
序列模型
概念
“序列模型”(Sequence Models)是一个涵盖范围很广的术语,通常指用于处理序列数据(即数据点之间存在顺序依赖关系)的机器学习模型。这类数据包括自然语言文本、时间序列(如股票价格、传感器数据)、音频信号、视频帧等。
核心应用场景
序列模型主要解决两类问题:
- 自然语言处理 (NLP):文本生成、翻译、摘要、对话系统(如大语言模型 LLMs)。
- 时间序列分析 (Time Series):金融预测、气象预报、设备故障检测、医疗数据分析。
主要模型架构演变
基于注意力机制的模型 (Transformer 架构)
- 地位:自2017年以来一直是绝对主流,是目前所有大语言模型(如GPT-5, Claude, Qwen3.5等)的基石。
- 特点:通过自注意力机制(Self-Attention)并行处理序列,捕捉长距离依赖能力极强。
- 现状:
- 多模态融合:已从纯文本扩展到“全模态实时交互”,能同时处理文本、图像、音频和视频序列。
- 推理优化:2025-2026年的重点在于提升推理效率(如混合专家模型 MoE),以及增强逻辑推理能力(如OpenAI GPT-5.1/5.2系列)。
- 局限:计算复杂度随序列长度呈平方级增长(),处理超长序列时成本高昂。
状态空间模型 (State Space Models, SSM) - 以 Mamba 为代表
- 崛起:这是2024-2026年最显著的架构突破之一,旨在解决Transformer在处理超长序列时的效率瓶颈。
- 特点:具有线性复杂度(),推理速度极快,显存占用低,特别适合处理百万级长度的序列(如长文档、基因组数据、长视频)。
- 趋势:
- Mamba + 时间序列:在时序预测领域,Mamba架构因其高效的长程记忆能力,正逐渐取代部分LSTM/GRU甚至Transformer的应用场景。
- 混合架构:许多新模型开始结合Transformer的强表达能力和Mamba的高效性(例如在某些层使用SSM,其他层使用Attention)。
传统与统计深度学习模型 (RNN, LSTM, GRU)
- 现状:虽然在通用大模型领域已被Transformer取代,但在特定时间序列任务(尤其是小样本、低延迟要求的工业控制或嵌入式设备)中仍有应用。
- 创新:将传统统计方法(如频域分析、小波变换)与深度学习结合(如频域+时序模型),在特定垂直领域(如医疗时序分类)仍能取得SOTA(最先进)效果。
扩散模型 (Diffusion Models) for Sequences
- 应用:最初用于图像生成,现已扩展到序列数据。
- 时间序列生成:用于生成高质量的合成时间序列数据(数据增强),或在缺失数据填补、概率预测方面表现优异。2025年有多篇顶会论文探讨了“扩散模型+时间序列”的结合。
早期假设
序列模型在处理序列数据时,通常会依赖于某些假设来简化问题并提高模型的可解释性和可操作性。马尔可夫模型和潜变量模型是两种常见的假设,它们分别从不同角度解释序列数据的生成过程。
马尔可夫模型(Markov Model)
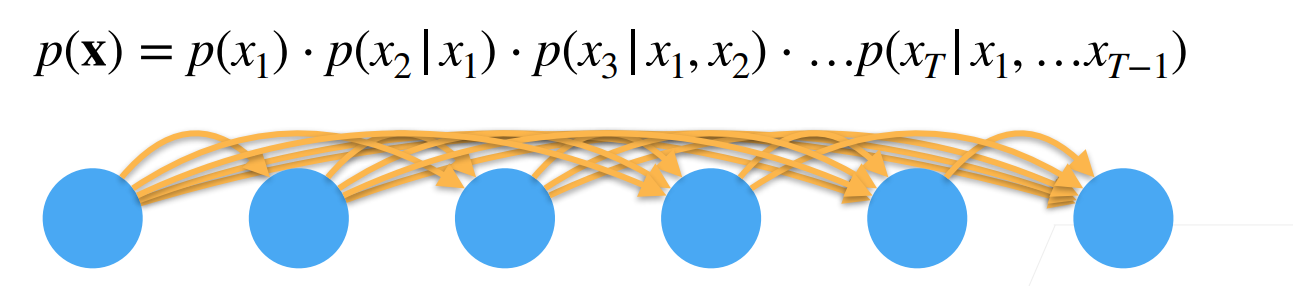
马尔可夫模型基于马尔可夫假设,通常用于描述序列数据中状态的转移过程。马尔可夫假设指出:**当前状态仅依赖于前一个状态,而与更早的状态无关。**这种假设能够有效地简化序列建模的复杂度。马尔可夫模型常用于语音识别、自然语言处理、时间序列分析等任务。
马尔可夫假设
一阶马尔可夫假设(First-order Markov assumption):当前状态 的概率仅依赖于前一时刻的状态 ,即:
二阶马尔可夫假设(Higher-order Markov assumptions):当前状态依赖于前n个状态,但通常我们简化为只依赖于一个前状态(即一阶马尔可夫假设),以降低计算复杂度。
马尔可夫链
在马尔可夫模型中,序列由一系列的状态组成,每个状态之间有一定的转移概率。这些转移概率满足马尔可夫性质,即。可以通过马尔可夫链的状态转移矩阵来描述这些转移概率。给定当前状态,未来的状态是独立于过去状态的。例如,在隐马尔可夫模型(HMM)中,状态序列(隐状态)与观测序列(观测值)之间存在转移概率和发射概率,而这些概率完全由当前时刻的状态来决定。
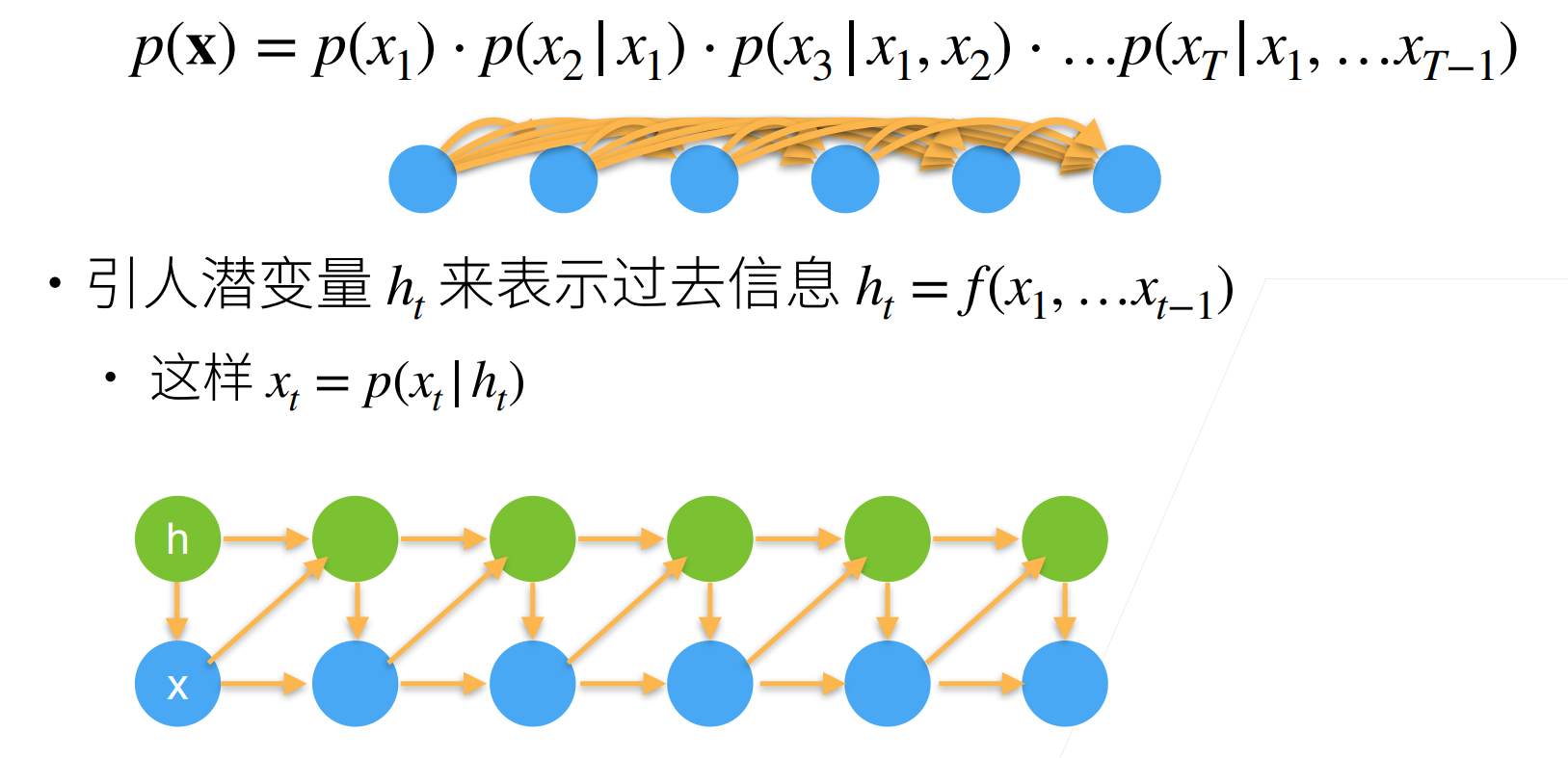
潜变量模型(Latent Variable Model)
潜变量模型假设序列中的数据是由一些不可观察(潜在)的隐藏变量和观察变量(观测数据)共同生成的。潜变量模型假设存在一些隐藏的因素或状态,这些因素通过某些机制影响观察到的序列数据。
潜变量的定义
潜变量是指在数据生成过程中影响观测结果,但在实际问题中无法直接观测到的变量。潜变量模型的目标是通过观测到的数据推断潜变量的分布,并进而推断整个数据的结构。
潜变量模型的基本框架
潜变量模型通常通过以下方式来建模:
- 潜变量与观测变量的关系:假设潜变量通过某种概率分布(如高斯分布)生成观测数据。
- 推断潜变量:基于观测数据,推断出潜在变量的分布或值。
在机器学习中,潜变量模型通常用于表示数据中的未观察到的结构或模式,并使用方法如变分推断、EM算法(期望最大化算法)来进行参数估计和推断。
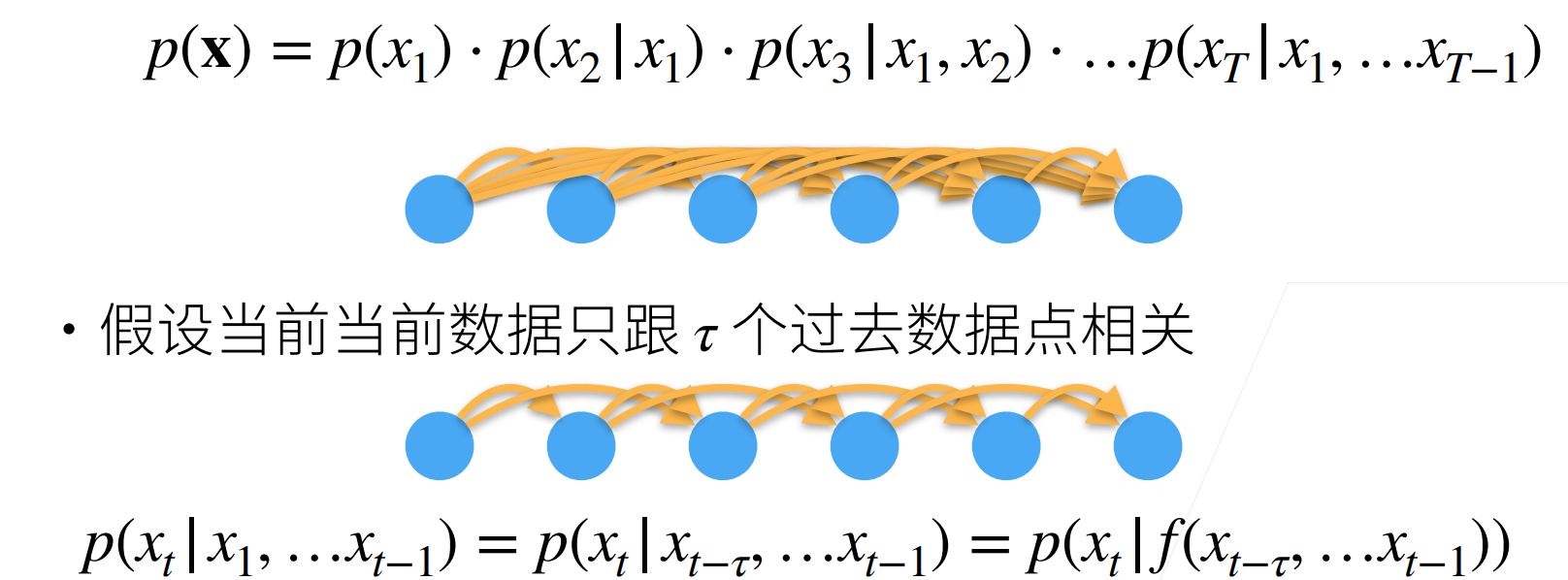
- 时序模型中,当前数据跟之前观察到的数据相关
- 自回归模型使用自身过去数据来预测未来
- 马尔可夫模型假设当前只跟最近少数数据相关,从而简化模型
- 潜变量模型使用潜变量来概括历史信息