
过拟合和欠拟合
过拟合和欠拟合图形表示
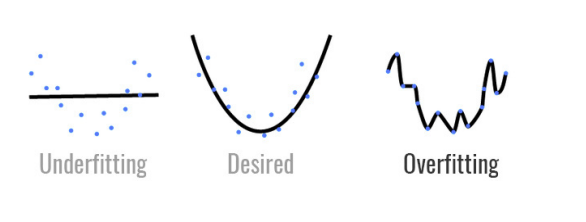
欠拟合 (Underfitting):学得太少
- 模型过于简单,无法捕捉数据中的基本规律和特征。它在训练集上表现就很差,在测试集上自然也很差。
- 症状:
- 训练误差(Training Loss)高。
- 验证误差(Validation Loss)高。
- 训练误差 ≈ 验证误差。
过拟合 (Overfitting):学得太“死”
- 模型过于复杂,不仅学到了数据中的普遍规律,还把训练数据中的噪声、异常值甚至随机波动都当成了规律背了下来。它在训练集上表现完美,但在测试集上表现很差(泛化能力弱)。
- 症状:
- 训练误差(Training Loss)非常低(接近 0)。
- 验证误差(Validation Loss)很高,且随着训练进行反而上升。
- 训练误差 ≪ 验证误差(差距巨大)。
训练误差(training error)是指模型在训练数据集上计算得到的误差。
泛化误差(generalization error)是指模型应用在同样从原始样本的分布中抽取的无限多数据样本时,模型误差的期望。
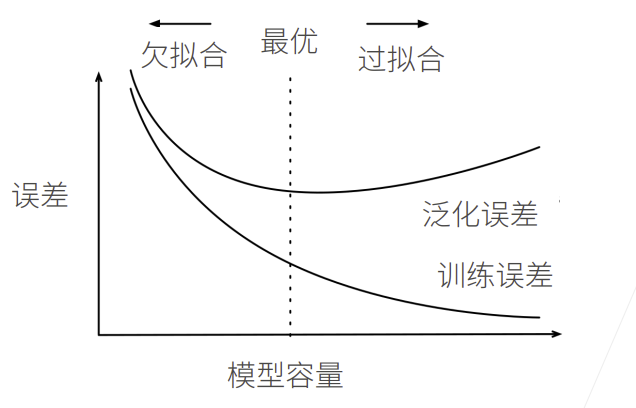
模型容量和数据关系:

模型容量
- 拟合各种函数的能力
- 低容量的模型难以拟合训练数
- 高容量的模型可以记住所有的训练数据
下图,左图为欠拟合,右图为过拟合:
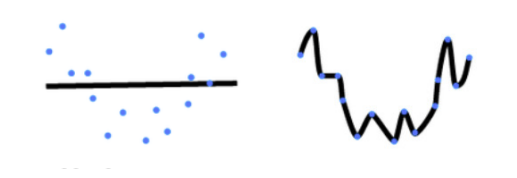
模型容量的影响
深度学习:先保证模型足够大,再去控制模型容量,最后得到泛化误差下降。
估计模型容量
- 难以在不同的种类算法之间上比较
- 例如数模型和神经网络
- 给定一个模型种类,将有两个主要因素
- 参数的个数
- 参数值的选择范围
数据复杂度
- 多个重要因素
- 样本个数
- 每个样本的元素个数
- 时间、空间结构
- 多样性
总结
- 模型容量需要匹配数据复杂度,否则可能导致欠拟合和过拟合
- 统计机器学习提供数学工具来衡量模型复杂度
- 实际中一般靠观察训练误差和验证误差