
模型选择
训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
验证数据集和测试数据集
- 验证数据集:一个用来评估模型好坏的数据集*
- 例如拿出50%的训练数据
- 不要跟训练数据混在一起(常犯错误)
- 测试数据集:只用一次的数据集。
- 例如:未来的考试
- 我出价的房子的实际成交价
- 用在 Kaggle 私有排行榜中的数据集
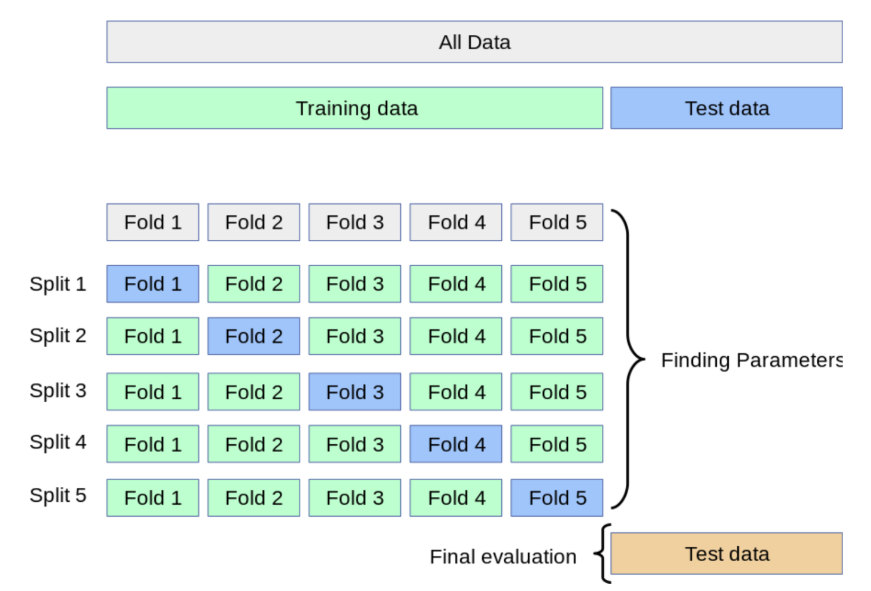
K-折交叉验证
K折交叉验证(K-Fold Cross-Validation)是一种评估机器学习模型性能的重采样方法。它通过将原始训练数据划分为 K 个相等的子集(fold),反复训练和验证模型,从而更稳定、更可靠地评估模型在未知数据上的泛化能力。
算法:
- 将训练数据分害割成K块
- For i= l, ..., K
- 使用第i块作为验证数据集,其余的作为训练数据集
- 报告K个验证集误差的平均
总结
训练数据集:训练模型参数
- 作用:用来“学习”模型的内部参数(例如神经网络的权重、线性回归的系数等)。
- 过程:模型在训练集上通过优化算法(如梯度下降)最小化损失函数,从而调整参数以拟合数据。
验证数据集:选模型超参数
- 超参数(Hyperparameters):不是通过训练学出来的,而是人为设定的。
- 学习率
- 网络层数/每层神经元数
- 正则化强度(如 L1/L2 的 λ)
- 决策树的最大深度
- 作用:在训练多个不同超参数配置的模型后,用验证集评估哪个配置泛化能力最好,从而选出最优超参数组合。
- 超参数(Hyperparameters):不是通过训练学出来的,而是人为设定的。
非大数据集上通常使用K-折交叉验证
- 让每一份数据都既当过训练集,也当过验证集,充分利用有限数据,减少评估偏差。