
语言模型基础 - 基于统计方法的语言模型
概述
语言模型通过对语料库(Corpus)中的语料进行统计或学习来获得预测语言符号概率的能力。
通常,基于统计的语言模型通过直接统计语言符号在语料库中出现的频率来预测语言符号的概率。其中,n-grams 是最具代表性的统计语言模型。n-grams 语言模型基于马尔可夫假设和离散变量的极大似然估计给出语言符号的概率。
n-grams 语言模型
n-grams 语言模型中的n-gram 指的是长度为n的词序列。n-grams 语言模型通过依次统计文本中的n-gram 及其对应的(n-1)-gram 在语料库中出现的相对频率来计算文本w1:N 出现的概率。计算公式如下所示:
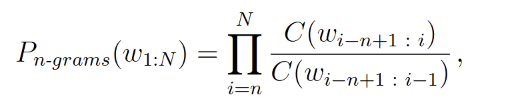
其中,C(wi−n+1:i) 为词序列{wi−n+1, ..., wi}在语料库中出现的次数,C(wi−n+1:i−1)为词序列{wi−n+1, ..., wi−1}在语料库中出现的次数。
n 阶马尔可夫假设
对序列 {w1, w2, w3, ..., wN },当前状态 wN 出现的概率只与前 n 个状态{wN−n, ..., wN−1}有关,即:
P(wN |w1, w2, ..., wN−1) ≈ P (wN |wN−n, ..., wN−1)
离散型随机变量的极大似然估计
给定离散型随机变量X 的分布律为P {X = x}= p(x; θ) ,设X1, ..., XN 为来自X的样本,x1, ..., xN 为对应的观察值,θ 为待估计参数。在参数θ下,分 布函数随机取到x1, ..., xN 的概率为:
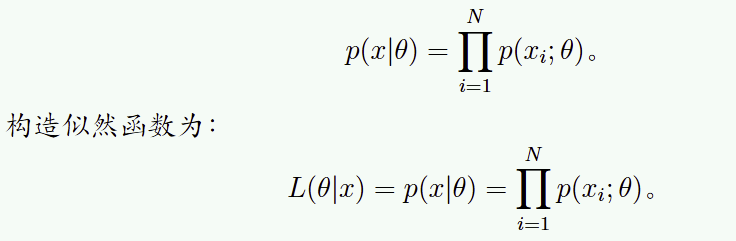
总结
在上述两个定义的基础上,对n-grams 的统计原理进行讨论。设文本w1:N 出现的概率为P(w1:N)。根据条件概率的链式法则P(w1:N)可由下式进行计算。
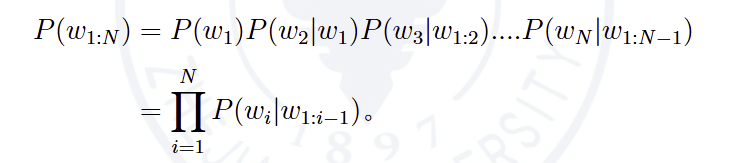
根据n 阶马尔可夫假设,n-grams 语言模型令P(wi|wi−n:i−1)近似P(wi|w1:i−1)。然后,根据离散型随机变量的极大似然估计,令C(wi−n:i)/C(wi−n:i−1) 近似P(wi|wi−n:i−1)。从而,得到n-grams语言模型的输出Pn-grams(w1:N)是对P(wi|w1:i−1)的近似。即
Pn-grams(w1:N) ≈ P(w1:N)
n-grams 语言模型通过统计词序列在语料库中出现的频率来预测语言符号的概率。其对未知序列有一定的泛化性,但也容易陷入“零概率”的困境。随着神经网络的发展,基于各类神经网络的语言模型不断被提出,泛化能力越来越强。