
Transformers 神经网络图解指南:分步讲解
参考资料
解读Transfomer
一种名为Transformers的新型神经网络,它是一种基于注意力的编码器解码器类型架构。
- 编码器的输出为一个连续向量表示,该表示包含从输入学到的所有信息。
- 解码器采用连续的表示并逐步生成单个输出,同时被输入到之前的输出,直到
<end>标记生成为止。
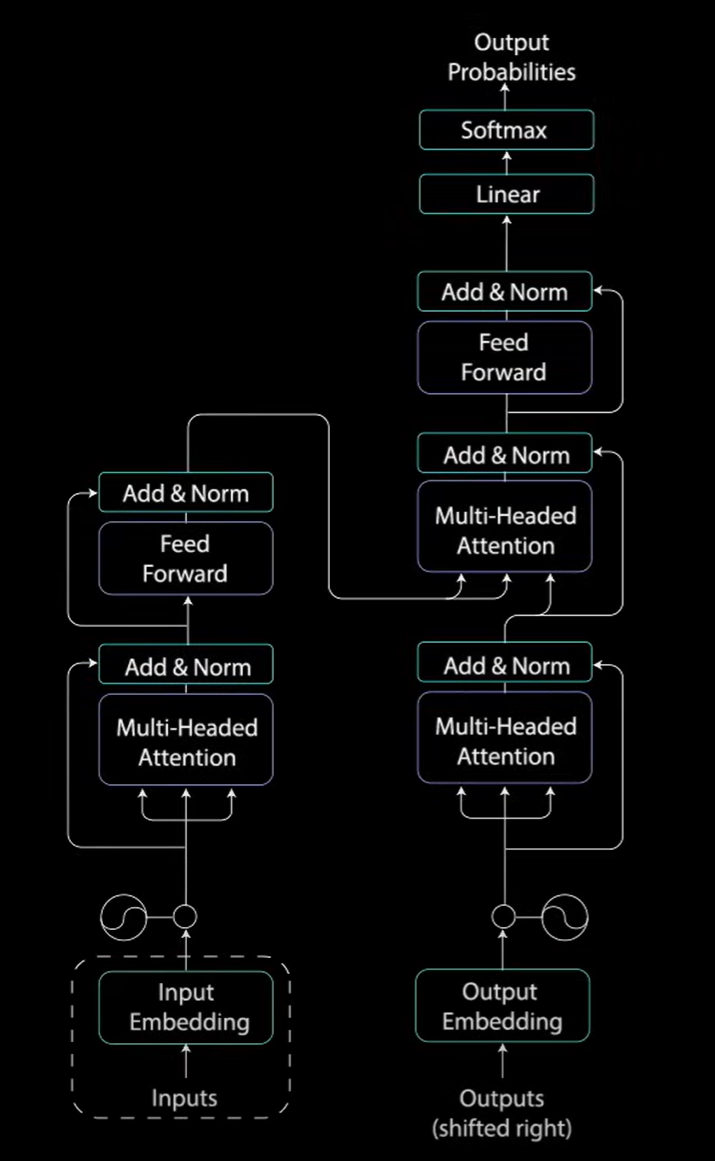
编码器
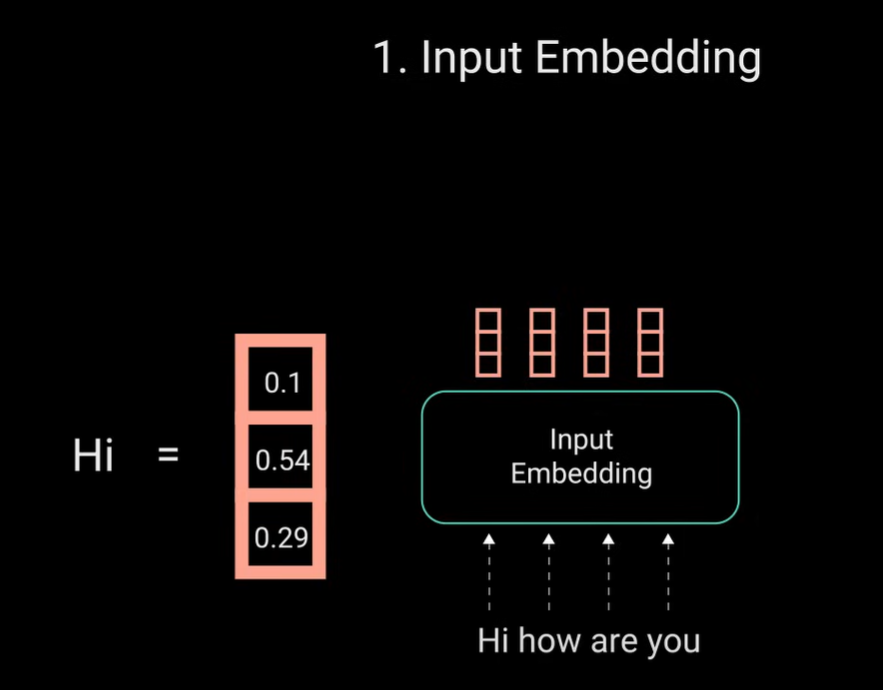
- 将Inputs信息输入到Input Embedding layer(输入词嵌入层 ),词嵌入层可被理解成一个查找表以获取每个单词表示的学习因子,然后神经网络通过学习这些数字,将每个单词映射到一个向量,该向量使用连续值表示该单词。
- 之前是通过tokenizer将句子拆分成一个个单词
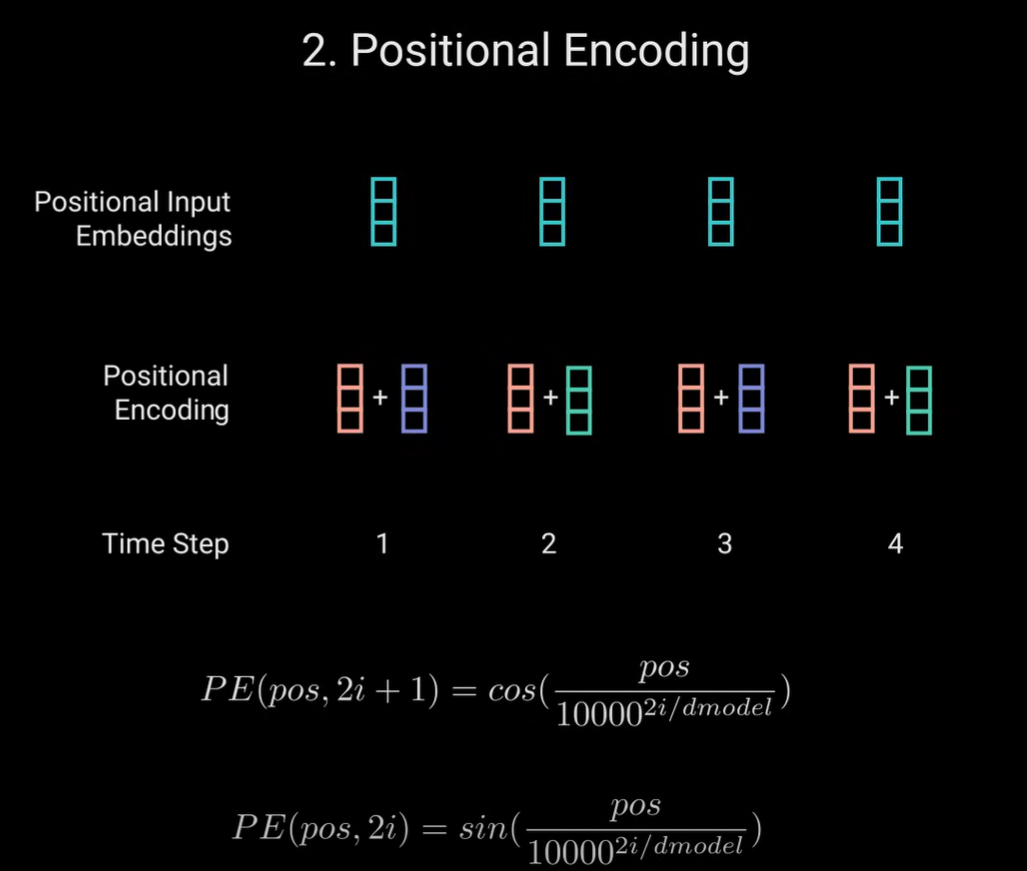
- 将位置信息加到到这些embedding向量中(使用正弦和余弦函数)
- 原因:Transformer编码器不像已知的循环网络那样具有循环的特征,所以需要将位置信息添加到输入嵌入中。
- 正弦和余弦函数具有线性模型特征
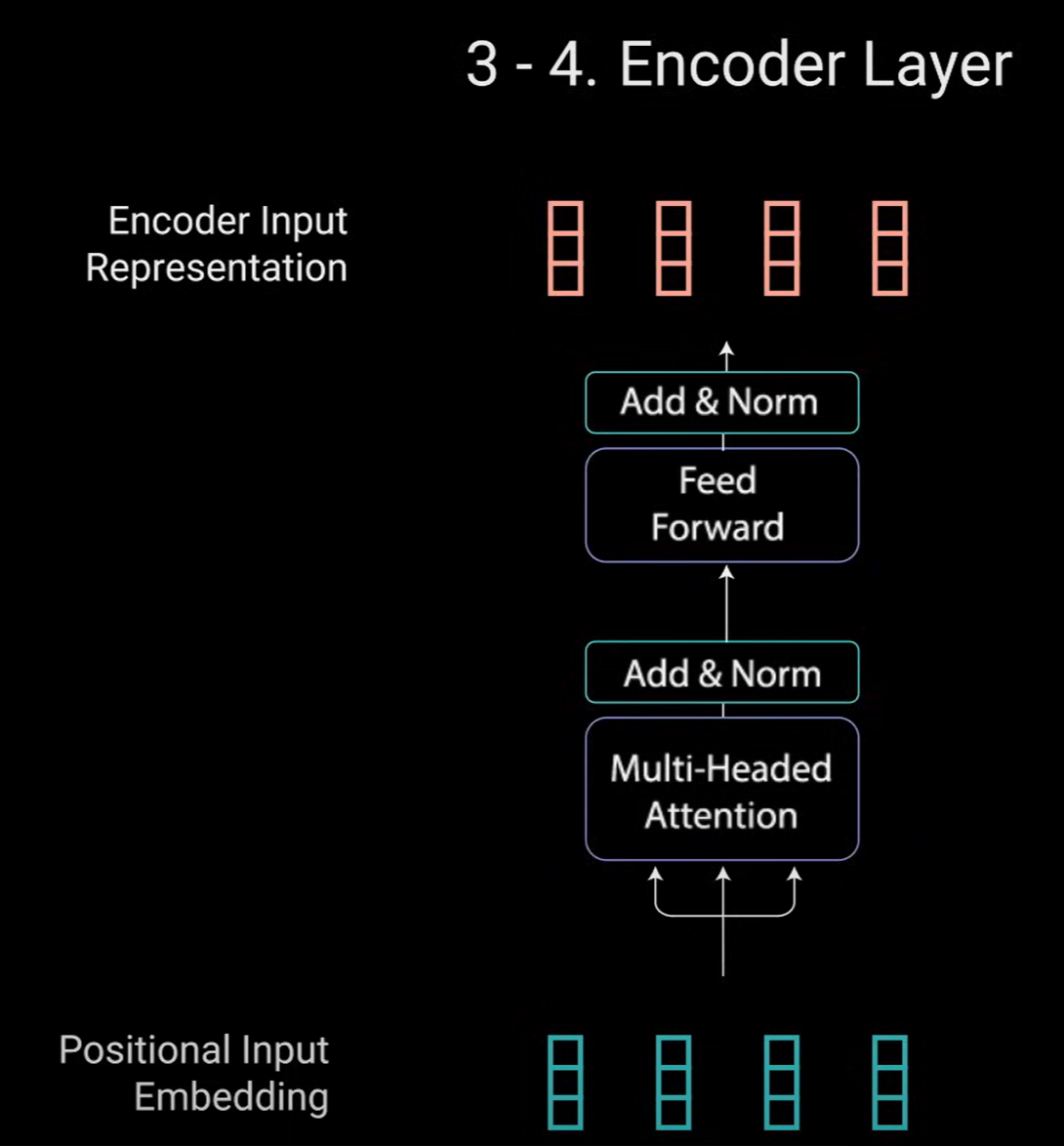
- 编码器层的工作:将所有输入序列映射到一个抽象的连续表示中,该表示保存了整个序列的学习信息,它包含两个子模块多头注意力,后跟一个完全连接的网络。两个子模块周围还有残差连接,后跟一个层归一化
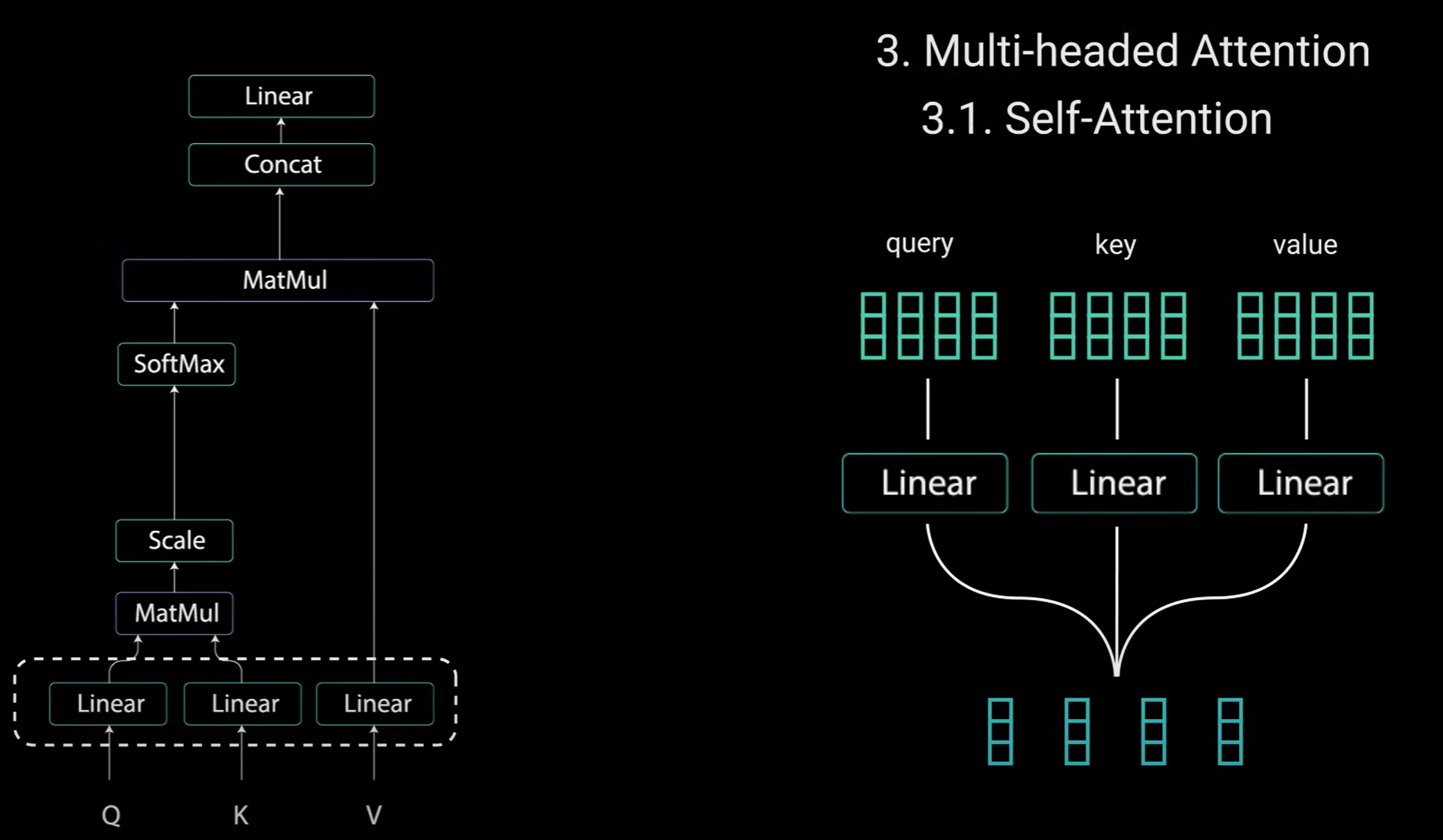
- 多头注意力(Multi-headed Attention)
- 注意力机制允许模型将输入中的每个单词与输入中其他单词相关联。例如句子(Hi how are you),模型可以学会单词you 与 how ,are的联系,学会以这种模式构造的单词。
- 需要做出适当的响应以实现自我注意力,将输入馈送到三个不同的完全连接层以创建query、key和value向量。
- query、key和value 概念来自检索系统,例如,输入query在YouTube上搜索视频时,搜索引擎会将你的查询与一组key(例如视频描述标题等)进行映射,这些key与数据库中的候选视频相关联,然后向你展现最佳匹配的视频(value)
- query和key经过点积矩阵乘法去产生一个分数矩阵(score matrix)
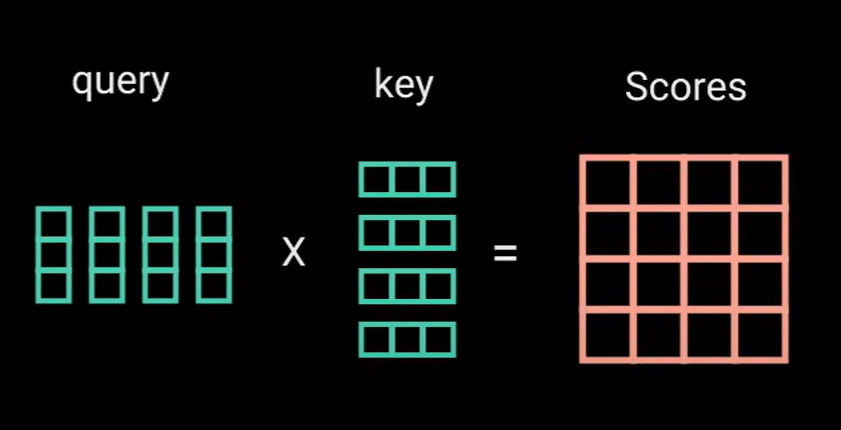
分数矩阵确定一个单词应该在其他单词上投入多少注意力。因此每个单词都会有一个分数来与时间步长中的其他单词相对应,分数越高,关注度越高。这就是query如何映射到key。

然后通过除以query和key维度的平方根缩小分数,以获得更稳定的梯度(因为query和key的矩阵乘法值可能发生爆炸效应)。
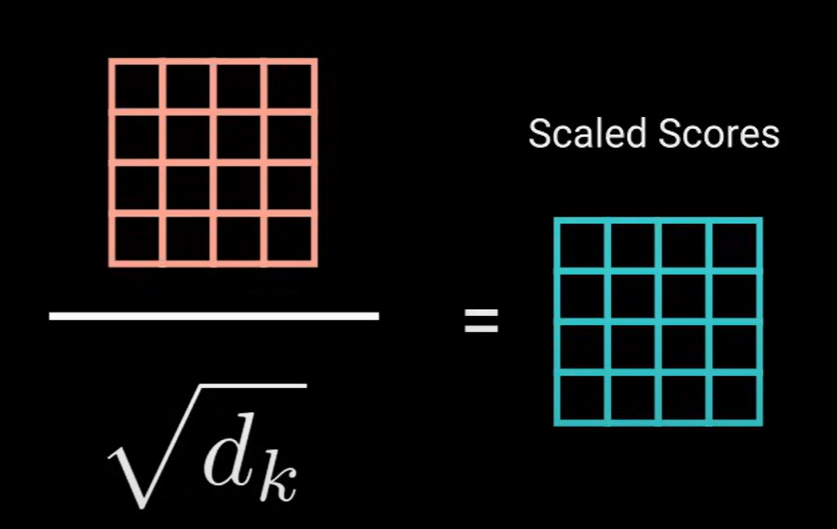
使用softmax来计算scaled_score,然后得到注意力权重,即0-1之间的概率值。
通过softmax,较高的分数会提高,较低的分数会降低,这可以让模型更有信心地关注哪些单词。

然后取获得的(attention weight)注意力权重,并乘上value向量以获得输出向量,较高的softmax分数将使模型学习的单词的值更重要,较低的分数将淹没他们的不相关单词。

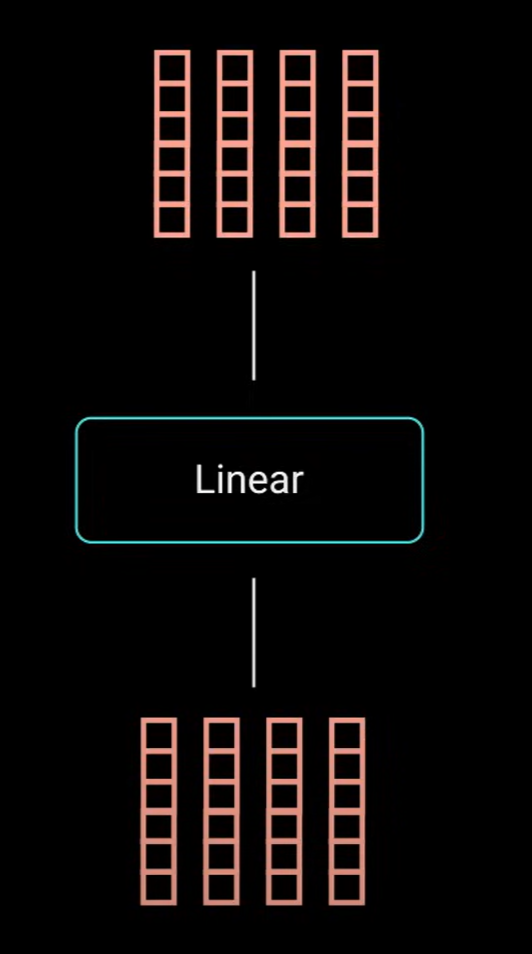
将输出向量输入到线性层进行处理。使其成为多头注意力计算,你需要将query、key和value拆分为相加向量,然后再应用自我注意力来拆分经过相同自我注意力过程的向量。
- 多头注意力的工作流程可以清晰地分为四个步骤:线性变换、分头计算、并行处理、合并输出。
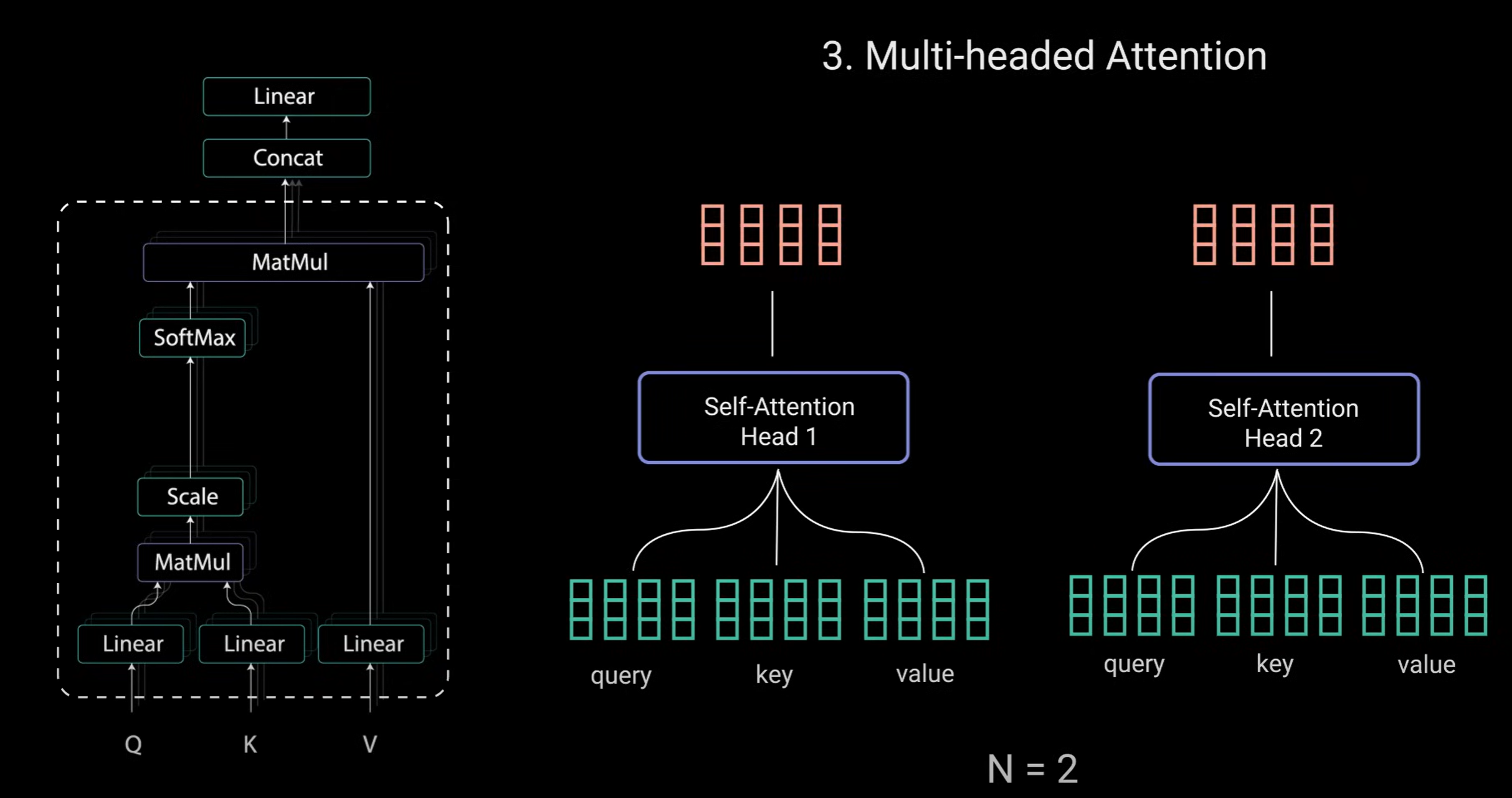
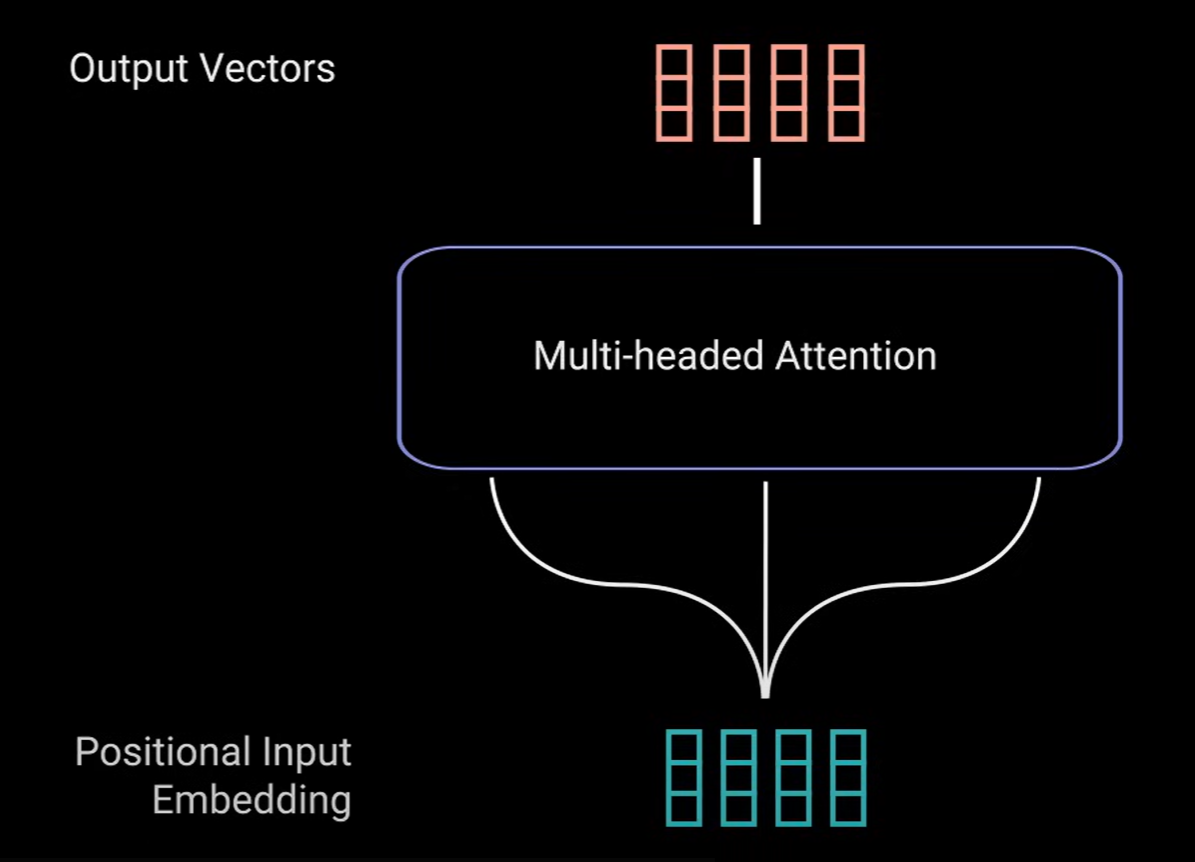
每个自我注意力过程称为头部head,每个head都会产生一个输出向量。该输出向量在经过最后的线性层之前会连接成一个向量。理论上每个head都会学习不同的东西,因此赋予模型更多的表示能力。
小结:多头注意力是Transformer网络中的一个模块,一个transformer网络:等待输入产生一个输出向量,该向量带有编码信息,说明每个单词应该如何关注序列中的所有其他单词。
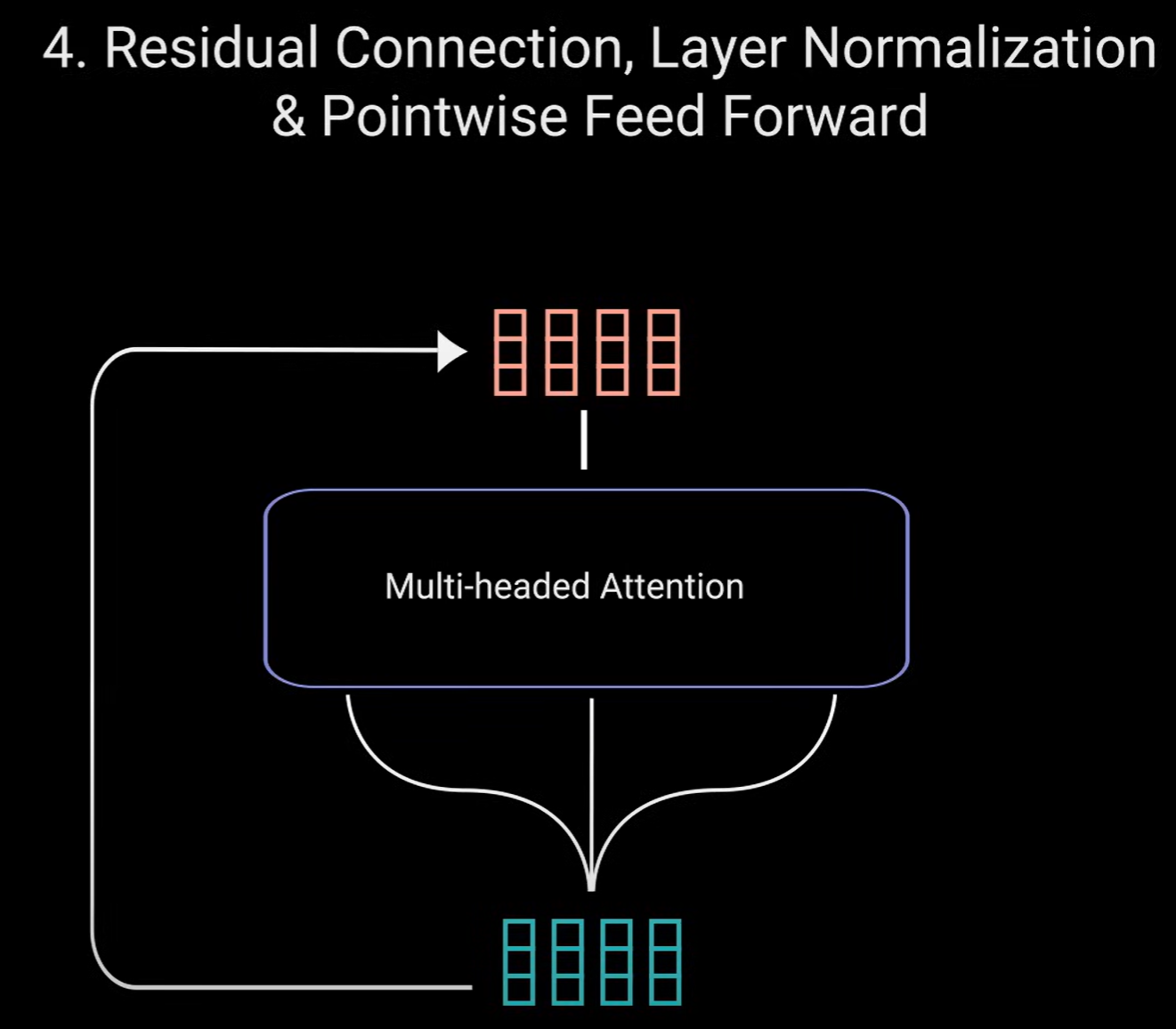
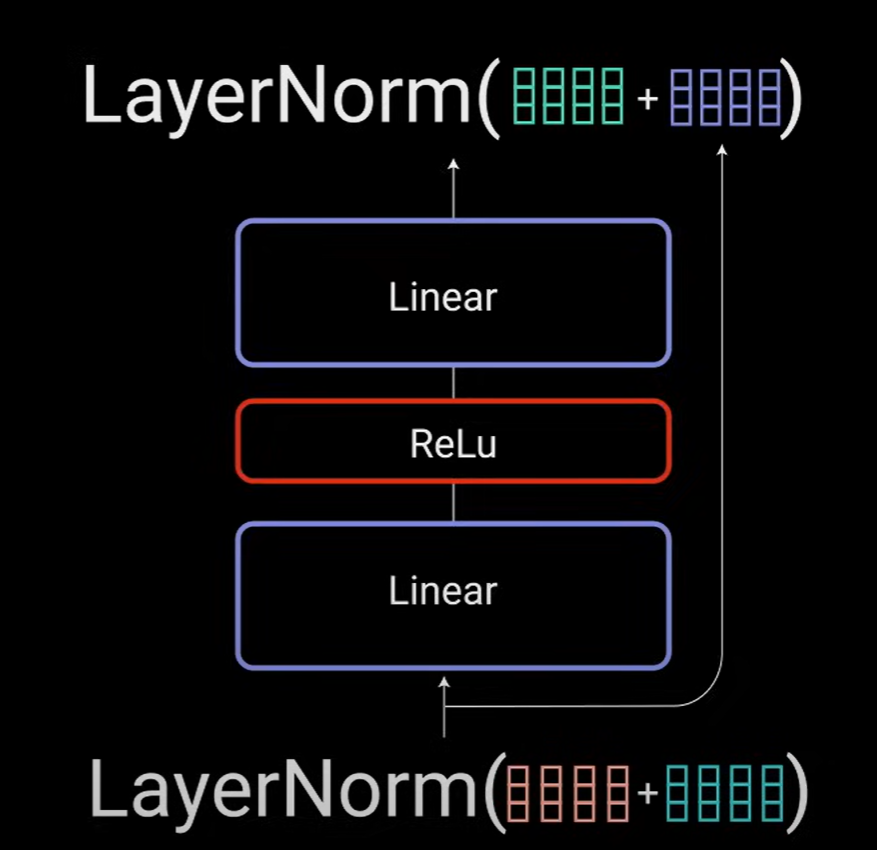
将多头注意力的输出向量添加到原始输入中,这称为残差连接,残差连接的输出经过层归一化,归一化的残差输出被馈送到逐点前馈网络中进一步处理。
逐点前馈网络是几个线性层,在输出之间有一个残余逃避(relict evasion), 再次添加到逐点前馈网络的输入中并进一步归一化。
残差连接通过允许梯度直接流过网络来帮助网络训练,层归一化用于稳定网络,从而持续产生必要的训练时间。逐点前馈层用于进一步处理注意力输出,可能使其具有更丰富的表示。
所有圈住的编码层,是为了将输入编码为具有注意力信息的连续表示,将有助于解码器在解码期间专注于输入中的适当单词的解码过程。
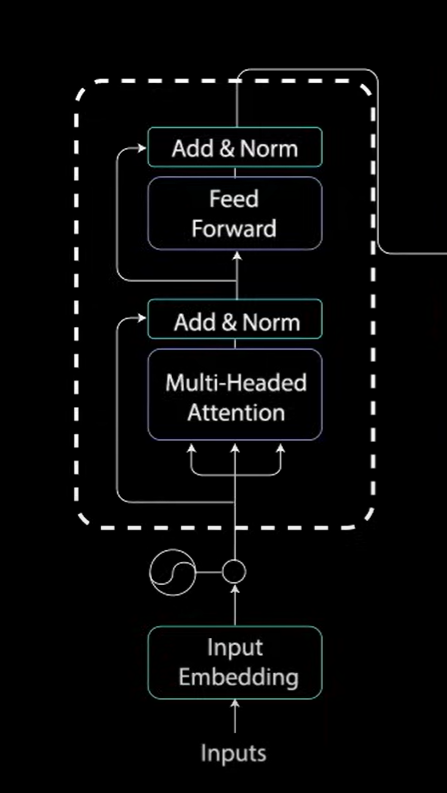
可以叠加编码器和时间来进一步编码信息,其中每一层都有机会学习不同的注意力表示,因此有可能提高Transformer网络预测的能力
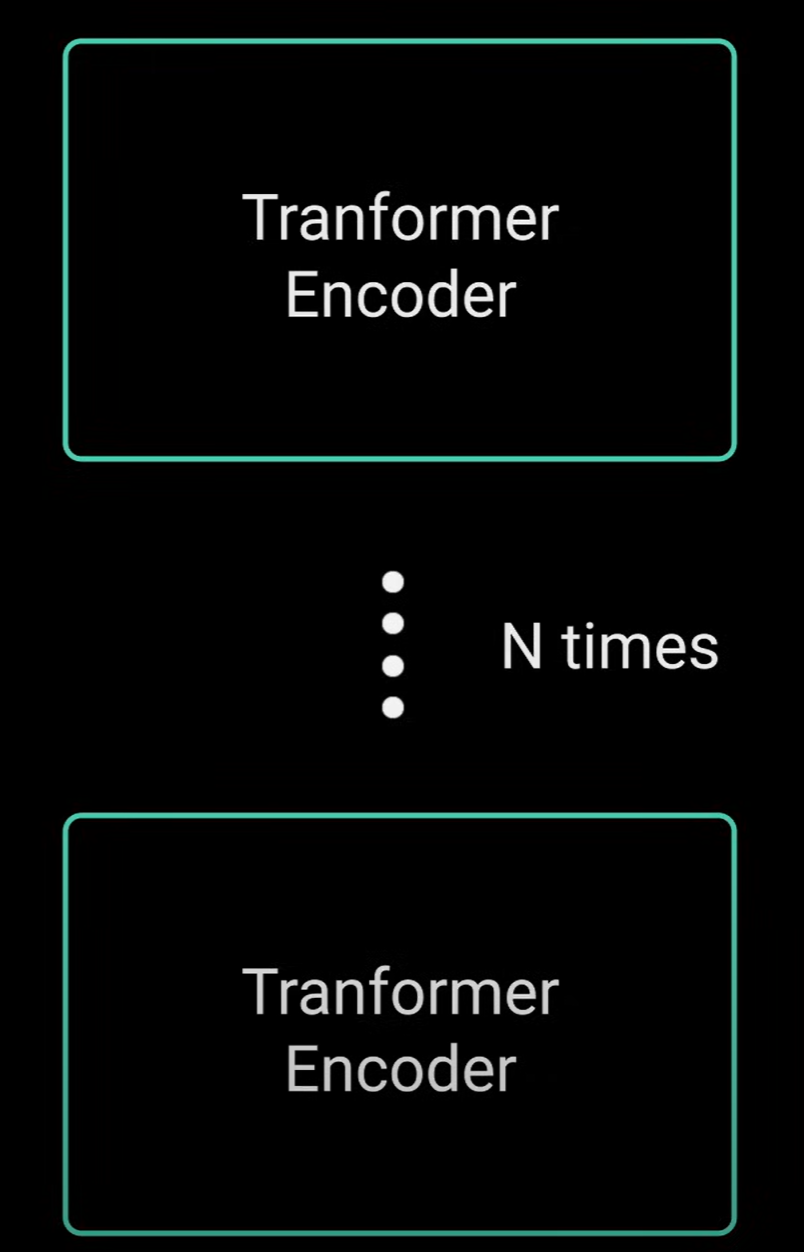
解码器
解码器的工作是生成文本。
序列解码器具有与编码器类似的子层,它有两个多头注意力层,具有残存连接的逐点前馈层和每个子层后的层归一化。这些子层的行为类似于编码器中的层,但每个多头注意力层都有不同的工作,它以一个线性层结尾,该线性层充当分类器和softmax以获取单词概率。
解码器是自回归的,它将先前的输出列表以及包含来自输入的注意力信息的编码器输出作为输入,当解码器生成结束标记作为输出时,停止解码。
输入经过编码层上的某个位置的嵌入层以获得位置嵌入,然后被输入到第一个多头注意层。该层计算解码器的注意力分数。这个多头注意力层的操作略有不同,因为解码器是**自回归?**的,并且逐字生成序列,需要防止它对未来的标记进行条件化。
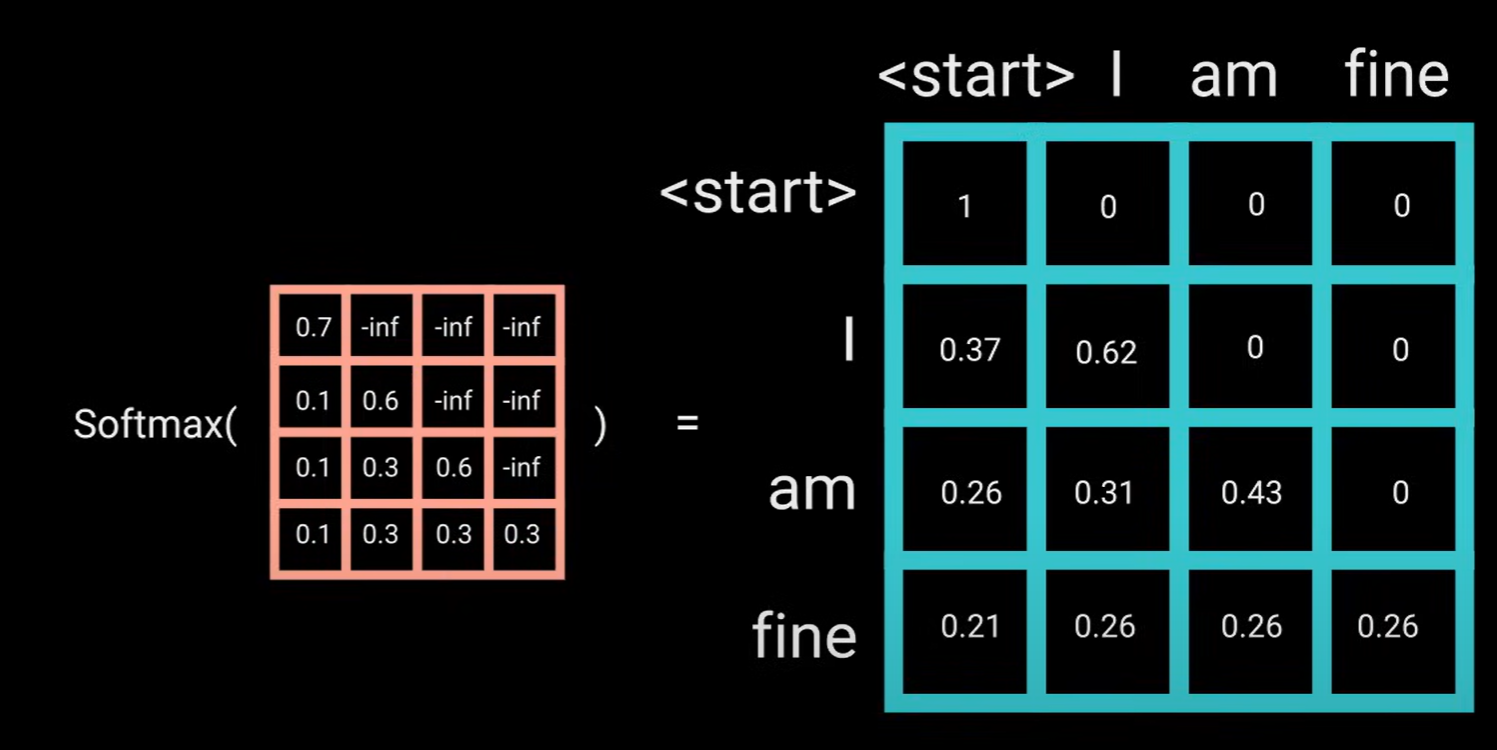
例如,在计算单词am的注意力分数时,你不应该访问单词fine, 因为我们的单词是生成于am之后的未来单词,它只能访问自身和之前的单词,这对于其他所有单词也是如此,它们只能关注前面的单词,我们需要一种方式来防止计算未来单词的注意力分数,这种方法称为掩码。

为防止解码器查看未来的标记,你需要前瞻掩码,在计算softmax之前和缩放分数知乎添加掩码。
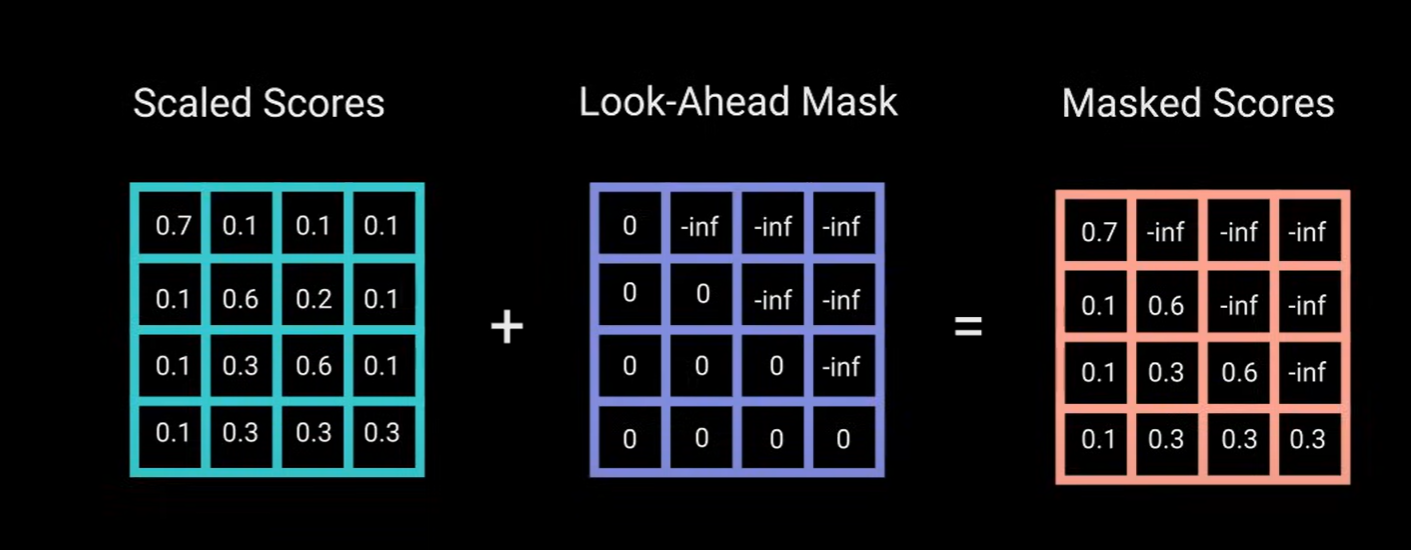
掩码工作原理:掩码是一个于注意力分数大小相同的矩阵,其中填充了-inf。当你将掩码添加到缩放注意力分数时(scaled_score),你会得到一个分数矩阵,右上角的三角形填充了负无穷。原因是,一旦对于掩码分数进行softmax,负无穷就会被归零, 留下未来的注意力分数为0。这实际上是告诉模型不需要关注这些单词。这种掩码是第一个多头注意力层中注意力得分计算方式的唯一区别。
这些层仍然有多个头,在连接并通过线性层进一步处理之前,会将掩码应用到这些头。第一个多头注意力的输出是一个掩码输出向量。其中包含有关模型应如何关注解码器输入的信息。
- 现在转到该层的第二个多头注意力层, 编码器的输出是第一个多头注意力层输出中的key中的query, 是该过程将编码器的输入与解码器的输入进行匹配,从而允许解码器决定哪个编码器输入与注意力相关。
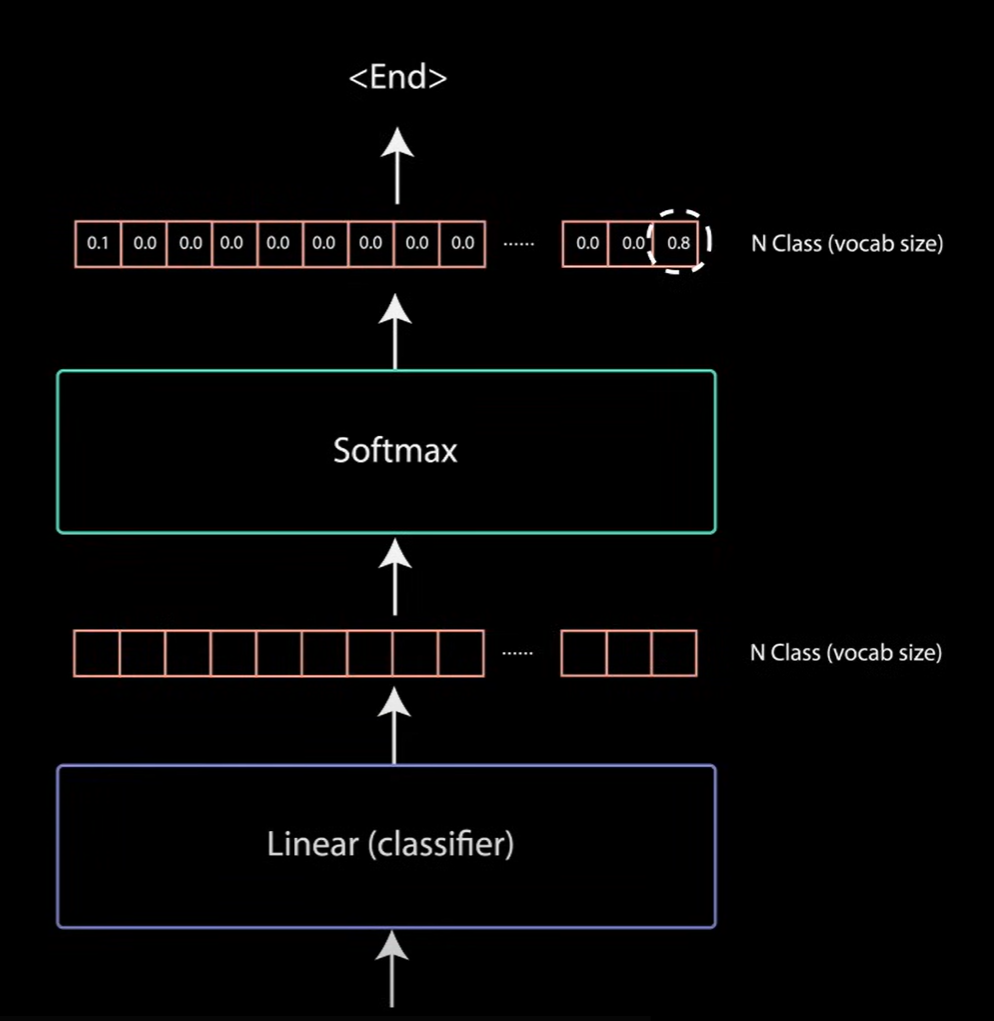
第二个多头注意力的输出经过逐点前馈层进行进一步处理,最后一个逐点前馈层的输出经过最后一个线性层,该线性层访问分类器。该分类器是你拥有的最大类数,例如,你对于10000个单词,有10000个类别,该分类器的输出大小为10000。
- 分类器的输出再次输入到softmax层,softmax层为每个类别产生0-1之间的概率值,我们取最高概率值的索引,它就是我们的预测值。
解码器没有尝试输出,而是将其添加到解码器输入列表中,继续解码,直到预测出最终标记。对我们而已,最高概率预测是分配给最终标记的最终类,这就是解码器生成输出的方式。
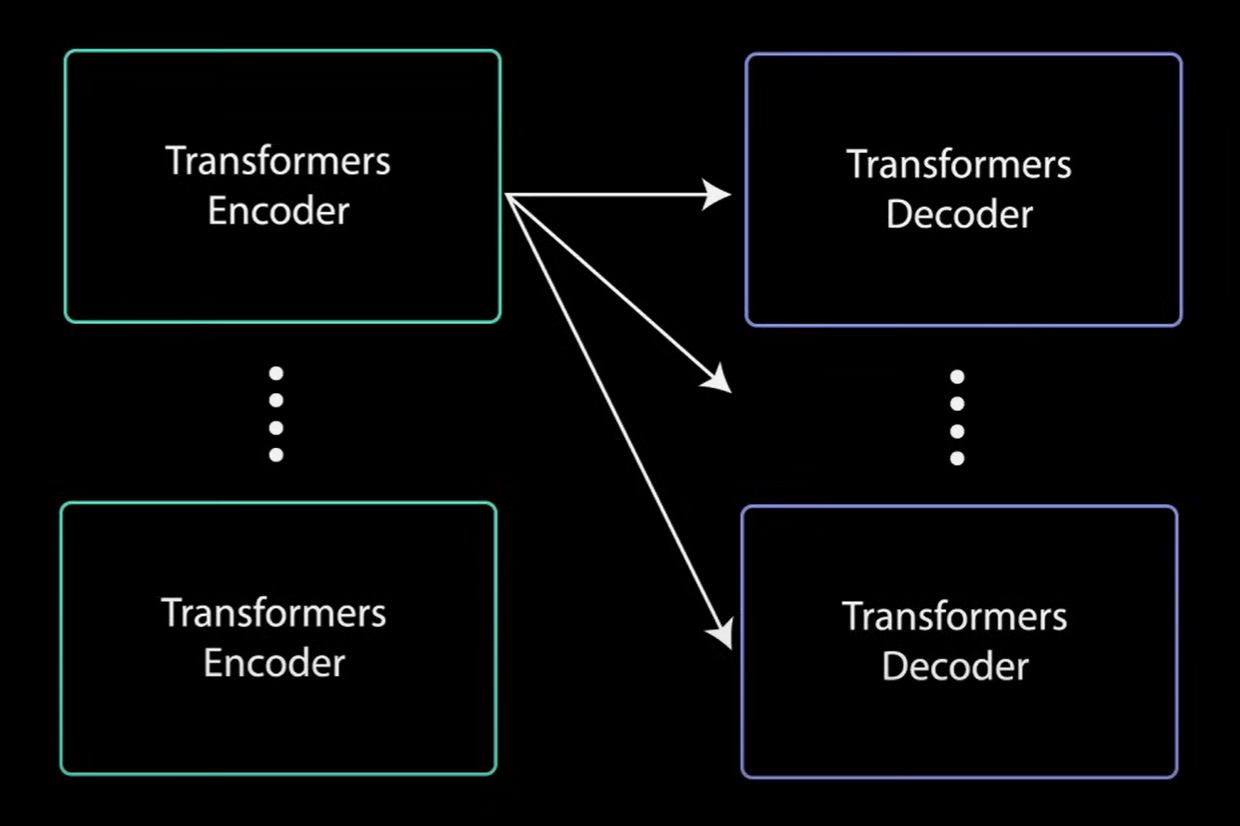
- 解码器可以叠加N层高,每层都从编码器和它之前的层接受输入,通过叠加层,模型可以学会从其注意力头中提取和关注不同的注意力组合,从而潜在地德提高其预测能力,
总结
Transformer机制利用注意力机制做出更好的预测,已知网络试图实现类似的模板,但由于它们受到短期记忆的影响,Transformer通常效果更好,特别是你向编码或生成更长的序列。