
大语言模型架构 - 概述
概述
凭借着庞大的参数量和丰富的训练数据,大语言模型不仅展现出了强大的泛化能力,还催生了新智能的涌现,勇立生成式人工智能(Artificial Intelligence Generated Content,AIGC)的浪潮之巅。
大数据+ 大模型→ 能力增强
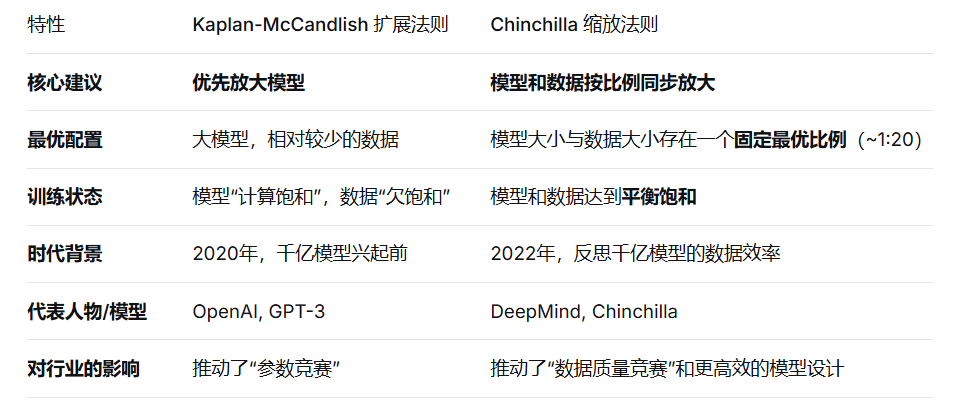
Kaplan-McCandlish 扩展法则和 Chinchilla 扩展法则是指导大规模语言模型(LLM)训练时如何平衡模型参数量(N)和训练数据量(D)的两个关键经验法则。它们都试图回答同一个核心问题:为了最有效地利用计算资源,当增加模型大小时,应该增加多少训练数据?
Kaplan-McCandlish 扩展法则
为了达到最优模型性能,数据集的规模D以及模型规模N都应同步增加。在模型规模上的投入应当略高于数据规模上的投入。在计算预算固定的情况下,应该优先扩大模型规模,而不是数据集大小。
Chinchilla 扩展法则
数据集量D与模型规模N几乎同等重要,模型规模和数据规模应该以相同的比例增加。对于一个给定的计算预算,存在一个最优的模型参数量和训练数据量的组合。单纯地放大模型而忽视数据量是低效的。
总结
两者对比:
大数据+ 大模型→ 能力扩展
大语言模型能力随模型规模涌现:
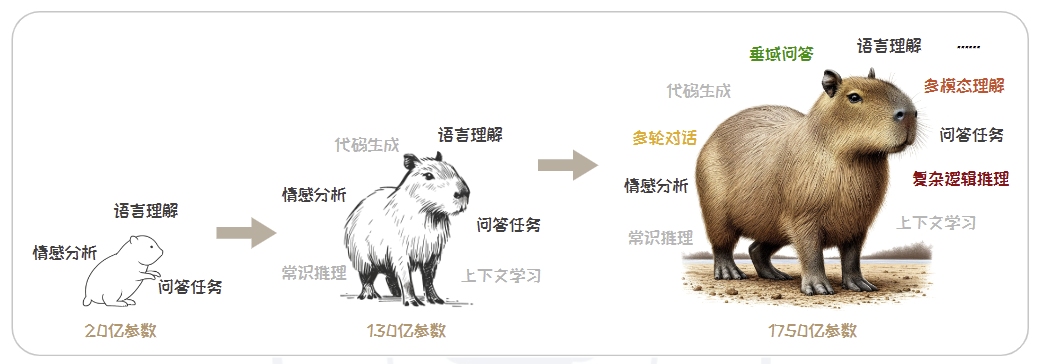
典型的涌现能力包括:
- 上下文学习
- 指大语言模型在推理过程中,能够利用输入文本的上下文信息来执行特定任务的能力。
- 具备了上下文学习能力的模型,在很多任务中无需额外的训练,仅通过示例或提示即可理解任务要求并生成恰当的输出。
- 常识推理
- 赋予了大语言模型基于常识知识和逻辑进行理解和推断的能力。
- 代码生成
- 允许大语言模型基于自然语言描述自动生成编程代码。
- 逻辑推理
- 使大语言模型能够基于给定信息和规则进行合乎逻辑的推断和结论。