
大语言模型架构 - Encoder-Decoder
概述
编码器部分与Encoder-only 架构中的编码器相同,由多个编码模块堆叠而成,每个编码模块包含一个自注意力模块以及一个全连接前馈模块。模型的输入序列在通过编码器部分后会被转变为固定大小的上下文向量,这个向量包含了输入序列的丰富语义信息。解码器同样由多个解码模块堆叠而成,每个解码模块由一个带掩码的自注意力模块、一个交叉注意力模块和个全连接前馈模块组成。其中,带掩码的自注意力模块引入掩码机制防止未来信息的“泄露”,确保解码过程的自回归特性。
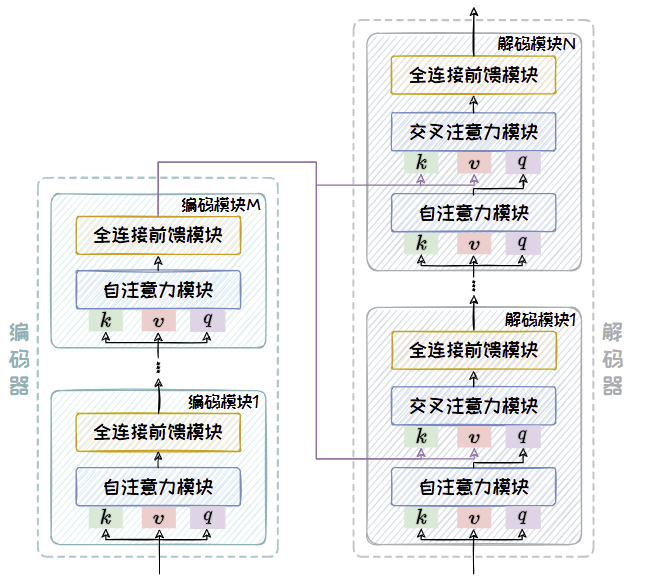
通过自注意力和交叉注意力机制的结合,Encoder-Decoder 架构能够高效地编码输入信息并生成高质量的输出序列。
T5模型
T5,全称为 Text-To-Text Transfer Transformer,是 Google 在 2019 年提出的一个具有里程碑意义的 NLP 模型。它的核心思想非常强大且统一:将所有 NLP 任务都重构为“文本到文本”的形式。
核心思想:统一的文本到文本框架
在 T5 之前,不同的 NLP 任务有不同的模型架构和输出形式:
- 分类任务:输出一个类别标签。
- 翻译任务:输出另一种语言的序列。
- 摘要任务:输出一个缩短的序列。
T5 打破了这种界限。它提出,每一个任务都可以被看作是从一段输入文本生成另一段输出文本。
这意味着:
- 输入:总是字符串。
- 输出:也总是字符串。
为了实现这一点,T5 在输入文本前加上一个任务前缀,来告诉模型需要执行什么任务。
举例说明:
| 任务 | 输入文本 | 输出文本 |
|---|---|---|
| 翻译 | translate English to German: That is good. | Das ist gut. |
| 情感分析 | cola sentence: The course is jumping well. | not acceptable |
| 摘要 | summarize: state authorities ... | California is ... |
| 语义相似度 | stsb sentence1: The bird is bathing. sentence2: The bird is in the water. | 3.8 (即使是数字也作为字符串输出) |
| 文本蕴含 | mnli premise: I hate pigeons. hypothesis: My feelings towards pigeons are filled with animosity. | entailment |
这种统一的框架使得一个单一的模型就可以处理各种各样、看似不相关的任务。
模型架构
T5 的模型架构基于经典的 Transformer 模型,具体来说是 编码器-解码器 结构。
像其他大型模型一样,T5 也有一系列不同规模的变体,以在效率和性能之间取得平衡。
| 模型变体 | 参数量 | 编码器层数 | 解码器层数 | 注意力头数 | 隐藏层维度 |
|---|---|---|---|---|---|
| T5-Small | 60 million | 6 | 6 | 8 | 512 |
| T5-Base | 220 million | 12 | 12 | 12 | 768 |
| T5-Large | 770 million | 24 | 24 | 16 | 1024 |
| T5-3B | 3 billion | 24 | 24 | 32 | 1024 |
| T5-11B | 11 billion | 24 | 24 | 128 | 1024 |
此外,后续还出现了一些重要的改进版本:
- mT5:多语言 T5,在涵盖 100 多种语言的 Common Crawl 数据上预训练,支持跨语言任务。
- ByT5:一个基于字节(Byte)级别的 T5 模型,不依赖分词器,对所有语言都更加公平,尤其在处理生僻字、表情符号和拼写错误方面表现更好。
- Flan-T5:指令微调 版本的 T5。它在包含大量指令任务的数据集上进行了进一步的微调,使其在零样本和少样本学习能力上大幅提升,能更好地理解和遵循人类的指令。Flan-T5 是目前最常用、性能最好的 T5 变体之一。
优势与特点
- 统一性:一套模型、一套代码可以解决多种问题,极大地简化了研究和工程部署。
- 简洁性:输入输出格式的统一使得数据处理和模型接口设计变得非常简单。
- 强大的性能:在发布时,T5 在 GLUE、SuperGLUE 等多个 NLP 基准测试上取得了领先水平。
- 可复现性与开放性:Google 不仅发布了论文,还开源了代码、预训练模型和 C4 数据集,对整个社区的发展起到了巨大的推动作用。