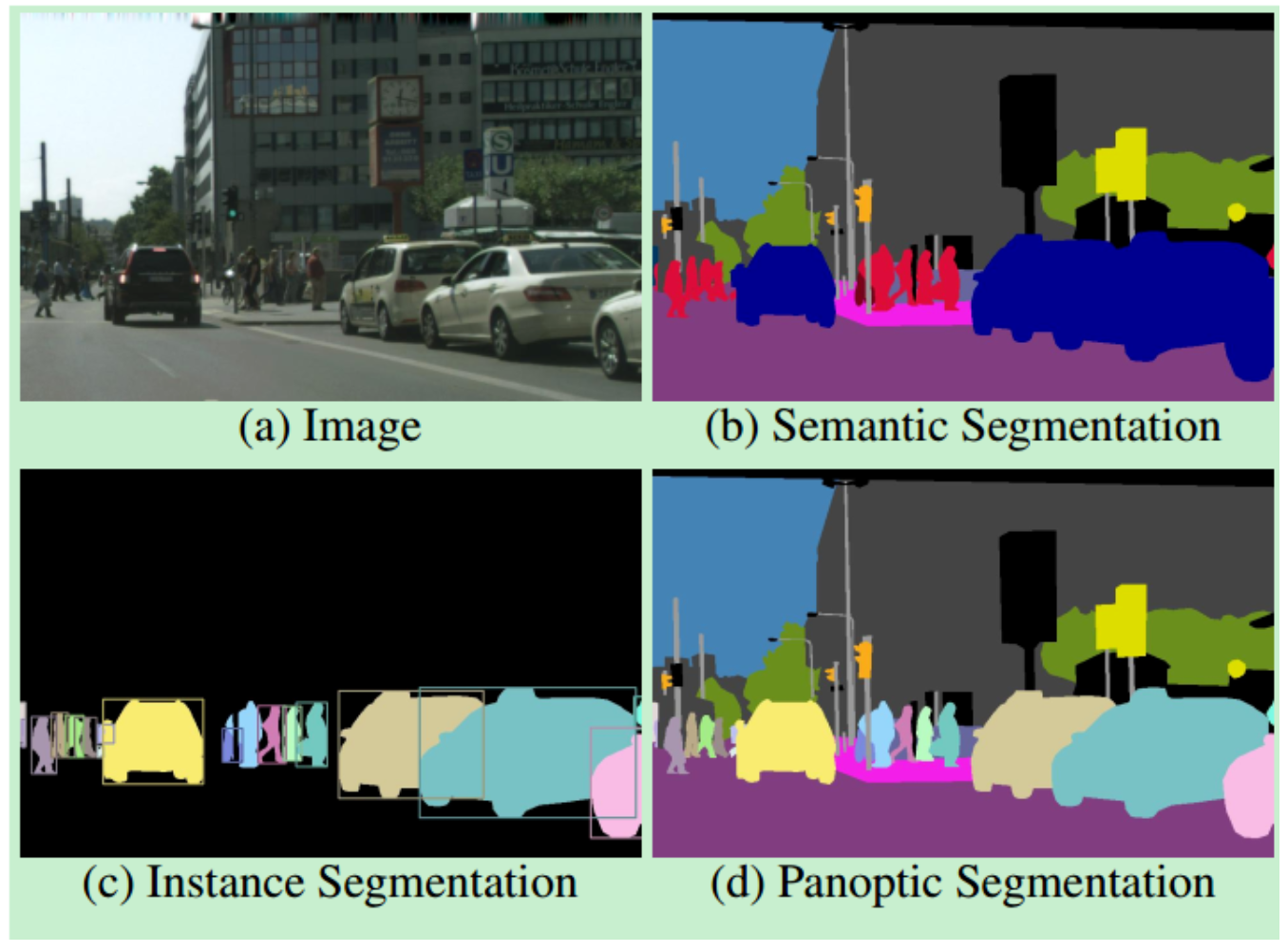
- 基于深度学习的图像分割技术主要分为两类:语义分割和实例分割。
- 语义分割:为图像中的每个像素分配一个类别,但是同一类别之间的对象不会区分。
- 实例分割:只对特定的物体进行分类。这看起来与目标检测相似,不同的是目标检测输出目标的边界框和类别,实例分割输出的是目标的Mask和类别。
- 补充:全景分割(Panoptic Segmentation)是计算机视觉中的一项高级图像理解任务,它统一了语义分割(Semantic Segmentation)和实例分割(Instance Segmentation),旨在对图像中的每一个像素进行唯一且一致的类别标注,同时区分“可数”对象(如人、车)和“不可数”区域(如天空、道路)。
| 任务 | 目标 | 是否区分实例 |
|---|---|---|
| 语义分割 | 为每个像素分配语义类别 | ❌ 不区分同一类别的不同实例 |
| 实例分割 | 检测并分割每个可数对象的实例 | ✅ 但不处理“东西类”(如天空) |
| 全景分割 | 同时处理“东西类”和“物体类”,每个像素有唯一标签 | ✅ 统一处理两类 |
图像分类与图像语义分割
CNN已经在图像分类分方面取得了巨大的成就,涌现出如VGG和Resnet等网络结构,并在ImageNet中取得了好成绩。
CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:
- 较浅的卷积层感知域较小,学习到一些局部区域的特征;
- 较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
- 抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。
- 抽象特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。
图像语义分割是像素级别的。但是由于CNN在进行convolution和pooling过程中丢失了图像细节,即feature map size逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
针对这个问题,Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。