
AlexNet
参考文章
概念
LeNet-5 (1998) 和 AlexNet (2012) 是深度学习发展史上的两座里程碑。它们的关系可以概括为:LeNet 证明了卷积神经网络(CNN)的可行性,而 AlexNet 证明了 CNN 在大规模复杂任务上的统治力,并开启了现代深度学习时代。
AlexNet 是深度学习发展史上的一个里程碑式卷积神经网络(CNN)模型,由 Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 2012 年提出,并在当年的 ImageNet 大规模视觉识别挑战赛(ILSVRC-2012) 中以显著优势夺冠,大幅超越传统计算机视觉方法,从而开启了深度学习在计算机视觉领域的爆发式发展。
基本结构
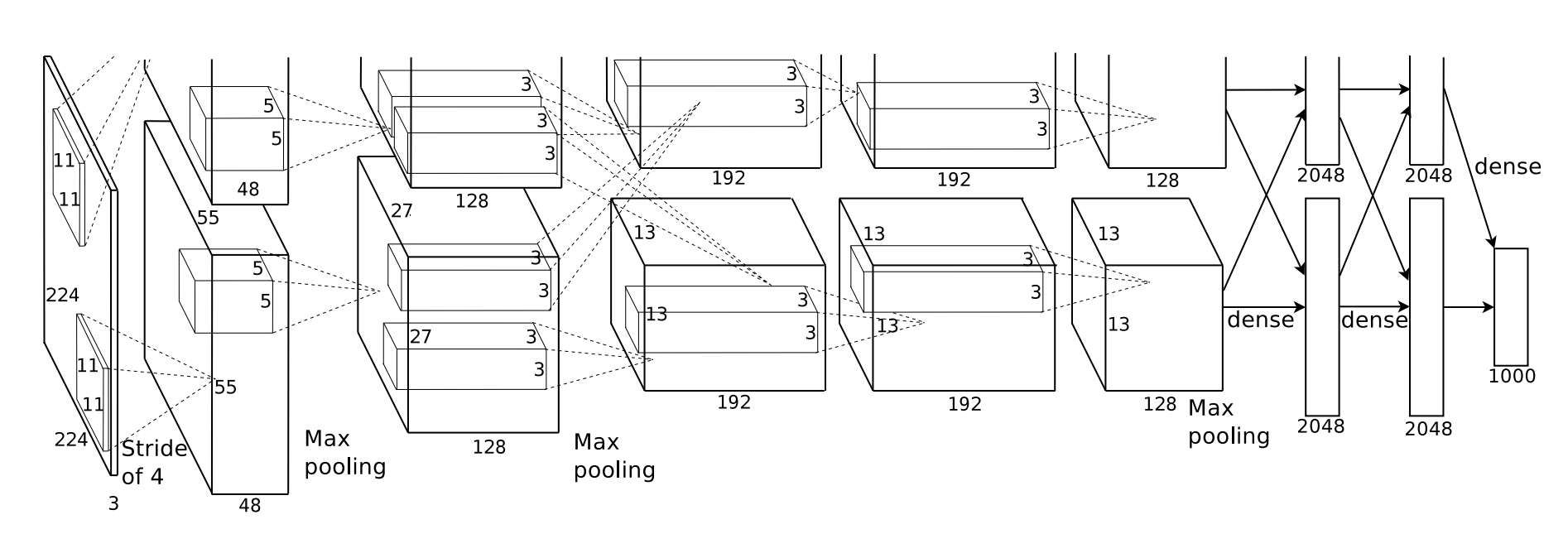
AlexNet 输入为 RGB 三通道的 224 × 224 × 3 大小的图像(也可填充为 227 × 227 × 3 )。
- AlexNet 共包含 5 个卷积层(包含 3 个池化)和 3 个全连接层。
- 其中,每个卷积层都包含卷积核、偏置项、ReLU 激活函数和局部响应归一化(LRN)模块。
- 第 1、2、5 个卷积层后面都跟着一个最大池化层,后三个层为全连接层。
- 最终输出层为 softmax,将网络输出转化为概率值,用于预测图像的类别。
核心特点
深层结构 AlexNet 包含 8 层可训练层:5 个卷积层 + 3 个全连接层。这在当时是相对较深的网络。
ReLU 激活函数 首次在大型 CNN 中使用 ReLU(Rectified Linear Unit) 作为激活函数(),相比传统的 tanh 或 sigmoid,训练速度更快且缓解了梯度消失问题。
GPU 加速训练 利用 两块 NVIDIA GTX 580 GPU 并行训练,将计算负担分摊,使得训练大型 CNN 成为可能。
局部响应归一化(LRN) 在部分卷积层后引入 LRN,用于增强泛化能力(但后续研究发现效果有限,现代网络已较少使用)。
重叠池化(Overlapping Pooling) 使用 3×3 池化窗口、步长为 2,产生重叠区域,略微提升了性能并减少了过拟合。
Dropout 正则化 在全连接层中使用 Dropout(丢弃率通常为 0.5),有效防止过拟合。
数据增强 通过图像平移、水平翻转和改变 RGB 通道强度等方式扩充训练数据,提升模型鲁棒性。
网络结构概览
卷积层输出尺寸计算公式:
输入图片(Input)大小为 WW,卷积核(Filter)大小为 KK,步长(stride)为 S,填充(Padding)的像素数为 P,那卷积层输出(Output)的特征图大小为 O 为
O = (W - K + 2P) / S + 1
| 层类型 | 参数/配置 |
|---|---|
| 输入 | 227×227×3 RGB 图像 |
| Conv1 | 96 个 11×11 卷积核,stride=4 → 输出 55×55×96 |
| ReLU + LRN + MaxPool (3×3, stride=2) | → 27×27×96 |
| Conv2 | 256 个 5×5 卷积核(分两组在两个 GPU 上)→ 27×27×256 |
| ReLU + LRN + MaxPool | → 13×13×256 |
| Conv3 | 384 个 3×3 卷积核 |
| Conv4 | 384 个 3×3 卷积核 |
| Conv5 | 256 个 3×3 卷积核 |
| MaxPool | → 6×6×256 |
| FC6 | 4096 神经元 + Dropout |
| FC7 | 4096 神经元 + Dropout |
| FC8 | 1000 神经元(对应 ImageNet 1000 类) |
| Softmax | 输出分类概率 |
注:原始实现中,由于 GPU 显存限制,网络在第 1、2、4、5 卷积层和全连接层进行了“分组”(split across two GPUs)。
逐层解析
1. 输入层
AlexNet 的输入图像尺寸是 227×227×3
2. 卷积层(C1)
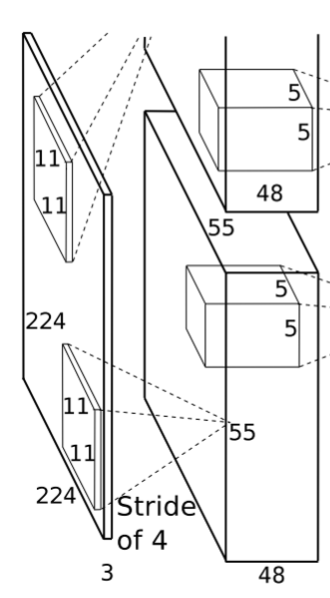
该层的处理流程是:卷积-->ReLU-->局部响应归一化(LRN)-->池化。
卷积:输入是 227x227x3,使用 96 个 11x11x3 的卷积核进行卷积,padding=0,stride=4,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(227+2*0-11)/4+1=55,得到输出是 55x55x96。
ReLU:将卷积层输出的 FeatureMap 输入到 ReLU 函数中。
局部响应归一化:局部响应归一化层简称 LRN,是在深度学习中提高准确度的技术方法。
- 一般是在激活、池化后进行。LRN 对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 局部响应归一化的输出仍然是 55x55x96。将其分成两组,每组大小是 55x55x48,分别位于单个 GPU 上。
池化:使用 3x3,stride=2 的池化单元进行最大池化操作(max pooling)。
- 注意这里使用的是重叠池化,即 stride 小于池化单元的边长。根据公式:(55+2*0-3)/2+1=27,每组得到的输出为 27x27x48。
3. 卷积层(C2)
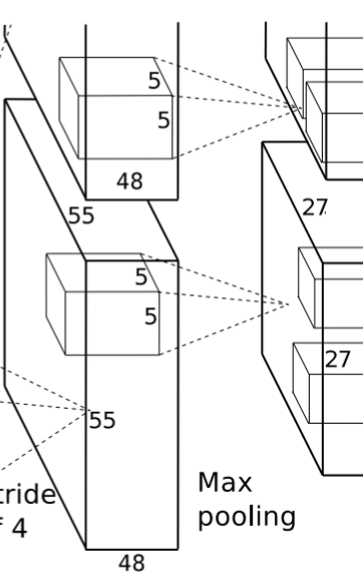
该层的处理流程是:卷积-->ReLU-->局部响应归一化(LRN)-->池化。
卷积:两组输入均是 27x27x48,各组分别使用 128 个 5x5x48 的卷积核进行卷积,padding=2,stride=1,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(27+2*2-5)/1+1=27,得到每组输出是 27x27x128。
ReLU:将卷积层输出的 FeatureMap 输入到 ReLU 函数中。
局部响应归一化:使用参数 k=2,n=5,α=0.0001,β=0.75 进行归一化。每组输出仍然是 27x27x128。
池化:使用 3x3,stride=2 的池化单元进行最大池化操作(max pooling)。
- 注意这里使用的是重叠池化,即 stride 小于池化单元的边长。根据公式:(27+2*0-3)/2+1=13,每组得到的输出为 13x13x128。
4. 卷积层(C3)
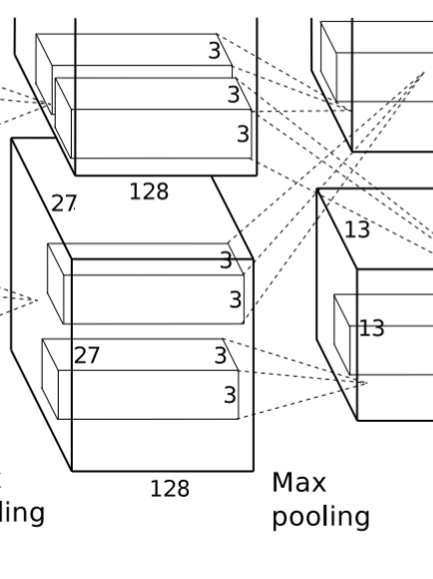
该层的处理流程是:卷积-->ReLU
卷积:输入是 13x13x256,使用 384 个 3x3x256 的卷积核进行卷积,padding=1,stride=1,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到输出是 13x13x384。
ReLU:将卷积层输出的 FeatureMap 输入到 ReLU 函数中。将输出其分成两组,每组 FeatureMap 大小是 13x13x192,分别位于单个 GPU 上。
5. 卷积层(C4)
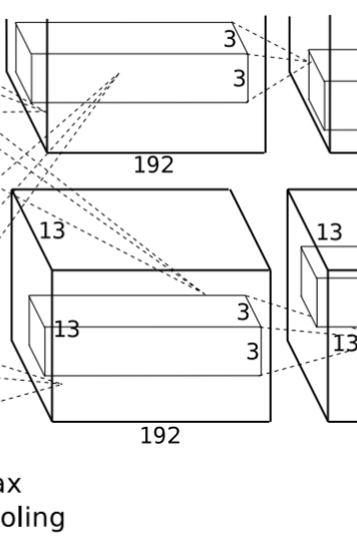
该层的处理流程是:卷积-->ReLU
卷积:两组输入均是 13x13x192,各组分别使用 192 个 3x3x192 的卷积核进行卷积,padding=1,stride=1,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组 FeatureMap 输出是 13x13x192。
ReLU:将卷积层输出的 FeatureMap 输入到 ReLU 函数中。
6. 卷积层(C5)
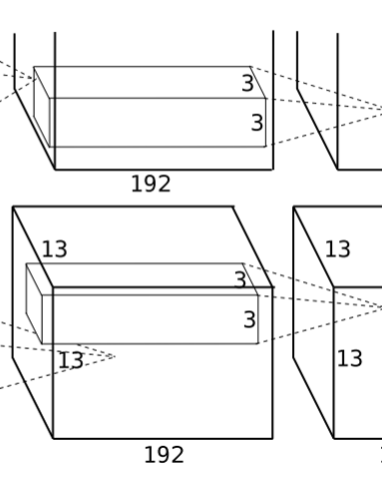
该层的处理流程是:卷积-->ReLU-->池化
卷积:两组输入均是 13x13x192,各组分别使用 128 个 3x3x192 的卷积核进行卷积,padding=1,stride=1,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(13+2*1-3)/1+1=13,得到每组 FeatureMap 输出是 13x13x128。
ReLU:将卷积层输出的 FeatureMap 输入到 ReLU 函数中。
池化:使用 3x3,stride=2 的池化单元进行最大池化操作(max pooling)。
- 注意这里使用的是重叠池化,即 stride 小于池化单元的边长。根据公式:(13+2*0-3)/2+1=6,每组得到的输出为 6x6x128。
7. 全连接层(FC6)
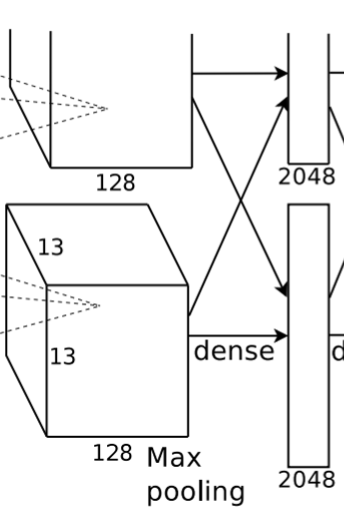
该层的流程为:(卷积)全连接 -->ReLU -->Dropout (卷积)
全连接:输入为 6×6×256,使用 4096 个 6×6×256 的卷积核进行卷积,由于卷积核尺寸与输入的尺寸完全相同,即卷积核中的每个系数只与输入尺寸的一个像素值相乘一一对应,根据公式:
- (input_size + 2 * padding - kernel_size) / stride + 1=(6+2*0-6)/1+1=1,得到输出是 1x1x4096。既有 4096 个神经元,该层被称为全连接层。
ReLU:这 4096 个神经元的运算结果通过 ReLU 激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。4096 个神经元也被均分到两块 GPU 上进行运算。
8. 全连接层(FC7)
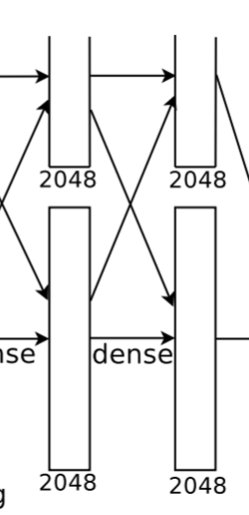
该层的流程为:(卷积)全连接 -->ReLU -->Dropout
全连接:输入为 4096 个神经元,输出也是 4096 个神经元(作者设定的)。
ReLU:这 4096 个神经元的运算结果通过 ReLU 激活函数中。
Dropout:随机的断开全连接层某些神经元的连接,通过不激活某些神经元的方式防止过拟合。
4096 个神经元也被均分到两块 GPU 上进行运算。
9. 输出层(Output layer)
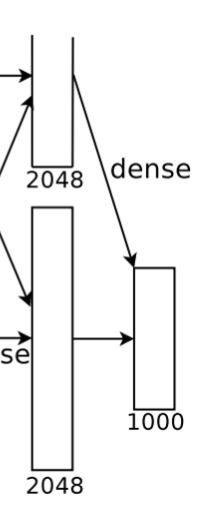
该层的流程为:(卷积)全连接 -->Softmax
全连接:输入为 4096 个神经元,输出是 1000 个神经元。这 1000 个神经元即对应 1000 个检测类别。
Softmax:这 1000 个神经元的运算结果通过 Softmax 函数中,输出 1000 个类别对应的预测概率值。
实践代码
详情
<!-- #include-env-start: D:/code/klc/test/share4ai/docs/book/dive_into_on_dl/cnn/basic -->
```python
import torch
import torch.nn as nn
import torchvision
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torch.autograd import Variable
# 定义AlexNet网络模型
class AlexNet(nn.Module):
def __init__(self, config):
super(AlexNet, self).__init__()
self._config = config
# 定义卷积层和池化层
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 自适应层,将上一层的数据转换成6x6大小
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
# 全连接层
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, self._config['num_classes']),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 定义模型保存与模型加载函数
def saveModel(self):
torch.save(self.state_dict(), self._config['model_name'])
def loadModel(self, map_location):
state_dict = torch.load(self._config['model_name'], map_location=map_location)
self.load_state_dict(state_dict, strict=False)
# 数据集预处理
# 定义构造数据加载器的函数
def Construct_DataLoader(dataset, batchsize):
return DataLoader(dataset=dataset, batch_size=batchsize, shuffle=True)
# 图像预处理
transform = transforms.Compose([
transforms.Resize(96),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载CIFAR-10数据集函数
def LoadCIFAR10(download=False):
# Load CIFAR-10 dataset
train_dataset = torchvision.datasets.CIFAR10(root='./CIFAR10', train=True, transform=transform, download=download)
test_dataset = torchvision.datasets.CIFAR10(root='./CIFAR10', train=False, transform=transform)
return train_dataset, test_dataset
# 模型训练函数封装
class Trainer(object):
# 初始化模型、配置参数、优化器和损失函数
def __init__(self, model, config):
self._model = model
self._config = config
self._optimizer = torch.optim.Adam(self._model.parameters(),\
lr=config['lr'], weight_decay=config['l2_regularization'])
self.loss_func = nn.CrossEntropyLoss()
# 对单个小批量数据进行训练,包括前向传播、计算损失、反向传播和更新模型参数
def _train_single_batch(self, images, labels):
y_predict = self._model(images)
loss = self.loss_func(y_predict, labels)
# 先将梯度清零,如果不清零,那么这个梯度就和上一个mini-batch有关
self._optimizer.zero_grad()
# 反向传播计算梯度
loss.backward()
# 梯度下降等优化器 更新参数
self._optimizer.step()
# 将loss的值提取成python的float类型
loss = loss.item()
# 计算训练精确度
# 这里的y_predict是一个多个分类输出,将dim指定为1,即返回每一个分类输出最大的值以及下标
_, predicted = torch.max(y_predict.data, dim=1)
return loss, predicted
def _train_an_epoch(self, train_loader, epoch_id):
"""
训练一个Epoch,即将训练集中的所有样本全部都过一遍
"""
# 设置模型为训练模式,启用dropout以及batch normalization
self._model.train()
total = 0
correct = 0
# 从DataLoader中获取小批量的id以及数据
for batch_id, (images, labels) in enumerate(train_loader):
images = Variable(images)
labels = Variable(labels)
if self._config['use_cuda'] is True:
images, labels = images.cuda(), labels.cuda()
loss, predicted = self._train_single_batch(images, labels)
# 计算训练精确度
total += labels.size(0)
correct += (predicted == labels.data).sum()
# print('[Training Epoch: {}] Batch: {}, Loss: {}'.format(epoch_id, batch_id, loss))
print('Training Epoch: {}, accuracy rate: {}%%'.format(epoch_id, correct / total * 100.0))
def train(self, train_dataset):
# 是否使用GPU加速
self.use_cuda()
for epoch in range(self._config['num_epoch']):
print('-' * 20 + ' Epoch {} starts '.format(epoch) + '-' * 20)
# 构造DataLoader
data_loader = DataLoader(dataset=train_dataset, batch_size=self._config['batch_size'], shuffle=True)
# 训练一个轮次
self._train_an_epoch(data_loader, epoch_id=epoch)
# 用于将模型和数据迁移到GPU上进行计算,如果CUDA不可用则会抛出异常
def use_cuda(self):
if self._config['use_cuda'] is True:
assert torch.cuda.is_available(), 'CUDA is not available'
torch.cuda.set_device(self._config['device_id'])
self._model.cuda()
# 保存训练好的模型
def save(self):
self._model.saveModel()
train_dataset, test_dataset = LoadCIFAR10(True)