
RAG - 知识检索
概述
在RAG 中,检索的效果(召回率、精度、多样性等)会直接影响大语言模型的生成质量。优化检索过程,提升检索的效果和效率,对改善RAG 的性能具有重要意义。
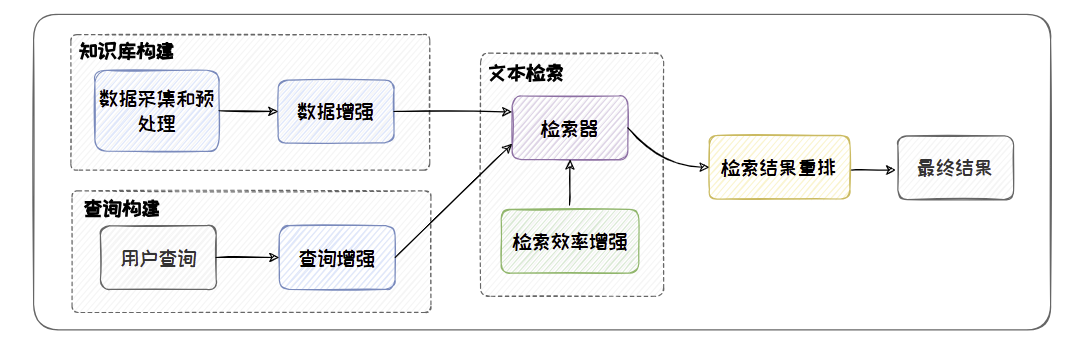
知识库构建
数据采集及预处理
数据采集
在构建文本型知识库的数据采集过程中,来自不同渠道的数据被整合、转换为统一的文档对象。这些文档对象不仅包含原始的文本信息,还携带有关文档的元信息(Metadata,例如文章标题,分类信息,时间信息,关键词)。元信息可以用于后续的检索和过滤。
数据预处理
数据预处理主要包括数据清洗和文本分块两个过程:
数据清洗:清除文本中的干扰元素,如特殊字符、异常编码和无用的HTML标签,以及删除重复或高度相似的冗余文档,从而提高数据的清晰度和可用性。
文本分块:将长文本分割成较小文本块的过程。
- 好处:
- 为了适应检索模型的上下文窗口长度限制,避免超出其处理能力
- 通过分块可以减少长文本中的不相关内容,降低噪音,从而提高检索的效率和准确性。
- 重要性:
- 文本分块的效果直接影响后续检索结果的质量
- 好处:
知识库增强
知识库增强是通过改进和丰富知识库的内容和结构,以提升其质量和实用性。这一过程通常涉及查询生成与标题生成等多个步骤,以此为文档建立语义“锚点”,方便检索时准确定位到相应文本。
- 查询生成:利用大语言模型生成与文档内容紧密相关的伪查询。
- 标题生成:利用大语言模型为没有标题的文档生成合适的标题。
查询增强
查询语义增强
查询语义增强旨在通过同义改写和多视角分解等方法来扩展、丰富用户查询的语义,以提高检索的准确性和全面性。
同义改写:通过将原始查询改写成相同语义下不同的表达方式,来解决用户查询单一的表达形式可能无法全面覆盖到知识库中多样化表达的知识。
多视角分解:采用分而治之的方法来处理复杂查询,将复杂查询分解为来自不同视角的子查询,以检索到查询相关的不同角度的信息。
同义改写
- 对于这样一个原始查询:考拉的饮食习惯是什么?
- 可以改写成下面几种同义表达:
- 考拉主要吃什么?;
- 考拉的食物有哪些?;
- 考拉的饮食结构是怎样的?
多视角分解
- 对于这样一个问题:考拉面临哪些威胁
- 可以从多个视角分解为:
- 考拉的栖息地丧失对其有何影响?
- 气候变化如何影响考拉的生存?
- 人类活动对考拉种群有哪些威胁?
每个子问题能检索到不同的相关文档,这些文档分别提供来自不同视角的信息。通过综合这些信息,语言模型能够生成一个更加全面和深入的最终答案。
查询内容增强
查询内容增强旨在通过生成与原始查询相关的背景信息和上下文,从而丰富查询内容,提高检索的准确性和全面性。与传统的仅依赖于检索的方式相比,查询内容增强方法通过引入大语言模型生成的辅助文档,为原始查询提供更多维度的信息支持。
生成背景文档是一种查询内容增强的方法。
例如,对于用户查询“如何保护考拉的栖息地?可以生成以下背景文档:
考拉是原产于澳大利亚的树栖有袋类动物,主要分布在东部和东南部沿海的桉树林中。这些地区提供了考拉主要食物来源——桉树叶。考拉的栖息地包括开阔的森林和木兰地,这里桉树丰富,不仅提供食物,还提供栖息和保护。考拉高度依赖特定种类的桉树,它们的分布与这些树木的可用性密切相关。
检索器
给定知识库和用户查询,检索器旨在找到知识库中与用户查询相关的知识文本。检索器可分为判别式检索器和生成式检索器两类。
判别式检索器
判别式检索器通过判别模型对查询和文档是否相关进行打分。判别式检索器通常分为两大类:稀疏检索器和稠密检索器。
- 稀疏检索器利用离散的、基于词频的文档编码向量进行检索。
- TF-IDF 基于词频(TF)和逆文档频率(IDF)来衡量词语在文档或语料库中的重要性,然后用此重要性对文本进行编码。
词频(TF)= 某个词在文档中出现的次数 / 文档的总词数
逆文档频率(IDF)=log( 语料库的文档总数 / 包含该词的文档数 + 1)
TF−IDF(t,d,D) = TF(t,d)× IDF(t,D)
TF-IDF 通过高词频和低文档频率产生高权重,倾向于过滤常见词语,保留重要词语。
- 稠密检索器则利用神经网络生成的连续的、稠密向量对文档进行检索。(一般利用预训练语言模型对文本生成低维、密集的向量表示,通过计算向量间的相似度进行检索。)
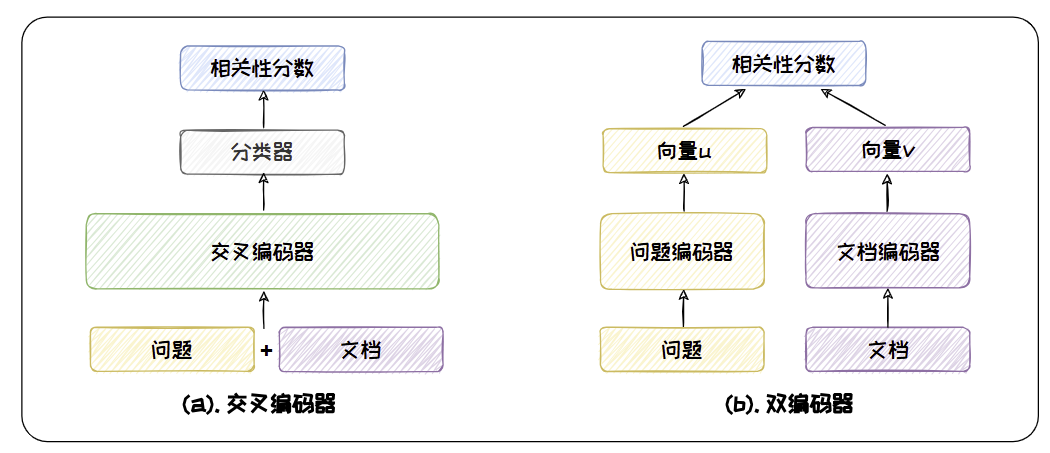
生成式检索器
生成式检索器通过生成模型对输入查询直接生成相关文档的标识符。与判别式检索器不断地从知识库中去匹配相关文档不同,生成式检索器直接将知识库中的文档信息记忆在模型参数中。然后,在接收到查询请求时,能够直接生成相关文档的标识符(即 DocID),以完成检索 。
检索效率增强
知识库中通常包含海量的文本,对知识库中文本进行逐一检索缓慢而低效。为提升检索效率,可以引入向量数据库来实现检索中的高效向量存储和查询。向量数据库的核心是设计高效的相似度索引算法。
相似度索引算法
在向量检索中,常用的索引技术主要分成三大类:基于空间划分的方法、基于量化方法和基于图的方法。
- 基于空间划分的方法
- 将搜索空间划分为多个区域来实现索引,主要包括基于树的索引方法和基于哈希的方法两类。
- 基于乘积量化的方法 通过将高维向量空间划分为多个子空间,并在每个子空间中进行聚类得到码本和码字,以此作为构建索引的基础。
- 基于图的方法
- 通过构建一个邻近图,将向量检索转化为图的遍历问题。
检索结果重排
基于交叉编码器架构的重排序技术
- 利用交叉编码器(Cross-Encoders)来评估文档与查询之间的语义相关性。该架构的核心创新在于对查询和候选文档进行联合编码处理,从而能够捕获传统方法无法识别的复杂语义交互模式。
基于大型语言模型的重排序技术
- 通过设计精巧的Prompt,使用大语言模型来执行重排任务。这种方法可以利用大语言模型优良的深层语义理解能力,从而取得了良好的表现。