
LeNet
LeNet 是深度学习历史上具有里程碑意义的卷积神经网络(CNN)架构,由 Yann LeCun 及其同事在 1998 年提出。它是第一个成功应用于实际商业场景(手写数字识别)的 CNN,奠定了现代卷积神经网络的基础结构。 LeNet 最著名的版本是 LeNet-5,主要用于识别手写数字(如银行支票上的数字),在当时的 MNIST 数据集上取得了极高的准确率。
整体结构
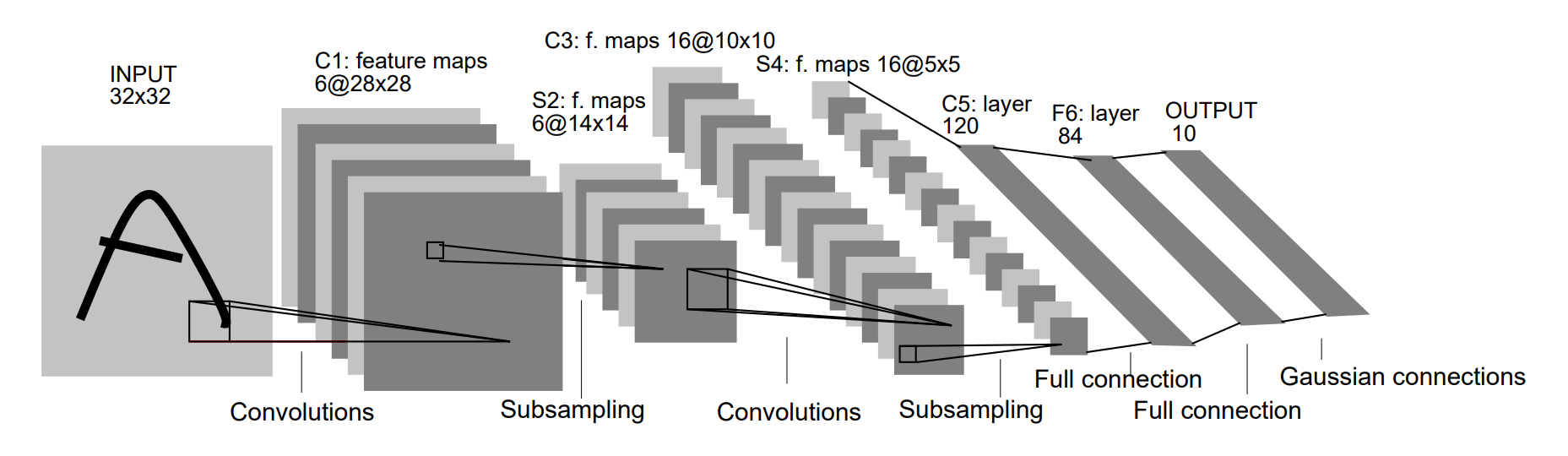
LeNet-5 由 7 层组成(不包括输入层),包含 2 个卷积层、2 个池化层和 3 个全连接层(其中最后一个全连接层是输出层)。其结构可以表示为:
输入 → C1 → S2 → C3 → S4 → C5 → F6 → Output
各层详解
输入层(Input layer)
输入层接收大小为 的手写数字图像,其中包括灰度值(0-255)。在实际应用中,我们通常会对输入图像进行预处理,例如对像素值进行归一化,以加快训练速度和提高模型的准确性。
卷积层C1(Convolutional layer C1)
卷积层C1包括6个卷积核,每个卷积核的大小为 ,步长为1,填充为0。因此,每个卷积核会产生一个大小为 的特征图(输出通道数为6)。
采样层S2(Subsampling layer S2)
采样层S2采用最大池化(max-pooling)操作,每个窗口的大小为 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 的特征图(输出通道数为6)。这样可以减少特征图的大小,提高计算效率,并且对于轻微的位置变化可以保持一定的不变性。
卷积层C3(Convolutional layer C3)
卷积层C3包括16个卷积核,每个卷积核的大小为 ,步长为1,填充为0。因此,每个卷积核会产生一个大小为 的特征图(输出通道数为16)。
采样层S4(Subsampling layer S4)
采样层S4采用最大池化操作,每个窗口的大小为 ,步长为2。因此,每个池化操作会从4个相邻的特征图中选择最大值,产生一个大小为 的特征图(输出通道数为16)。
全连接层C5(Fully connected layer C5)
C5将每个大小为 的特征图拉成一个长度为400的向量,并通过一个带有120个神经元的全连接层进行连接。120是由LeNet-5的设计者根据实验得到的最佳值。
全连接层F6(Fully connected layer F6)
全连接层F6将120个神经元连接到84个神经元。
输出层(Output layer)
输出层由10个神经元组成,每个神经元对应0-9中的一个数字,并输出最终的分类结果。
LeNet-5训练过程
LeNet-5的训练过程使用反向传播算法(BP算法),通过最小化误差函数(通常使用交叉熵损失函数)来优化网络的权重和偏置。网络的权重和偏置是通过随机初始化得到的,然后,网络通过反向传播算法不断地调整权重和偏置,使得误差函数最小化。
实践代码
详情
<!-- #include-env-start: D:/code/klc/test/share4ai/docs/book/dive_into_on_dl/cnn/basic -->
```python
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义LeNet-5模型
class LeNet5(nn.Module):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1)
self.pool1 = nn.AvgPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool2 = nn.AvgPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 查看模型
net = LeNet5()
net
LeNet5(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(pool1): AvgPool2d(kernel_size=2, stride=2, padding=0)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(pool2): AvgPool2d(kernel_size=2, stride=2, padding=0)
(fc1): Linear(in_features=256, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data', train=False, transform=transforms.ToTensor())
# 定义数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
# 定义模型、损失函数和优化器
model = LeNet5()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
100%|██████████████████████████████████████████████████████████████████████████████████| 9.91M/9.91M [00:14<00:00, 680kB/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 28.9k/28.9k [00:00<00:00, 111kB/s]
100%|█████████████████████████████████████████████████████████████████████████████████| 1.65M/1.65M [00:01<00:00, 1.08MB/s]
100%|██████████████████████████████████████████████████████████████████████████████████| 4.54k/4.54k [00:00<00:00, 748kB/s]
# 内容解析
# optimizer.zero_grad() # 清零梯度(不清零,新的梯度会累加到旧的梯度上)
# outputs = model(images) # 前向传播(Forward Pass)
# loss = criterion(outputs, labels) # 计算损失(Compute Loss)
# loss.backward() # 反向传播(Backward Pass),自动计算损失函数相对于每个模型参数的梯度(Gradient)
# optimizer.step() #更新参数(Update Weights)
# 训练模型
for epoch in range(10):
for i, (images, labels) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'.format(epoch+1, 10, i+1, len(train_loader), loss.item()))
Epoch [1/10], Step [100/938], Loss: 0.6234
Epoch [1/10], Step [200/938], Loss: 0.4284
Epoch [1/10], Step [300/938], Loss: 0.3300
Epoch [1/10], Step [400/938], Loss: 0.2102
Epoch [1/10], Step [500/938], Loss: 0.3011
Epoch [1/10], Step [600/938], Loss: 0.1912
Epoch [1/10], Step [700/938], Loss: 0.1326
Epoch [1/10], Step [800/938], Loss: 0.2862
Epoch [1/10], Step [900/938], Loss: 0.2223
Epoch [2/10], Step [100/938], Loss: 0.1443
Epoch [2/10], Step [200/938], Loss: 0.0809
Epoch [2/10], Step [300/938], Loss: 0.0685
Epoch [2/10], Step [400/938], Loss: 0.2446
Epoch [2/10], Step [500/938], Loss: 0.0586
Epoch [2/10], Step [600/938], Loss: 0.2020
Epoch [2/10], Step [700/938], Loss: 0.0791
Epoch [2/10], Step [800/938], Loss: 0.1550
Epoch [2/10], Step [900/938], Loss: 0.1234
Epoch [3/10], Step [100/938], Loss: 0.1483
Epoch [3/10], Step [200/938], Loss: 0.1907
Epoch [3/10], Step [300/938], Loss: 0.0910
Epoch [3/10], Step [400/938], Loss: 0.1092
Epoch [3/10], Step [500/938], Loss: 0.0612
Epoch [3/10], Step [600/938], Loss: 0.1503
Epoch [3/10], Step [700/938], Loss: 0.1208
Epoch [3/10], Step [800/938], Loss: 0.0279
Epoch [3/10], Step [900/938], Loss: 0.2095
Epoch [4/10], Step [100/938], Loss: 0.1174
Epoch [4/10], Step [200/938], Loss: 0.0583
Epoch [4/10], Step [300/938], Loss: 0.0855
Epoch [4/10], Step [400/938], Loss: 0.1862
Epoch [4/10], Step [500/938], Loss: 0.0831
Epoch [4/10], Step [600/938], Loss: 0.0425
Epoch [4/10], Step [700/938], Loss: 0.0778
Epoch [4/10], Step [800/938], Loss: 0.1162
Epoch [4/10], Step [900/938], Loss: 0.0324
Epoch [5/10], Step [100/938], Loss: 0.1174
Epoch [5/10], Step [200/938], Loss: 0.0392
Epoch [5/10], Step [300/938], Loss: 0.0196
Epoch [5/10], Step [400/938], Loss: 0.2321
Epoch [5/10], Step [500/938], Loss: 0.0102
Epoch [5/10], Step [600/938], Loss: 0.0157
Epoch [5/10], Step [700/938], Loss: 0.0492
Epoch [5/10], Step [800/938], Loss: 0.0245
Epoch [5/10], Step [900/938], Loss: 0.0086
Epoch [6/10], Step [100/938], Loss: 0.0614
Epoch [6/10], Step [200/938], Loss: 0.1594
Epoch [6/10], Step [300/938], Loss: 0.1535
Epoch [6/10], Step [400/938], Loss: 0.0594
Epoch [6/10], Step [500/938], Loss: 0.0013
Epoch [6/10], Step [600/938], Loss: 0.0044
Epoch [6/10], Step [700/938], Loss: 0.0391
Epoch [6/10], Step [800/938], Loss: 0.0559
Epoch [6/10], Step [900/938], Loss: 0.0178
Epoch [7/10], Step [100/938], Loss: 0.1024
Epoch [7/10], Step [200/938], Loss: 0.0174
Epoch [7/10], Step [300/938], Loss: 0.0716
Epoch [7/10], Step [400/938], Loss: 0.1779
Epoch [7/10], Step [500/938], Loss: 0.0771
Epoch [7/10], Step [600/938], Loss: 0.0114
Epoch [7/10], Step [700/938], Loss: 0.0077
Epoch [7/10], Step [800/938], Loss: 0.0124
Epoch [7/10], Step [900/938], Loss: 0.0698
Epoch [8/10], Step [100/938], Loss: 0.0152
Epoch [8/10], Step [200/938], Loss: 0.0133
Epoch [8/10], Step [300/938], Loss: 0.0208
Epoch [8/10], Step [400/938], Loss: 0.0680
Epoch [8/10], Step [500/938], Loss: 0.0053
Epoch [8/10], Step [600/938], Loss: 0.0308
Epoch [8/10], Step [700/938], Loss: 0.0161
Epoch [8/10], Step [800/938], Loss: 0.0126
Epoch [8/10], Step [900/938], Loss: 0.0302
Epoch [9/10], Step [100/938], Loss: 0.0350
Epoch [9/10], Step [200/938], Loss: 0.1630
Epoch [9/10], Step [300/938], Loss: 0.0145
Epoch [9/10], Step [400/938], Loss: 0.0424
Epoch [9/10], Step [500/938], Loss: 0.1125
Epoch [9/10], Step [600/938], Loss: 0.0654
Epoch [9/10], Step [700/938], Loss: 0.0730
Epoch [9/10], Step [800/938], Loss: 0.0307
Epoch [9/10], Step [900/938], Loss: 0.0057
Epoch [10/10], Step [100/938], Loss: 0.1451
Epoch [10/10], Step [200/938], Loss: 0.0602
Epoch [10/10], Step [300/938], Loss: 0.0211
Epoch [10/10], Step [400/938], Loss: 0.0367
Epoch [10/10], Step [500/938], Loss: 0.0065
Epoch [10/10], Step [600/938], Loss: 0.0348
Epoch [10/10], Step [700/938], Loss: 0.0185
Epoch [10/10], Step [800/938], Loss: 0.0023
Epoch [10/10], Step [900/938], Loss: 0.0046
# 测试模型
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Test Accuracy: {:.2f}%'.format(100 * correct / total))
Test Accuracy: 98.78%
total_samples = len(test_loader.dataset)
print(f"总样本数: {total_samples}")
for images, labels in test_loader:
print('Test Accuracy: {}%'.format(labels))
总样本数: 10000
Test Accuracy: tensor([7, 2, 1, 0, 4, 1, 4, 9, 5, 9, 0, 6, 9, 0, 1, 5, 9, 7, 3, 4, 9, 6, 6, 5,
4, 0, 7, 4, 0, 1, 3, 1, 3, 4, 7, 2, 7, 1, 2, 1, 1, 7, 4, 2, 3, 5, 1, 2,
4, 4, 6, 3, 5, 5, 6, 0, 4, 1, 9, 5, 7, 8, 9, 3])%
Test Accuracy: tensor([7, 4, 6, 4, 3, 0, 7, 0, 2, 9, 1, 7, 3, 2, 9, 7, 7, 6, 2, 7, 8, 4, 7, 3,
6, 1, 3, 6, 9, 3, 1, 4, 1, 7, 6, 9, 6, 0, 5, 4, 9, 9, 2, 1, 9, 4, 8, 7,
3, 9, 7, 4, 4, 4, 9, 2, 5, 4, 7, 6, 7, 9, 0, 5])%
Test Accuracy: tensor([8, 5, 6, 6, 5, 7, 8, 1, 0, 1, 6, 4, 6, 7, 3, 1, 7, 1, 8, 2, 0, 2, 9, 9,
5, 5, 1, 5, 6, 0, 3, 4, 4, 6, 5, 4, 6, 5, 4, 5, 1, 4, 4, 7, 2, 3, 2, 7,
1, 8, 1, 8, 1, 8, 5, 0, 8, 9, 2, 5, 0, 1, 1, 1])%
Test Accuracy: tensor([0, 9, 0, 3, 1, 6, 4, 2, 3, 6, 1, 1, 1, 3, 9, 5, 2, 9, 4, 5, 9, 3, 9, 0,
3, 6, 5, 5, 7, 2, 2, 7, 1, 2, 8, 4, 1, 7, 3, 3, 8, 8, 7, 9, 2, 2, 4, 1,
5, 9, 8, 7, 2, 3, 0, 4, 4, 2, 4, 1, 9, 5, 7, 7])%
Test Accuracy: tensor([2, 8, 2, 6, 8, 5, 7, 7, 9, 1, 8, 1, 8, 0, 3, 0, 1, 9, 9, 4, 1, 8, 2, 1,
2, 9, 7, 5, 9, 2, 6, 4, 1, 5, 8, 2, 9, 2, 0, 4, 0, 0, 2, 8, 4, 7, 1, 2,
4, 0, 2, 7, 4, 3, 3, 0, 0, 3, 1, 9, 6, 5, 2, 5])%
Test Accuracy: tensor([9, 2, 9, 3, 0, 4, 2, 0, 7, 1, 1, 2, 1, 5, 3, 3, 9, 7, 8, 6, 5, 6, 1, 3,
8, 1, 0, 5, 1, 3, 1, 5, 5, 6, 1, 8, 5, 1, 7, 9, 4, 6, 2, 2, 5, 0, 6, 5,
6, 3, 7, 2, 0, 8, 8, 5, 4, 1, 1, 4, 0, 3, 3, 7])%
Test Accuracy: tensor([6, 1, 6, 2, 1, 9, 2, 8, 6, 1, 9, 5, 2, 5, 4, 4, 2, 8, 3, 8, 2, 4, 5, 0,
3, 1, 7, 7, 5, 7, 9, 7, 1, 9, 2, 1, 4, 2, 9, 2, 0, 4, 9, 1, 4, 8, 1, 8,
4, 5, 9, 8, 8, 3, 7, 6, 0, 0, 3, 0, 2, 6, 6, 4])%
Test Accuracy: tensor([9, 3, 3, 3, 2, 3, 9, 1, 2, 6, 8, 0, 5, 6, 6, 6, 3, 8, 8, 2, 7, 5, 8, 9,
6, 1, 8, 4, 1, 2, 5, 9, 1, 9, 7, 5, 4, 0, 8, 9, 9, 1, 0, 5, 2, 3, 7, 8,
9, 4, 0, 6, 3, 9, 5, 2, 1, 3, 1, 3, 6, 5, 7, 4])%
Test Accuracy: tensor([2, 2, 6, 3, 2, 6, 5, 4, 8, 9, 7, 1, 3, 0, 3, 8, 3, 1, 9, 3, 4, 4, 6, 4,
2, 1, 8, 2, 5, 4, 8, 8, 4, 0, 0, 2, 3, 2, 7, 7, 0, 8, 7, 4, 4, 7, 9, 6,
9, 0, 9, 8, 0, 4, 6, 0, 6, 3, 5, 4, 8, 3, 3, 9])%
Test Accuracy: tensor([3, 3, 3, 7, 8, 0, 8, 2, 1, 7, 0, 6, 5, 4, 3, 8, 0, 9, 6, 3, 8, 0, 9, 9,
6, 8, 6, 8, 5, 7, 8, 6, 0, 2, 4, 0, 2, 2, 3, 1, 9, 7, 5, 1, 0, 8, 4, 6,
2, 6, 7, 9, 3, 2, 9, 8, 2, 2, 9, 2, 7, 3, 5, 9])%
Test Accuracy: tensor([1, 8, 0, 2, 0, 5, 2, 1, 3, 7, 6, 7, 1, 2, 5, 8, 0, 3, 7, 2, 4, 0, 9, 1,
8, 6, 7, 7, 4, 3, 4, 9, 1, 9, 5, 1, 7, 3, 9, 7, 6, 9, 1, 3, 7, 8, 3, 3,
6, 7, 2, 8, 5, 8, 5, 1, 1, 4, 4, 3, 1, 0, 7, 7])%
Test Accuracy: tensor([0, 7, 9, 4, 4, 8, 5, 5, 4, 0, 8, 2, 1, 0, 8, 4, 5, 0, 4, 0, 6, 1, 7, 3,
2, 6, 7, 2, 6, 9, 3, 1, 4, 6, 2, 5, 4, 2, 0, 6, 2, 1, 7, 3, 4, 1, 0, 5,
4, 3, 1, 1, 7, 4, 9, 9, 4, 8, 4, 0, 2, 4, 5, 1])%
Test Accuracy: tensor([1, 6, 4, 7, 1, 9, 4, 2, 4, 1, 5, 5, 3, 8, 3, 1, 4, 5, 6, 8, 9, 4, 1, 5,
3, 8, 0, 3, 2, 5, 1, 2, 8, 3, 4, 4, 0, 8, 8, 3, 3, 1, 7, 3, 5, 9, 6, 3,
2, 6, 1, 3, 6, 0, 7, 2, 1, 7, 1, 4, 2, 4, 2, 1])%
Test Accuracy: tensor([7, 9, 6, 1, 1, 2, 4, 8, 1, 7, 7, 4, 8, 0, 7, 3, 1, 3, 1, 0, 7, 7, 0, 3,
5, 5, 2, 7, 6, 6, 9, 2, 8, 3, 5, 2, 2, 5, 6, 0, 8, 2, 9, 2, 8, 8, 8, 8,
7, 4, 9, 3, 0, 6, 6, 3, 2, 1, 3, 2, 2, 9, 3, 0])%
总结
LeNet-5在当时的手写数字识别任务中取得了很好的效果,可以达到98%以上的准确率,这是当时最先进的技术水平。它的成功证明了深度学习的潜力,吸引了更多研究者加入到深度学习的研究中。同时,LeNet-5也为后来更加复杂的卷积神经网络奠定了基础,例如AlexNet、VGG、ResNet等。这些网络都采用了类似LeNet-5的卷积神经网络结构,但增加了更多的层数和参数,从而在图像分类、目标检测等任务中取得了更好的效果。虽然LeNet-5在当今深度学习的发展中已经不再是最先进的技术,但它的经典结构和训练方法仍然对深度学习的发展和应用有重要意义。
LeNet 的卷积 (Convolution) 机制:
权值共享 (Weight Sharing):
- 同一个卷积核(过滤器)会在整张图像上滑动。这意味着,无论数字出现在图像的哪个位置,只要它的局部特征(比如一个圆弧)匹配了这个卷积核,就会被激活。(局部性)
平移不变性 (Translation Invariance): 这是 LeNet 解决手写识别最关键的特性。它让模型明白:“不管‘5’写在哪,它都是‘5’”。这极大地减少了参数量,提高了模型的鲁棒性。
LeNet成功公式:
