
参数高效微调 —— 参数附加方法
简介
参数附加方法(Additional Parameter Methods)通过增加并训练新的附加参数或模块对大语言模型进行微调。参数附加方法按照附加位置可以分为三类:加在输入、加在模型以及加在输出。
加在输入
加在输入的方法将额外参数附加到模型的输入嵌入(Embedding)中,其中最经典的方法是Prompt-tuning。Prompt-tuning 在模型的输入中引入可微分的连续张量,通常也被称为软提示(Soft prompt)。软提示作为输入的一部分,与实际的文本数据一起被送入模型。在微调过程中,仅软提示的参数会被更新,其他参数保持不变,因此能达到参数高效微调的目的。
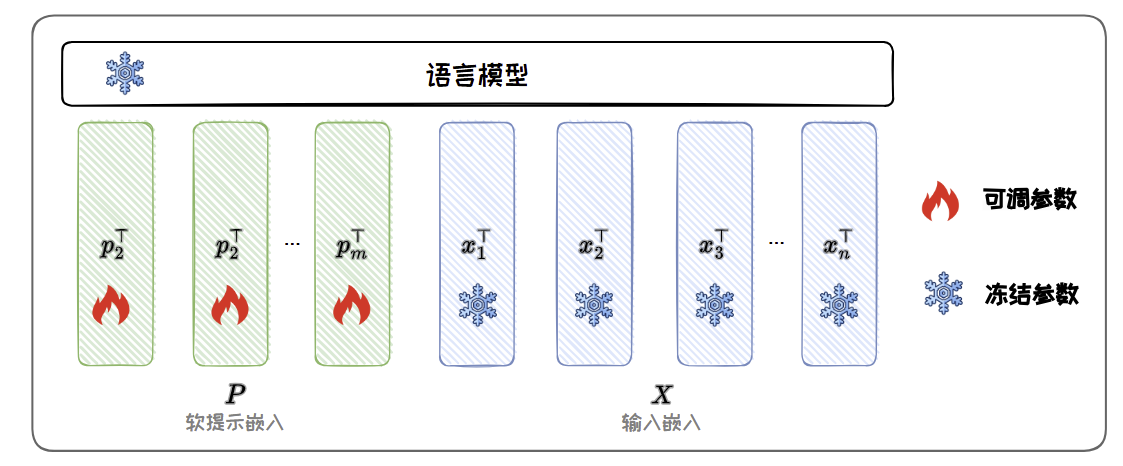
Prompt-tuning 有以下优势:
- 内存效率高:Prompt-tuning 显著降低了内存需求;
- 多任务能力:可以使用单一冻结模型进行多任务适应。传统的模型微调需要为每个下游任务学习并保存任务特定的完整预训练模型副本,并且推理必须在单独的批次中执行。Prompt-tuning 只需要为每个任务存储一个特定的小的任务提示模块,并且可以使用原始预训练模型进行混合任务推理(在每个任务提示词前加上学到的 soft prompt)。
- 缩放特性:随着模型参数量的增加,Prompt-tuning 的性能会逐渐增强,并且在10B 参数量下的性能接近(多任务)全参数微调的性能。
加在模型
加在模型的方法将额外的参数或模型添加到预训练模型的隐藏层中,其中经典的方法有Prefix-tuning、Adapter-tuning和AdapterFusion。
Prefix-tuning
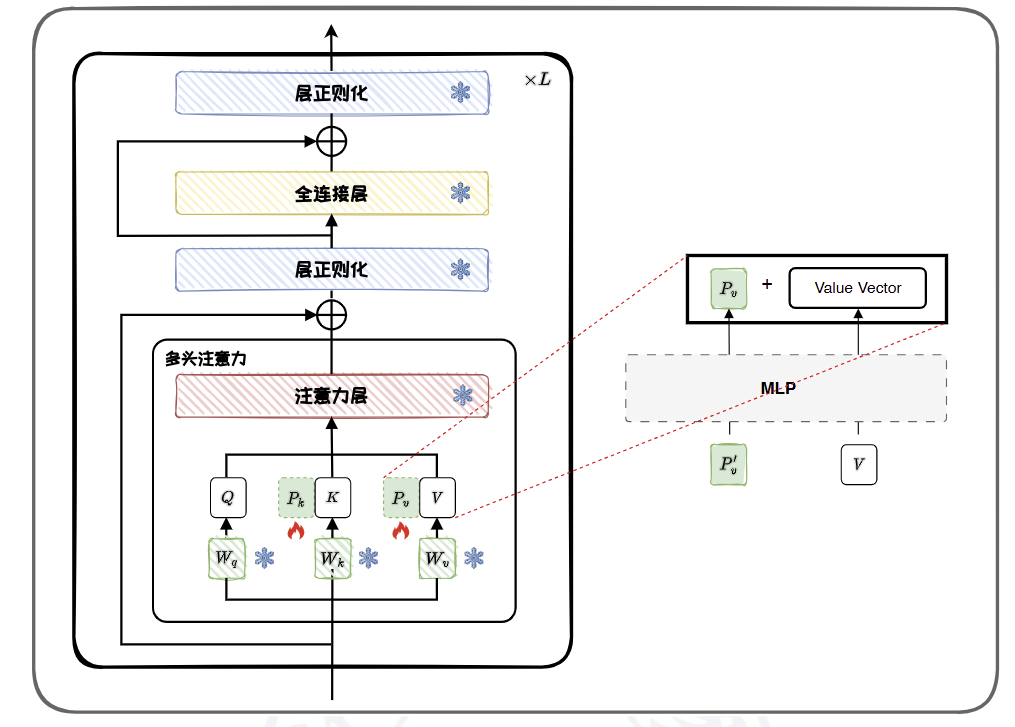
Prefix-tuning 引入了一组可学习的向量 Pk 和 Pv,这些向量被添加到所有 Transformer 注意力模块中的键 K 和值 V 之前。类似于 Prompt-tuning,Prefix-tuning 也会面临前缀参数更新不稳定的问题,从而导致优化过程难以收敛。因此,在实际应用中,通常需要在输入Transformer 模型前,先通过一个多层感知机(MLP)进行重参数化。
优势:
- 参数效率:只有前缀参数在微调过程中被更新,这显著减少了训练参数量;
- 任务适应性:前缀参数可以针对不同的下游任务进行定制,微调方式灵活;
- 保持预训练知识:由于预训练模型的原始参数保持不变,Prefix-tuning能够保留预训练过程中学到的知识。
备注:
MLP 的基本结构
- 由**多个全连接层(Dense Layers)**堆叠而成
- 每层包含:线性变换(权重矩阵乘法 + 偏置) + 非线性激活函数(如 ReLU、GELU、Swish)
- 典型形式:
MLP(x)=W2⋅Activation(W1x+b1)+b2
MLP 在 LLM 中的核心作用
- 非线性表达能力增强
- 信息“加工”与“提炼” (自注意力输出的是上下文聚合后的表示,MLP 对这些表示进行进一步变换、过滤和强化) 3. 实现前馈网络(Feed-Forward Network, FFN)
- 扩大模型容量(Model Capacity)
- 支持知识存储与推理
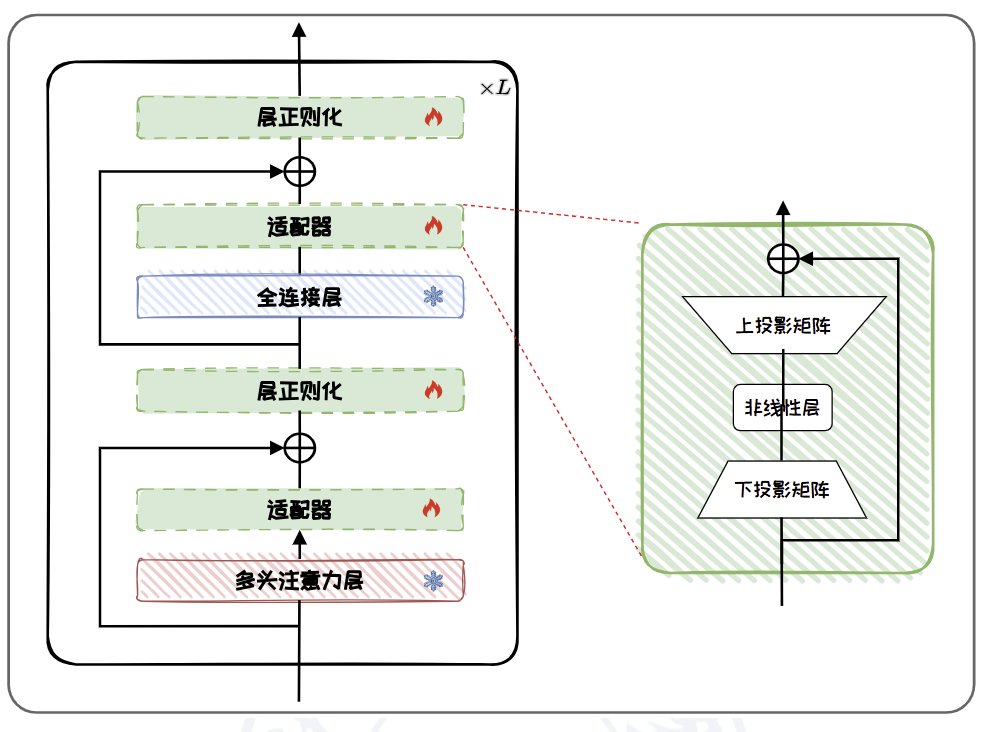
Adapter-tuning
Adapter-tuning 向预训练语言模型中插入新的可学习的神经网络模块,称为适配器(Adapter)。Adapter-tuning 无需更新预训练模型,而是通过适配器参数来学习单个任务,每个适配器参数都保存了解决该任务所需的知识。
基本思想:
- 冻结主干模型:原始预训练模型的所有参数被冻结(不更新),避免全参数微调带来的高计算和存储开销。
- 插入轻量模块:在 Transformer 的每个层(或部分层)中插入小型神经网络模块(称为 Adapter),这些模块包含少量可训练参数。
- 仅训练 Adapter:微调阶段只更新 Adapter 中的参数,其余参数保持不变。
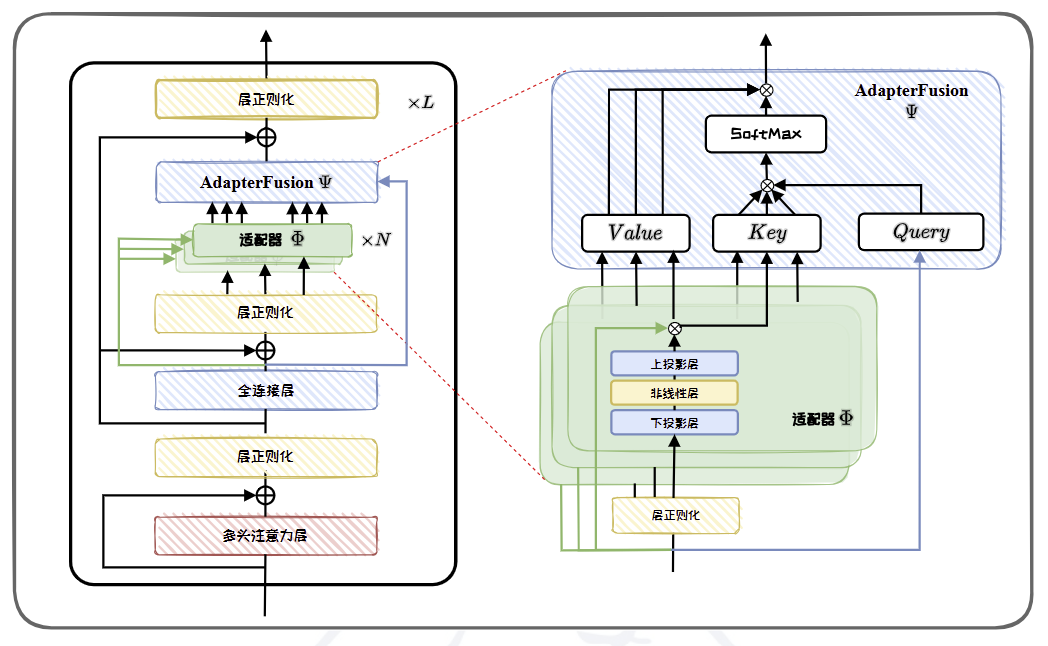
AdapterFusion
AdapterFusion是一种在多任务学习 或 知识迁移场景下,将多个预训练好的 Adapter 模块 融合起来以提升目标任务性能的参数高效微调(PEFT)方法。它由 Pfeiffer et al. 在 2021 年提出(论文:AdapterFusion: Non-Destructive Task Composition for Transfer Learning),核心思想是 复用已有 Adapter 的知识,避免灾难性遗忘,同时实现灵活的任务组合。
基于该思路,AdapterFusion提出一种两阶段学习的方法,先学习多个任务,对每个任务进行知识提取;再“融合”(Fusion)来自多个任务的知识。具体的两阶段步骤如下:
- 知识提取。给定N个任务,首先对每个任务分别训练适配器模块,用于学习特定任务的知识。
- 知识组合。单个任务的适配器模块训练完成后,AdapterFusion 将不同适配器模块进行融合(Fusion),以实现知识组合。
加在输出
首先,大语言模型的参数数量可能会非常庞大,即使采用了PEFT 技术,也难以在普通消费级GPU 上完成下游任务适应;其次,用户可能无法直接访问大语言模型的权重(黑盒模型),这为微调设置了障碍。
为了应对这些问题,代理微调(Proxy-tuning) 提供了一种轻量级的解码时(Decoding-time)算法,允许在不直接修改大语言模型权重的前提下,通过仅访问模型输出词汇表预测分布,来实现对大语言模型的进一步定制化调整。
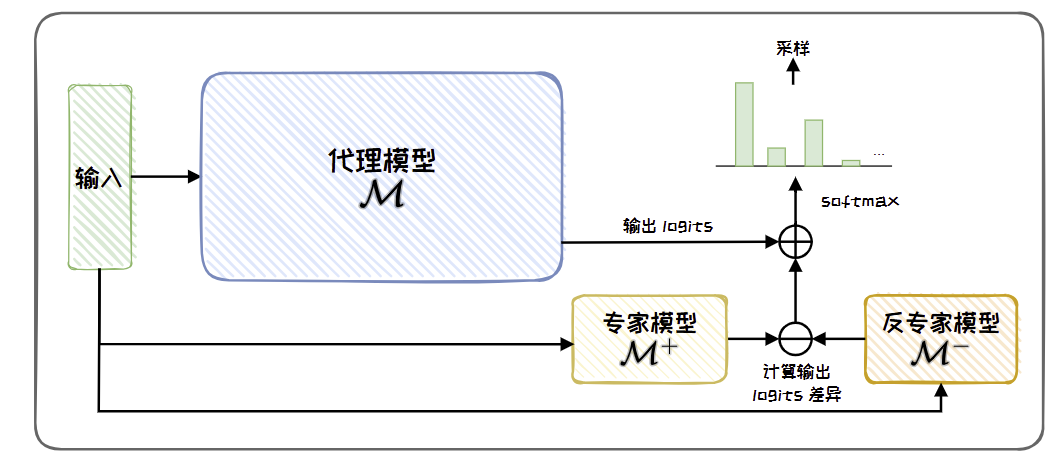
给定待微调的代理模型M以及较小的反专家模型(Anti-expertmodel)M−,这两个模型需要相同的词汇表。对M−进行微调,得到微调后的专家模型(Expert model)M+。在每一个自回归生成的时间步中,代理微调首先计算专家模型M+ 和反专家模型M−之间的logits 分布差异,然后将其加到代理模型M下一个词预测的logits 分布中。
具体来说,在代理微调的计算阶段,针对每一时间步t 的输入序列x<t,从代理模型M、专家模型M+ 和反专家模型M−中获取相应的输出分数sM, sM+, sM−。
通过下式调整目标模型的输出分数 ̃s: ̃s = sM+ sM+ −sM−
然后,使用softmax(·) 对其进行归一化,得到输出概率分布, p ̃M(Xt |x<t) = softmax( ̃s) ̃
最后,在该分布中采样得到下一个词的预测结果。
在实际使用中,通常专家模型是较小的模型(例如,LLaMA-7B),而代理模型则是更大的模型(例如,LLaMA-13B 或LLaMA-70B)。通过代理微调,我们将较小模型中学习到的知识,以一种解码时约束的方式迁移到比其大得多的模型中,大幅节省了计算成本。同时,由于仅需要获取模型的输出分布,而不需要原始的模型权重,因此该方法对于黑盒模型同样适用。