
锚框(anchor box)
一类目标检测算法是基于锚框:
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
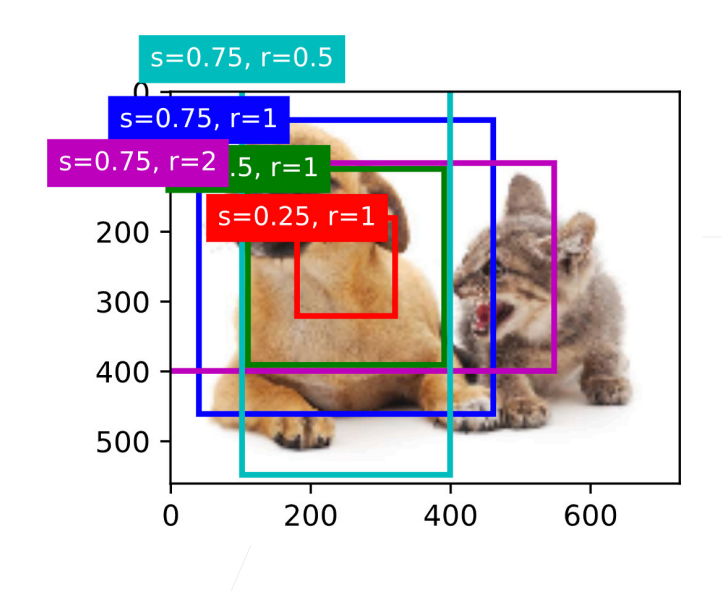
例如,如下图所示:S (缩放因子)、R (宽高比)
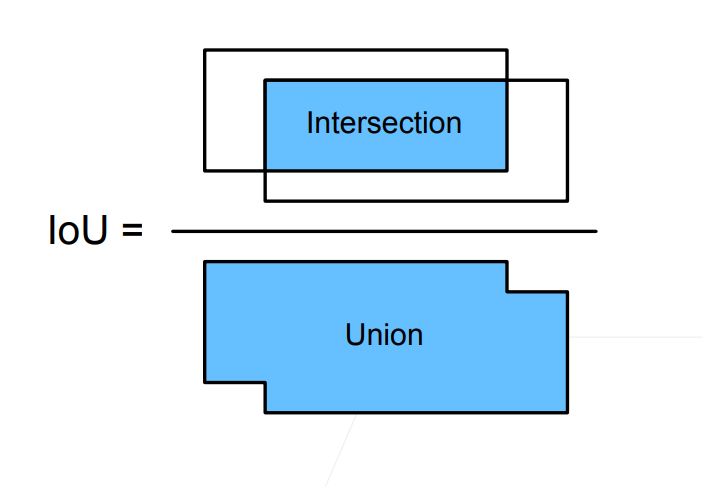
IoU-交并比
IoU 用来计算两个框之间的相似度
- 0 表示无重叠,1 表示重合
这是 Jacquard 指数的一个特殊情况
- 给定两个集合 A 和 B
- J(A,B) = |A ∩ B| / | A U B |
- 给定两个集合 A 和 B
赋予锚框标号
- 每个锚框是一个训练样本
- 将每个锚框,要么标注成背景,要么关联上一个真实边缘框
- 可能会生成大量的锚框
- 这个导致大量的负类样本
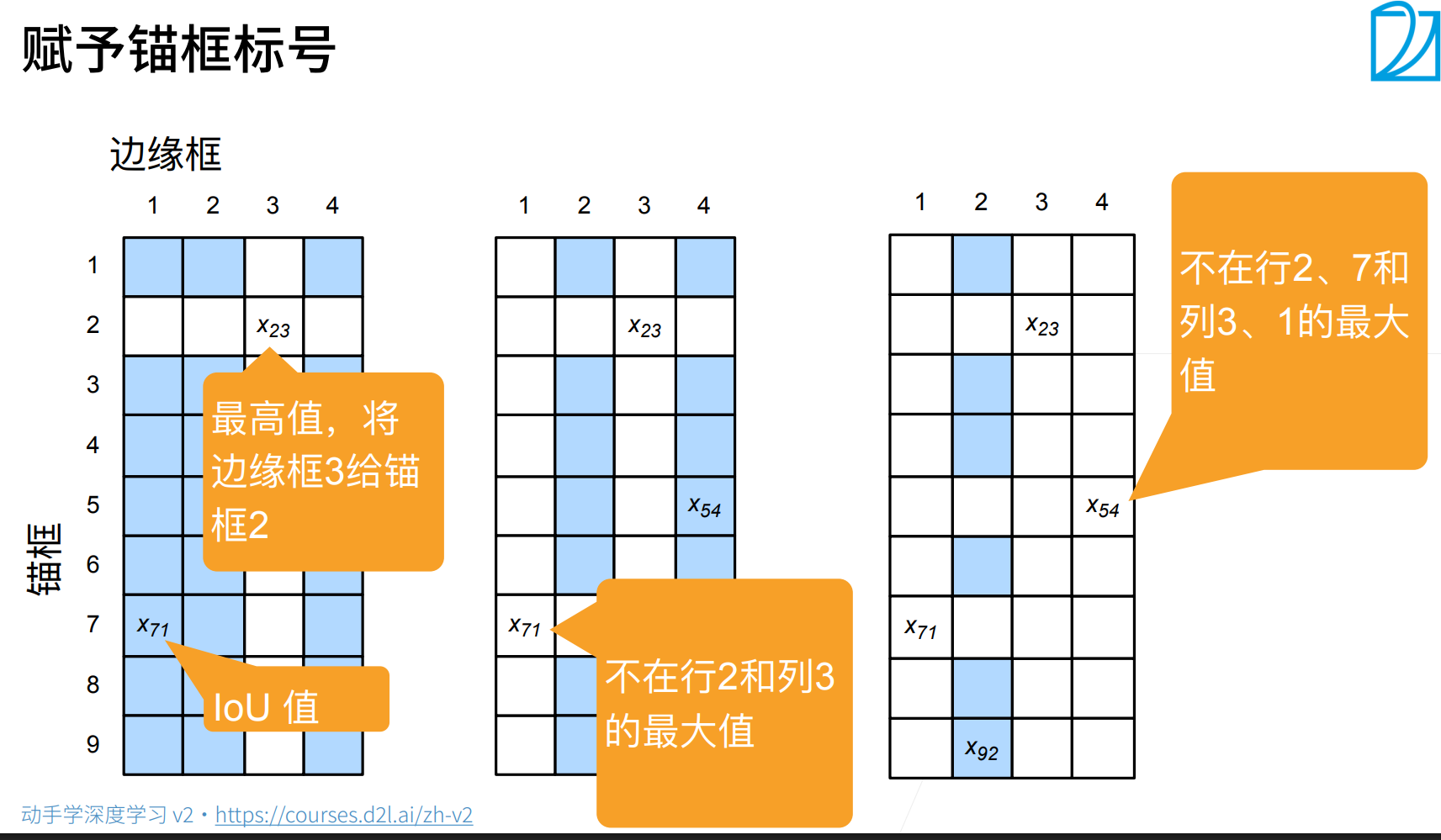
图表基本元素解读
行(Rows, 1-9):代表 锚框 (Anchors)。假设我们在图像上生成了 9 个候选锚框。
列(Columns, 1-4):代表 真实框/边缘框 (Ground Truth Boxes)。假设图像中有 4 个真实物体。
单元格内的值 ( xij ):代表第 i 个锚框和第 j 个真实框之间的 IoU (Intersection over Union,交并比)。
- IoU 越高,说明这个锚框和真实物体重合度越好,越适合用来预测该物体。
- 蓝色背景表示 IoU 较高(候选者),白色表示 IoU 较低。
橙色气泡:解释每一步的操作逻辑。
第一步:为每个真实框找到“最佳拍档”
- 操作:看每一列(每一个真实框),找出 IoU 最大的那个锚框。
- 图示解析(左图):
- 看第 3 列(真实框 3):发现 x23 (第 2 行第 3 列)的值最大。
- 结论:将 真实框 3 分配给 锚框 2。
- 意义:确保每个真实物体都有一个“正样本”锚框来学习,这是检测的基础。如果不这样做,某些难检测的物体可能没有锚框去拟合它。
第二步:为剩余的最佳匹配寻找归属(排除已分配的)
- 操作:在剩下的未分配关系中,继续找最大值,但要避开刚才已经分配过的行和列。
- 图示解析(中图):
- 刚才锚框 2 已经被占用了(对应真实框 3),所以不能再选第 2 行。
- 真实框 3 也已经有主了,所以不能再选第 3 列。
- 在剩下的格子里找最大值,发现了 x71 (第 7 行第 1 列)。
- 结论:将 真实框 1 分配给 锚框 7。
- 注意:图中的文字“不在行 2 和列 3 的最大值”就是指这个排除逻辑。
第三步:重复上述过程,直到无法匹配或达到阈值
- 操作:继续排除已占用的行(2, 7)和列(3, 1),在剩余空间找最大值。
- 图示解析(右图):
- 排除掉行 2、7 和列 3、1。
- 发现 x54x54 (第 5 行第 4 列)是剩余中的最大值。
- 结论:将 真实框 4 分配给 锚框 5。
- 最后还剩下一个 x92x92 ,但因为真实框 2 还没有被分配(或者根据具体算法策略,可能作为负样本或忽略),这里展示了继续寻找的过程。
这张图形象地解释了如何从成千上万个候选锚框中,挑选出最优秀的几个来代表真实物体。
- 输入:所有锚框与所有真实框的 IoU 矩阵。
- 逻辑:贪心算法,优先满足“每个真实框都有人管”,同时避免“一个人管多个事”。
- 输出:确定了哪些锚框是正样本(需要学习预测物体),哪些是负样本(需要学习预测背景)。
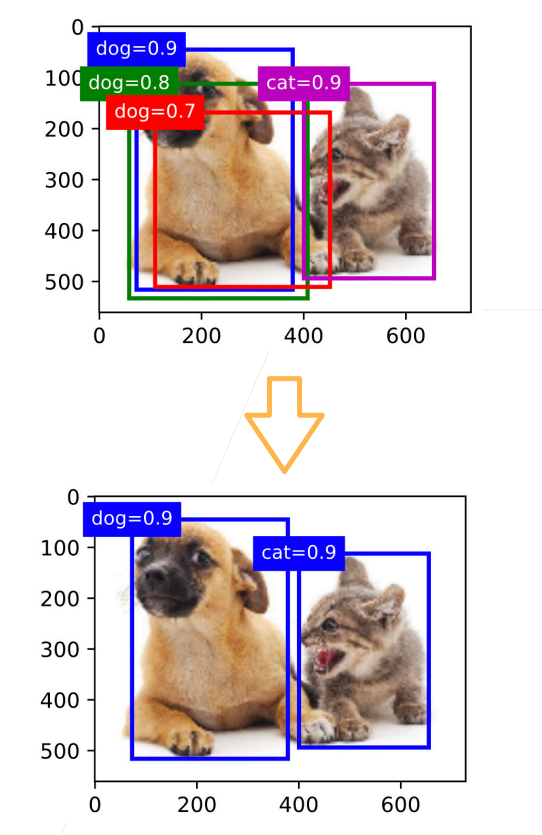
使用非极大值抑制(NMS)
- 每个锚框预测一个边缘框
- NMS 可以合并相似的预测输出
- 选中是非背景类的最大预测值
- 去掉所有其它和它 IoU 值大于 θ 的预测
- 重复上述过程直到所有预测要么被选中,要么被去掉
总结
- 一类目标检测算法基于锚框来预测;
- 首先生成大量锚框,并赋予标号,每个锚框作为一个样本进行训练;
- 在预测时,使用 NMS 来去掉冗余的预测。