
Prompt工程 - 工程简介
概述
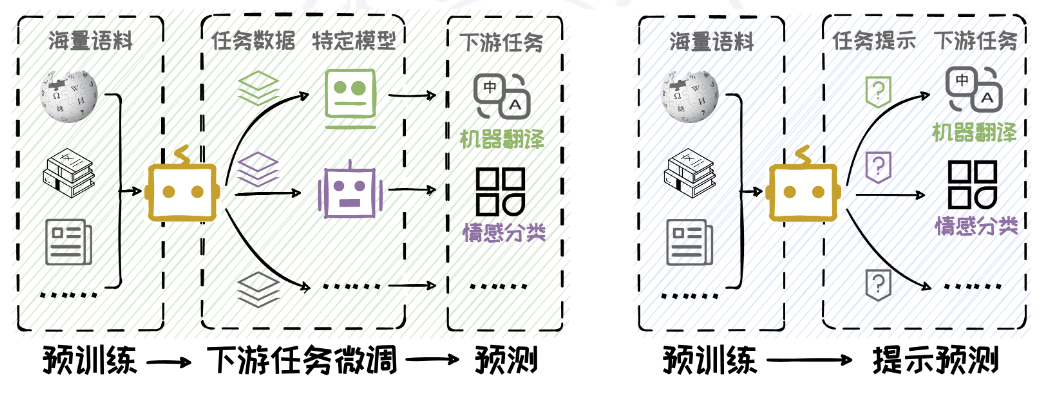
传统的自然语言处理研究遵循“预训练-微调-预测”范式,即先在大规模语料库上作预训练,然后在下游任务上微调,最后在微调后的模型上进行预测。随着语言模型在规模和能力上的显著提升,一种新的范式——**“预训练-提示预测”**应运而生,即在预训练模型的基础上,通过精心设计Prompt 引导大模型直接适应下游任务,而无需进行繁琐微调,如图所示。
定义
Prompt 是指用于指导生成式人工智能模型执行特定任务的输入指令,这些指令通常以自然语言文本的形式出现。Prompt 工程(Prompt Engineering),又称提示工程,是指设计和优化用于与生成式人工智能模型交互的Prompt 的过程。

通过Prompt 工程的优化,原始Prompt 被改写为更加全面、规范的形式。优化后的Prompt 能够显著提升模型生成回答的质量。
经过良好设计的Prompt 通常由任务说明、上下文、问题、输出格式四个基本元素组成:
- 任务说明
- 向模型明确提出具体的任务要求。任务说明应当清晰、直接,并尽可能详细地描述期望模型完成的任务。
- 上下文
- 向模型提供的任务相关背景信息,用以增强其对任务的理解以及提供解决任务的思路。上下文可以包括特定的知识前提、目标受众的背景、相关任务的示例,或任何有助于模型更好地理解任务的信息。
- 问题
- 向模型描述用户的具体问题或需要处理的信息。
- 输出格式
- 期望模型给出的回答的展示形式。这包括输出的格式,以及任何特定的细节要求,如简洁性或详细程度。
Prompt 的四个基本元素——任务说明、上下文、问题和输出格式,对于大语言模型生成的效果具有显著影响。
Prompt 分词向量化
在Prompt 进入大模型之前,需要将它拆分成一个Token 的序列,其中Token 是承载语义的最小单元,标识具体某个词,并且每个Token 由Token ID 唯一标识。将文本转化为Token 的过程称之为分词(Tokenization)。
本文将以BBPE(Byte-Level Byte Pair Encoding)算法为例,阐述其分词过程。BBPE算法的流程主要包括以下四个步骤:
- 初始化词表:将所有字符按照其底层编码拆分为若干字节,并将这些单字节编码作为初始词表的Token。
- 统计词频:统计词表中所有Token 对(即相邻Token 的组合)的出现频率。在初始阶段,Token 对即为相邻字节的组合。
- 合并高频Token对:选择出现频率最高的Token 对,将其合并成一个新的Token 并加入词表。
- 迭代合并:重复步骤2 和步骤3,不断迭代合并,直至达到预设的词表大小或达到指定的合并次数。
编码阶段(分词):
- 将输入文本按字符切分。
- 贪心地从词汇表中匹配最长可能的子词。
- 无法匹配的字符逐字节处理(BPE通常基于字节,因此能处理任何Unicode字符)。
备注:长尾词汇:“长尾”(Long Tail)是一个统计学和经济学中的概念,用来描述在某些分布中,大量不常见(低频)的个体虽然单个影响力小,但总体数量庞大,累积起来的影响力或价值可能超过少数高频个体。
在完成分词之后,这些Token 随后会经过模型的嵌入矩阵(Embedding Matrix)处理,转化为固定大小的表征向量。这些向量序列被直接输入到模型中,供模型理解和处理。
Prompt 工程的意义
Prompt 工程提供了一种高效且灵活的途径来执行自然语言处理任务。它允许我们无需对模型进行微调,便能有效地完成既定任务,避免微调带来的巨大开销。通过精心设计的Prompt,能够激发大型语言模型的内在潜力,使其在垂域任务、数据增强、智能代理等多个领域发挥出卓越的性能。
- 垂域任务
- 应用Prompt 工程来引导大语言模型完成垂直领域任务,可以避免针对每个任务进行特定微调。
- 数据增强
- 应用Prompt 工程通过大语言模型来进行数据增强,不仅能够提升现有数据集的质量,还能够生成新的高质量数据。
- 智能代理
- 应用Prompt 工程可以将大语言模型构建为智能代理(Intelligent Agent,IA),能够感知环境、自主采取行动以实现目标,并通过学习或获取知识来提高其性能。