
大语言模型架构 - 主流模型架构
主流模型架构
Encoder-Decoder 架构
Encoder-only 架构包含三个部分,分别是输入编码部分,特征编码部分以及任务处理部分。
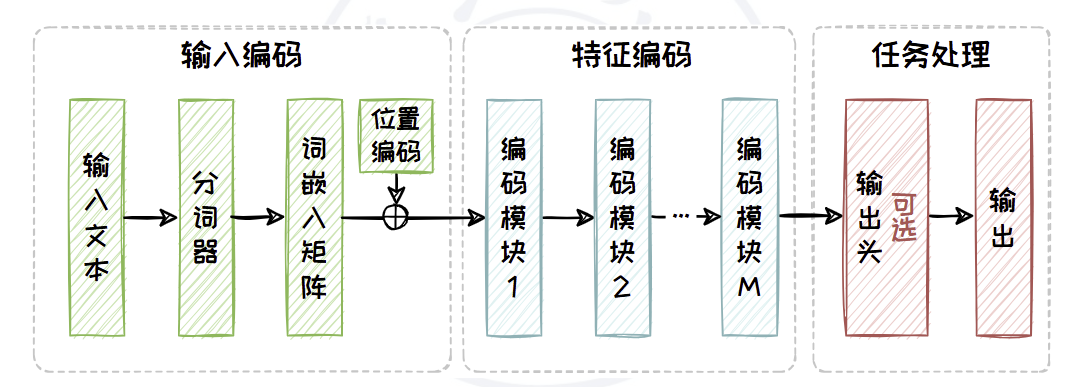
具体的模型结构如图所示。
- 输入编码
- 原始输入文本会被分词器(Tokenizer)拆解为Token 序列
- 随后通过词表和词嵌入(Embedding)矩阵映射为向量序列,确保文本信息得以数字化表达。
- 特征编码
- 由多个相同的编码模块(Encoder Block)堆叠而成
- 得到的向量序列会依次通过一系列编码模块,这些模块通过自注意力机制和前馈网络进一步提取和深化文本特征。
- 任务处理
- 针对任务需求专门设计的模块,其可以由用户针对任务需求自行设计。
- 在预训练阶段,模型通常使用全连接层作为输出头,用于完成掩码预测等任务。
- 在下游任务适配阶段,输出头会根据具体任务需求进行定制。例如,对于情感分析或主题分类等判别任务,只需要添加一个分类器便可直接输出判别结果。
Encoder-Decoder 架构
Encoder-Decoder 架构在Encoder基础上引入了一个解码器(Decoder),并采用交叉注意力机制来实现编码器与解码器之间的有效交互。
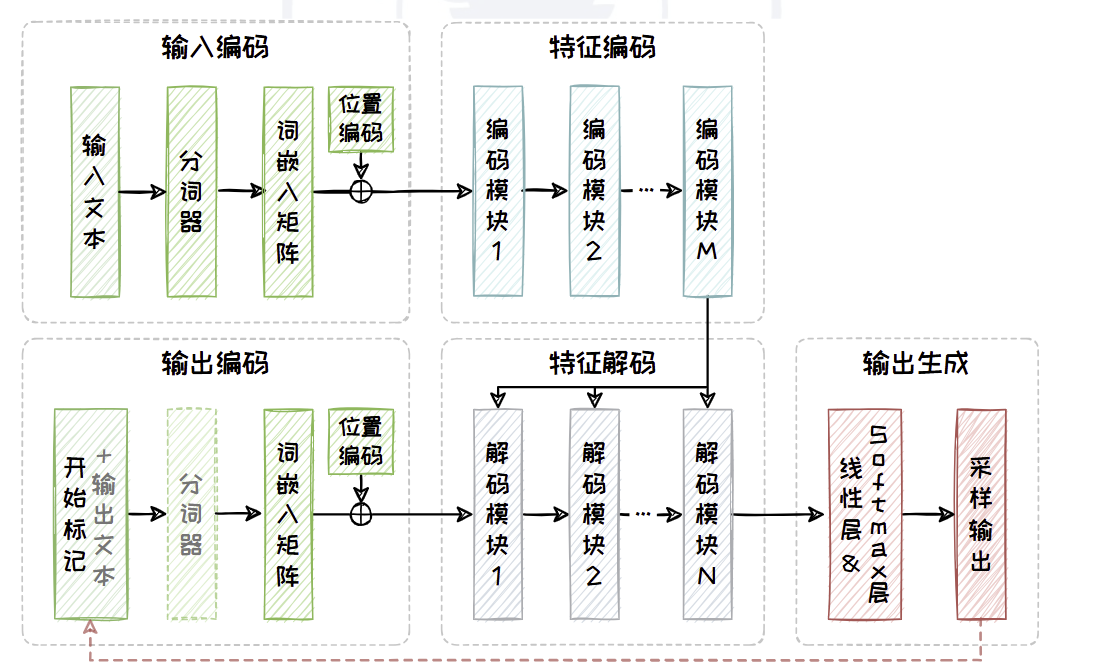
解码器包含了输出编码、特征解码以及输出生成三个部分。
- 输出编码
- 与编码器中的输入编码结构相同,包含分词、向量化以及添加位置编码三个过程,将原始输入文本转换化为带有位置信息的向量序列。
- 特征解码
- 部分与特征编码部分在网络结构上也高度相似,包括掩码自注意力(Masked Self-Attention)模块,交叉注意力模块和全连接前馈模块。
- 输出生成
- 由一个线性层以及一个Softmax 层组成,负责将特征解码后的向量转换为词表上的概率分布,并从这个分布中采样得到最合适的Token 作为输出。
Encoder-Decoder 架构的具体工作流程区分训练阶段和推理阶段。
Decoder-only 架构
模型仅使用解码器来构建语言模型。这种架构利用“自回归”机制,在给定上文的情况下,生成流畅且连贯的下文。
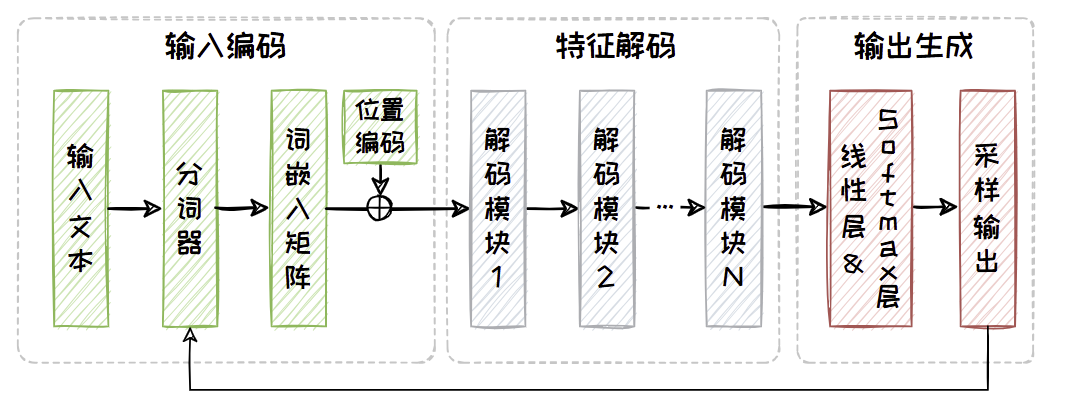
模型架构的功能对比
注意力矩阵
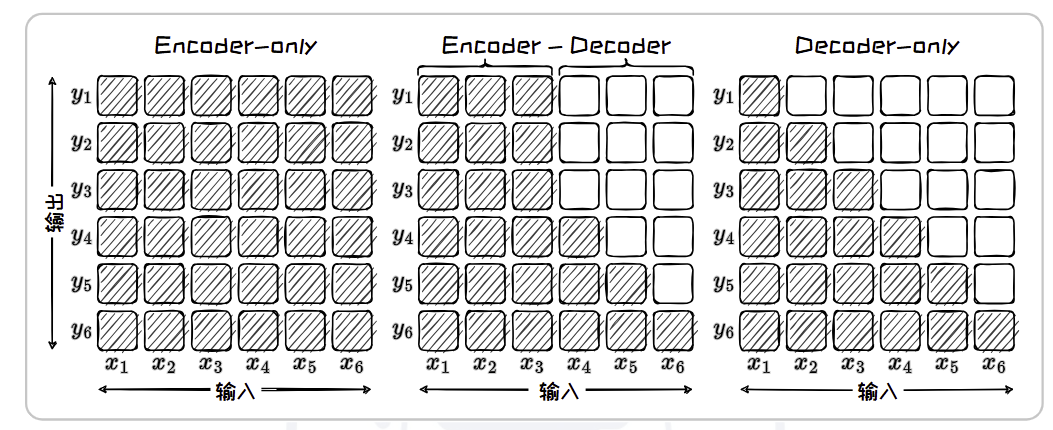
- Encoder-only 架构
- 完全”的注意力,即对于每个Token 的理解都依赖于整个输入序列中的所有Token。
- Encoder-Decoder 架构
- 编码器的自注意力矩阵用于生成输入序列的全面上下文表示,呈现“完全”的注意力。
- 解码器的掩码自注意力矩阵则呈现出“下三角”的注意力,确保在生成当前Token 时,模型只关注之前生成的Token。
- Decoder-only 架构
- 注意力矩阵来自于掩码自注意力模块,其特点是呈现出“下三角”的注意力模式。
适用任务
- Encoder-only 架构
- 特别适合于自然语言理解
- Encoder-Decoder 架构
- 非常适合于处理各种复杂的有条件生成任务
- Decoder-only 架构
- 不依赖于特定的输入文本的无条件文本生成任务中表现出色。