
语言模型基础 - 基于神经网络的语言模型
基于RNN 的语言模型
RNN在训练过程中的问题
训练迭代过程早期的循环神经网络(RNN)预测能力非常弱,几乎不能给出好的生成结果。如果某一个unit产生了垃圾结果,必然会影响后面一片unit的学习。teacher forcing最初的motivation就是解决这个问题的。使用teacher-forcing,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,存在训练测试偏差,模型会变得脆弱。
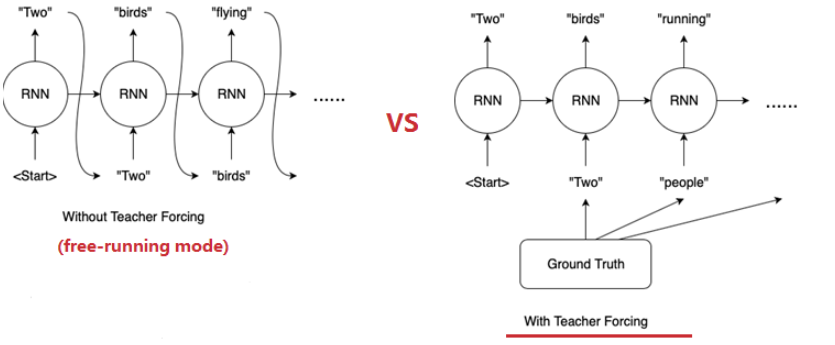
RNN的两种训练模式
- free-running mode
- 上一个时间步的输出作为下一个时间步的输入
- 可能导致的问题:
- 收敛速度慢。
- 模型不稳定。
- 模型性能差。
- teacher-forcing mode
- 直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入,而不是使用模型生成的输出。
- 可能导致的问题:
- teacher-forcing过于依赖ground truth数据,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,所以如果目前生成的序列在训练过程中有很大不同,模型就会变得脆弱。
- 解决的方法:
- 集束搜索(Beam Search)
- 在预测单词这种离散值的输出时,一种常用方法是对词表中每一个单词的预测概率执行搜索,生成多个候选的输出序列。这个方法常用于机器翻译(MT)等问题,以优化翻译的输出序列。
- 有计划地学习(Curriculum Learning)
- Curriculum Learning是Teacher Forcing的一个变种:一开始老师带着学,后面慢慢放手让学生自主学。
- Curriculum Learning即有计划地学习:
- 使用一个概率p去选择使用ground truth的输出y(t)还是前一个时间步骤模型生成的输出h(t)作为当前时间步骤的输入x(t+1)。
- 这个概率p会随着时间的推移而改变,称为计划抽样(scheduled sampling)。
- 训练过程会从force learning开始,慢慢地降低在训练阶段输入ground truth的频率。
- 集束搜索(Beam Search)
基于Transformer 的语言模型
在 Transformer 模型中,编码器负责理解和提取输入文本中的相关信息。这个过程通常涉及到处理文本的序列化形式,例如单词或字符,并且用自注意力机(Self-Attention)来理解文本中的上下文关系。编码器的输出是输入文本的连续表示,通常称为嵌入(Embedding)。这种嵌入包含了编码器从文本中提取的所有有用信息,并以一种可以被模型处理的格式(通常是高维向量)表示。
这个嵌入然后被传递给解码器。解码器的任务是根据从编码器接收到的嵌入来生成翻译后的文本(目标语言)。解码器也使用自注意力机制,以及编码器-解码器注意力机制,来生成翻译的文本。
LLMs中有的是只有编码器encoder-only,有的只有解码器decoder-only,有的是2者混合 encoder decoder hybrid。三者都属于Seq2Seq,sequence to sequence。并且字面意思是虽只有编码器encoder,实际上LLMs是能decoder一些文本和token的,也算是decoder。不过由于encoder-only类型的LLM不像decoder-only和encoder-decoder那些有自回归autoregressive,encoder-only集中于理解输入的内容,并做针对特定任务的输出。
自回归指输出的内容是根据已生成的token做上下文理解后一个token一个token输出的。
- Encoder-only架构的LLMs更擅长理解输入文本的深层含义,对文本内容进行分析、分类,包括情感分析,命名实体识别。
- Decoder-only架构的LLMs更擅长生成新的、连贯的文本,包括文本生成、翻译、图像生成。主要是是为了预测下一个输出的内容/token是什么,并把之前输出的内容/token作为上下文学习。
- Encoder-Decoder架构的LLMs更擅长处理输入和输出序列之间存在复杂映射关系的任务,以及捕捉两个序列中元素之间关系至关重要的任务。专注于将一种形式的序列转换成另一种形式,是经典的序列到序列任务的解决方案。
