
卷积
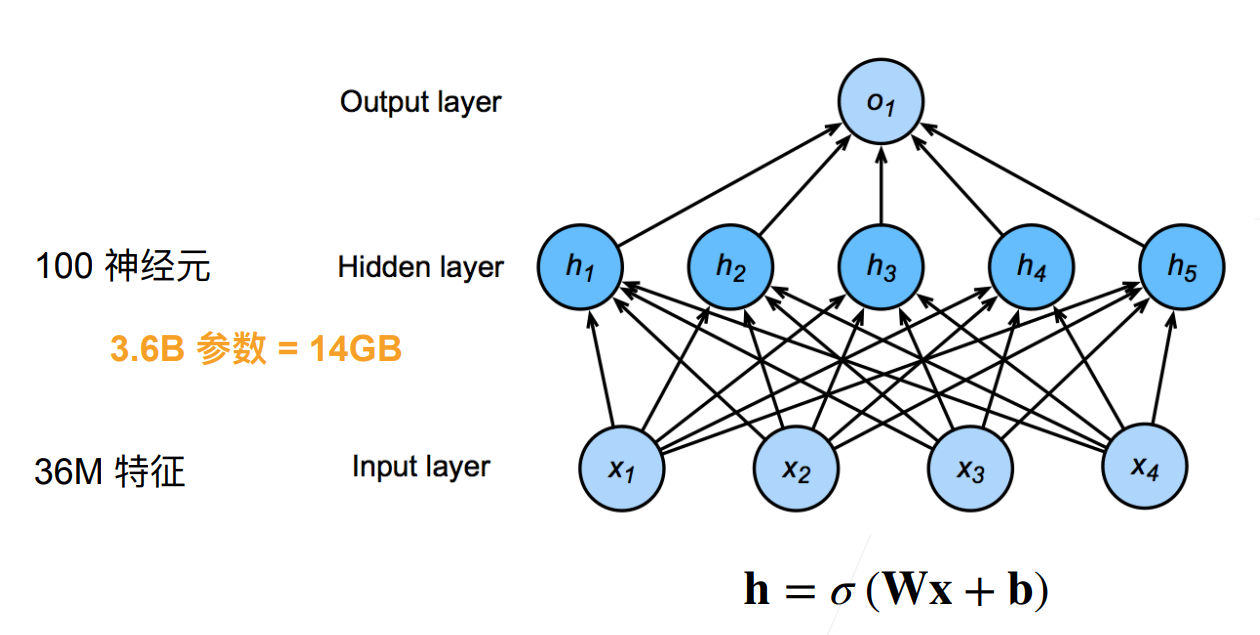
分类猫和狗的图片

- 使用一个还不错的相机采集图片(12M像素)
- RGB图片有36M元素
- 使用100大小的单隐藏层 MLP,模型有3.6B元素
- 远多世界上所有猫和狗总数(900M狗,600M猫)
单隐藏层MLP:
| 精度类型 | 每参数字节数 | 总内存估算 |
|---|---|---|
| FP32(32位浮点) | 4 字节 | 3.6B × 4 ≈ 14.4 GB |
| FP16 / BF16(16位) | 2 字节 | 3.6B × 2 ≈ 7.2 GB |
| INT8(8位整型) | 1 字节 | 3.6B × 1 ≈ 3.6 GB |
| MXFP4(4位混合精度) | 0.5 字节 | 3.6B × 0.5 ≈ 1.8 GB |
图像处理

图像具有平移不变性(translation invariance)和局部性(locality),这两个特性是卷积神经网络(CNN) 能在计算机视觉任务中取得巨大成功的重要理论基础。

局部性(Locality)
图像中的一个像素通常只与其邻近的像素有强相关性,而与远处的像素关系较弱。也就是说,有意义的视觉模式(如边缘、角点、纹理)往往出现在局部区域内。
举例
- 识别“猫的眼睛”不需要看整张图,只需关注局部区域。
- 边缘检测滤波器(如 Sobel 算子)只作用于 3×3 或 5×5 的小窗口。
CNN 如何利用局部性?
- 使用小尺寸卷积核(如 3×3、5×5)只处理局部感受野。
- 通过堆叠多层卷积,逐步扩大感受野,从局部特征组合成全局语义。
✅ 优势:大幅减少参数量,避免全连接带来的过拟合和计算爆炸。
平移不变性(Translation Invariance)
更准确地说,CNN 具备一定程度的平移等变性(equivariance),最终通过池化等操作实现近似平移不变性。
定义
平移等变性(Translation Equivariance):
如果输入图像中的某个模式(如边缘)发生平移,那么特征图中的响应也会以相同方式平移。即:
f(x shifted) = f(x) shifted平移不变性(Translation Invariance):
无论目标出现在图像哪个位置,模型都能识别出它是同一类对象(输出类别不变)。即:
classifier(x shifted) = classifier(x)
CNN 如何实现?
- 卷积操作本身具有平移等变性:同一个卷积核在图像所有位置滑动,对相同模式产生相同响应。
- 池化(如最大池化)和深层结构逐渐增强对位置变化的鲁棒性,趋向平移不变。
- 全连接分类头最终将空间信息“压缩”为类别概率,忽略精确位置。
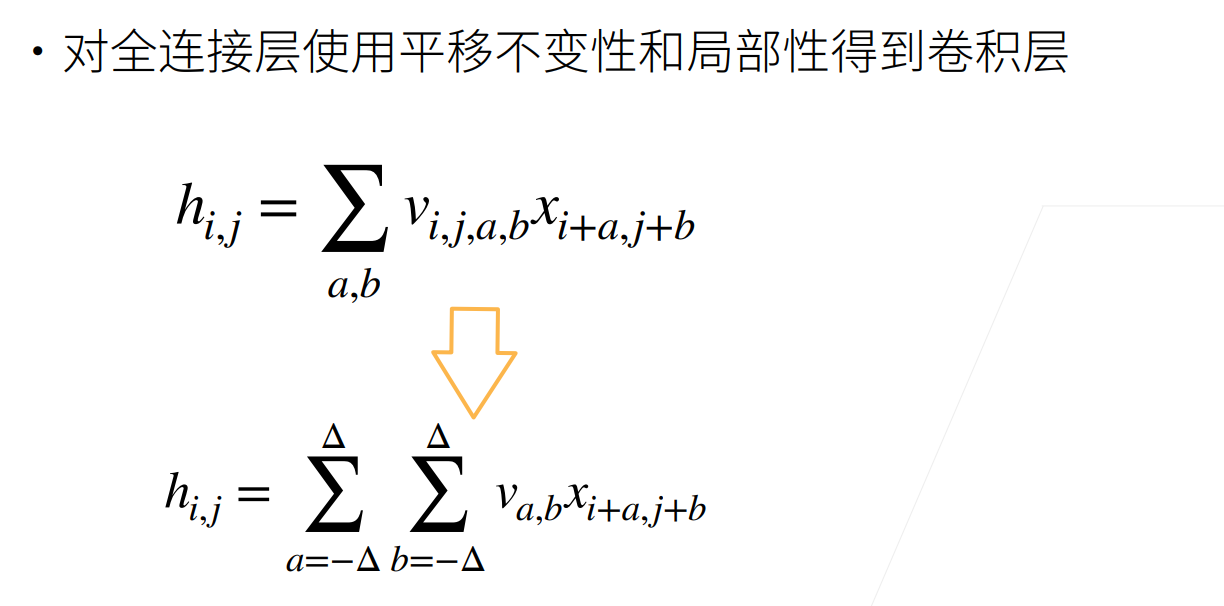
全连接层 ——> 卷积层
通过对全连接层施加“平移不变性”和“局部性”这两个先验约束,推导出卷积层的结构。
🧩 背景回顾:全连接层的权重长什么样?
假设你有一个 2×2 的输入图像(为了简单),即:
把它拉成向量:
再假设输出也是一个 2×2 的特征图,拉成向量 。
那么全连接层就是:
也就是说,每个输出神经元 都和所有 4 个输入相连,共 16 个权重。
但这样完全忽略了“空间位置”——比如 是左上角, 是右下角,但在向量里它们只是第1个和第4个元素,没有几何意义。
🔁 现在:不拉平!保留二维结构
我们不把输入/输出拉成向量,而是保持它们是二维矩阵:
- 输入:,其中 (高),(宽)
- 输出:,其中 ,
那么,全连接操作可以写成:
👉 这里 表示:从输入位置 到输出位置 的连接权重。
📦 权重现在是一个 4-D 张量!
因为:
- 输出有两个索引:
- 输入有两个索引:
所以权重自然是一个 四维数组(张量):
维度是:
你可以想象这是一个“超立方体”,每个元素 告诉你:
“当计算输出位置 时,输入位置 应该贡献多少”。
✅ 这就是“将权重变形为 4-D 张量 ”的意思:
- 不再是扁平的 ,
- 而是结构化的 ,显式记录了空间到空间的映射。
转换过程

TODO: 需要理解重新索引



小结
卷积神经网络(CNN)通过利用图像的平移不变性和局部性,成功地解决了全连接层在处理图像时的局限性。卷积操作能够通过减少参数数量、提高计算效率来有效提取图像特征,成为计算机视觉领域的核心技术。
- 平移不变性:图像中的物体位置不会影响卷积神经网络的识别能力。
- 局部性:卷积神经网络专注于图像的局部区域,以便提取有效的局部特征。
- 权重共享:卷积核在整个图像中共享相同的权重,减少了模型的参数数量。