
大语言模型架构 - Encoder-only
概述
Encoder-only 架构的核心在于能够覆盖输入所有内容的双向编码模型(Bidirec-tional Encoder Model)。在处理输入序列时,双向编码模型融合了从左往右的正向注意力以及从右往左的反向注意力,能够充分捕捉每个Token 的上下文信息,因此也被称为具有全面的注意力机制。得益于其上下文感知能力和动态表示的优势,双向编码器显著提升了自然语言处理任务的性能。
BERT 语言模型
BERT(Bidirectional Encoder Representations from Transformers)是一种基于Encoder-only 架构的预训练语言模型,由Google AI 团队于2018 年10 月提出。
模型结构
BERT 模型的结构与Transformer 中的编码器几乎一致,都是由多个编码模块堆叠而成,每个编码模块包含一个多头自注意力模块和一个全连接前馈模块。
预训练方式
BERT 使用小说数据集BookCorpus(包含约8 亿个Token)和英语维基百科数据集6(包含约25 亿个Token)进行预训练,总计约33 亿个Token,总数据量达到了15GB 左右。
在预训练任务上,BERT 开创性地提出了**掩码语言建模(Masked Language Model, MLM)和下文预测(Next Sentence Prediction, NSP)**两种任务来学习生成上下文嵌入。其完整的预训练流程如图所示。
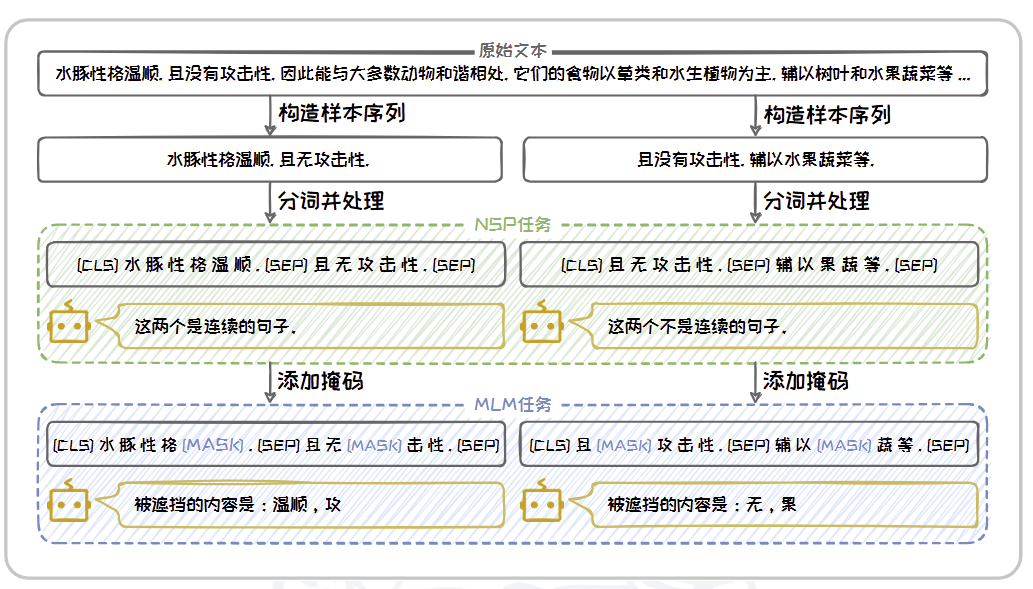
- BERT 先基于给定的原始文本构造多个样本序列,每个样本序列由原始文本中的两个句子组成,这两个句子有 50% 的概率是来自原文的连续句子,另外50% 的概率是随机挑选的两个句子。
- 随后,对构造出来的样本序列进行分词,并在序列的开头添加特殊标签 [CLS],在每个句子的结尾添加特殊标签 [SEP]。其中 [CLS] 标签用于聚合整个序列的信息,而 [SEP] 标签则明确句子之间的界限。
- 接着,BERT 利用处理后的序列进行下文预测任务,利用模型判断样本序列中的两个句子是否为连续的。
- 这一任务训练BERT 识别和理解句子之间的关系,捕捉句子层面的语义特征。这对于理解文本的逻辑流、句子之间的关联性有很大帮助,特别是在问答和自然语言推理等需要理解文档层次结构的自然语言处理(NLP) 任务中。
- 最后,BERT 随机选择样本序列中大约15% 的Token 进行遮掩,将其替换为特殊标签 [MASK] 或者随机单词。模型需要预测这些被替换的Token 的原始内容。
- 这个过程类似于完型填空,要求模型根据周围的上下文信息来推断缺失的Token。预测过程使用的交叉熵损失函数驱动了BERT 模型中参数的优化,使其能够学习到文本的双向上下文表示。
通过这两种预训练任务的结合,使BERT 在理解语言的深度和广度上都有显著提升。BERT 不仅能够捕捉到Token的细粒度特征,还能够把握长距离的依赖关系和句子间的复杂联系,为各种下游任务提供了坚实的语言理解基础。
下游任务
由于BERT 的输出是输入中所有Token的向量表示,因此总长度不固定,无法直接应用于各类下游任务。为了解决这一问题,BERT 设计了 [CLS] 标签来提取整个输入序列的聚合表示。[CLS] 标签是专门为分类和汇总任务设计的特殊标记。其全称是“Classification Token”,即分类标记。
通过注意力机制,[CLS] 标签汇总整个输入序列的信息,生成一个固定长度的向量表示,从而实现对所有Token 序列信息的概括,便于处理各种下游任务。
- 在文本分类任务中,可以将输出中 [CLS] 标签对应的向量提取出来,传递给一个全连接层,从而用于分类,例如判断整个句子的情绪是积极、消极或是中立的。
- 输入句子:“这部电影太精彩了,我非常喜欢!”
- BERT 输入格式:[CLS] 这 部 电 影 太 精 彩 了 , 我 非 常 喜 欢 ! [SEP]
- BERT 编码后(简化示意):
- 每一层 Transformer 都会更新每个 token 的表示。最终,最后一层输出一个向量序列:
Token 最后一层隐藏状态(768维) [CLS] h_cls = [0.23, -0.45, ..., 0.89] ← 聚合了整句语义 这 h_1 部 h_2 ... ... ! h_n [SEP] h_sep- 分类过程:
- 提取 h_cls
- 输入到一个全连接层(比如 768 → 3):
logits = classifier(h_cls) # 输出 shape: [3] → [积极, 中立, 消极] probabilities = softmax(logits)- 输出:
积极: 0.92 中立: 0.07 消极: 0.01 - 在问答系统任务中,需要输入问题以及一段相关的文本,即“[CLS] 问题 [SEP] 文本 [SEP]”。最终同样提取出 [CLS] 标签的对应向量,并传递给两个全连接层,用于判断答案是否存在于相关文本中。