
池化层
池化层(Pooling Layer)是卷积神经网络(CNN)中的关键组成部分,主要用于降低特征图的空间维度(下采样),从而减少计算量、控制过拟合,并提取主要特征。
核心作用
- 降维与减少计算量:通过缩小特征图的宽和高,显著减少后续层的参数数量和计算负担。
- 防止过拟合:提供一定程度的平移不变性(Translation Invariance),即当输入图像发生微小平移时,输出保持不变,从而提高模型的泛化能力。
- 提取主导特征:保留区域内最显著的特征(如最大激活值),忽略次要细节。
常见类型
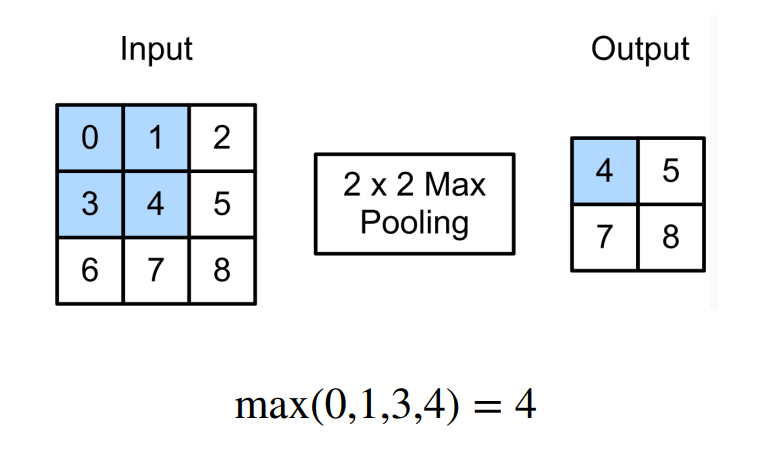
最大池化 (Max Pooling)
原理:在滑动窗口内选取最大值作为输出。
特点:最常用的池化方式。它能很好地提取纹理等显著特征,对噪声有一定的抑制作用。
示例:在一个 的窗口中,取4个数值中最大的那个。
平均池化 (Average Pooling)
- 原理:在滑动窗口内计算所有值的平均值作为输出。
- 特点:保留了背景信息,通常用于CNN的最后阶段(全局平均池化,Global Average Pooling),将特征图压缩为单个向量以替代全连接层。
其他类型
- 全局池化 (Global Pooling):将整个特征图(无论尺寸多大)压缩为 的值。常用于分类任务末尾。
- 随机池化 (Stochastic Pooling):根据数值大小的概率分布随机选择一个值,旨在引入随机性以防止过拟合(使用较少)。
工作原理与超参数
池化操作通常不涉及可学习的参数(权重),它是一个固定的数学运算。主要超参数包括:
- 池化核大小 (Kernel Size, ):通常为 或 。
- 步长 (Stride, ):通常为 。当步长等于核大小时,特征图尺寸正好减半;若步长小于核大小,则会有重叠。
- 填充 (Padding):通常不使用填充(Valid Padding),但在某些特定架构中可能会用到。
输出尺寸计算公式(假设输入尺寸为 ):
优缺点分析
- 优点:
- 大幅降低显存占用和计算时间。
- 扩大感受野(Receptive Field),让后续神经元能“看”到更大的输入区域。
- 具有平移、旋转不变性。
- 缺点/争议:
- 信息丢失:最大池化会丢弃非最大值的信息,平均池化会模糊细节。
- 现代趋势:在一些现代架构(如ResNet的某些变体、Vision Transformers)中,研究者倾向于使用**步长为2的卷积层(Strided Convolution)**来代替池化层进行下采样,因为卷积层是可学习的,能更好地保留有用信息。
5. 代码示例 (PyTorch)
import torch
import torch.nn as nn
# 定义一个最大池化层
# kernel_size=2: 窗口大小 2x2
# stride=2: 步长为2
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义一个平均池化层
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
# 模拟输入数据 (Batch_Size=1, Channels=1, Height=4, Width=4)
input_data = torch.tensor([[[[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]]]], dtype=torch.float32)
# 最大池化输出
output_max = max_pool(input_data)
print("最大池化结果:\n", output_max)
# 预期输出左上角为 6 (来自 1,2,5,6 中的最大值)
# 平均池化输出
output_avg = avg_pool(input_data)
print("平均池化结果:\n", output_avg)
# 预期输出左上角为 3.5 ( (1+2+5+6)/4 )
总结
池化层是传统CNN架构(如VGG, AlexNet)的标配,用于高效地压缩空间信息。虽然在最新的深度学习研究中,其地位有时被步长卷积所挑战,但在大多数计算机视觉任务中,它依然是一个简单且高效的工具。