
Dropout
问题背景:为什么需要 Dropout?
在深度学习模型中,过拟合(Overfitting) 是一个常见问题,即模型在训练集上表现很好,但在测试集上泛化能力差。传统解决方法包括:
- L1/L2 正则化(限制权重大小)
- 早停(Early Stopping)
- 数据增强(Data Augmentation)
但深度神经网络(DNN)由于参数众多,仍然容易过拟合。2012年,Hinton 团队提出 Dropout,通过随机“关闭”神经元来增强模型鲁棒性。
Dropout 的核心思想
Dropout 的核心思想是:在训练时,随机丢弃一部分神经元的输出,迫使网络不依赖任何单个神经元,从而提高泛化能力。
训练阶段
对于每一层(或指定层)的每一个神经元,在每一次前向传播(Forward Pass)时:
- 生成掩码:以概率 (丢弃率,例如 0.5)将该神经元的输出置为 0。
- 缩放(Scaling):为了保持输出的期望值不变,通常将剩余神经元的输出除以 。
- 注:有些框架(如 PyTorch 的
nn.Dropout)在训练时直接进行缩放(Inverted Dropout),这样测试时就不需要再操作了。
- 注:有些框架(如 PyTorch 的
- 反向传播:被丢弃的神经元不参与本次的反向传播(梯度为 0),权重不更新。
测试/推理阶段 (Inference)
- 不使用 Dropout:所有神经元都参与计算。
- 无需调整权重:如果在训练时使用了“反向 Dropout”(Inverted Dropout,即训练时已经放大了激活值),测试时直接使用原始网络即可,不需要做任何修改。这保证了推理速度不受影响。
使用Dropout
通常将 Dropout 作用在隐藏全连接层的输出上
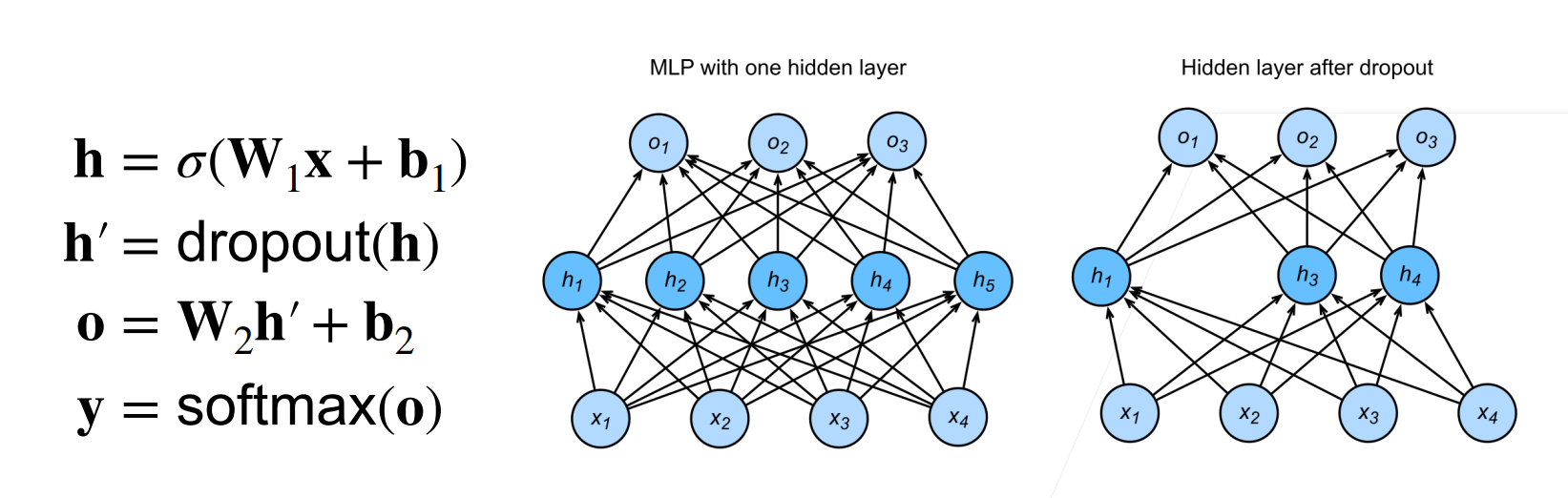
Dropout vs. 权重衰减
| 特性 | Dropout | 权重衰减 (Weight Decay) |
|---|---|---|
| 作用机制 | 随机屏蔽神经元,打破共适应。 | 惩罚大权重,限制模型复杂度。 |
| 主要效果 | 强制网络学习冗余的、鲁棒的特征。 | 使决策边界更平滑。 |
| 计算开销 | 训练时略微增加(生成掩码),推理时无开销。 | 几乎无额外开销。 |
| 适用性 | 对全连接层效果显著;CNN 中需谨慎使用。 | 通用,适用于几乎所有层。 |
| 组合使用 | 经常与权重衰减一起使用,两者互补,效果更佳。 | 常与 Dropout 搭配。 |