
R-CNN
参考文章
引言
R-CNN用候选区域方法(region proposal method),创建目标检测的区域,改变了图像领域实现物体检测的模型思路。R-CNN是以深度神经网络为基础的目标检测模型 ,R-CNN在当时以优异的性能令世人瞩目,以R-CNN为基点,后续的SPPNet、Fast R-CNN、Faster R-CNN模型都照着这个目标检测思路。
概念
区域卷积神经网络(Region-based Convolutional Neural Networks,简称 R-CNNs)是一类用于目标检测(Object Detection)的深度学习模型。
核心思想:先生成候选区域(Region Proposals),再对每个候选区域进行分类和边界框回归。R-CNN 系列方法在 2014 年前后极大地推动了目标检测的发展。
相关理论与模型
传统目标检测算法模型
- 候选框的提取:候选框的提取通常采用滑动窗口的方法(时耗问题)。
- 特征提取:基于颜色、基于纹理、基于形状的方法,以及一些中层次或高层次语义特征的方法。
- 目标检测算法中通常使用的方法集中在低层、中层目标判别: 对候选区域提取出的特征进行分类判定。
- 单类别目标检测:区分背景、目标。
- 多分类问题:区分当前窗口中对象的类别。
- NMS:解决候选框重叠问题,NMS对候选框进行合并。
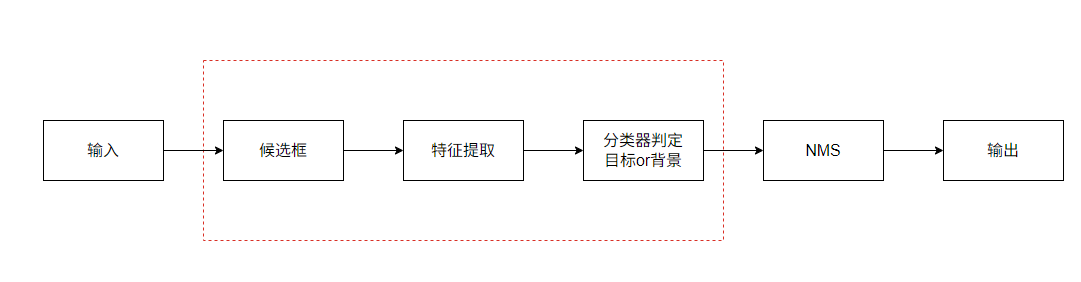
目标检测算法的分类
- 传统的目标检测算法:
SIFT(尺度不变特征变换)
HOG(方向梯度直方图)
DPM(一种基于组件的图像检测算法)等。
- 基于深度学习的目标检测算法可以分为两类,一阶算法(One Stage)和 二阶算法(Two Stage):
- 一阶算法:不生成候选框,直接在网络中提取特征来预测物体的分类和位置。常见算法有 SSD、YOLO系列 和 RetinaNet 等。一阶算法检测速度更快。
- 二阶算法:先生成区域候选框,再通过卷积神经网络进行分类和回归修正。常见算法有 RCNN、SPPNet、Fast RCNN,Faster RCNN 和 RFCN 等。二阶算法检测结果更精确。
R-CNN模型结构
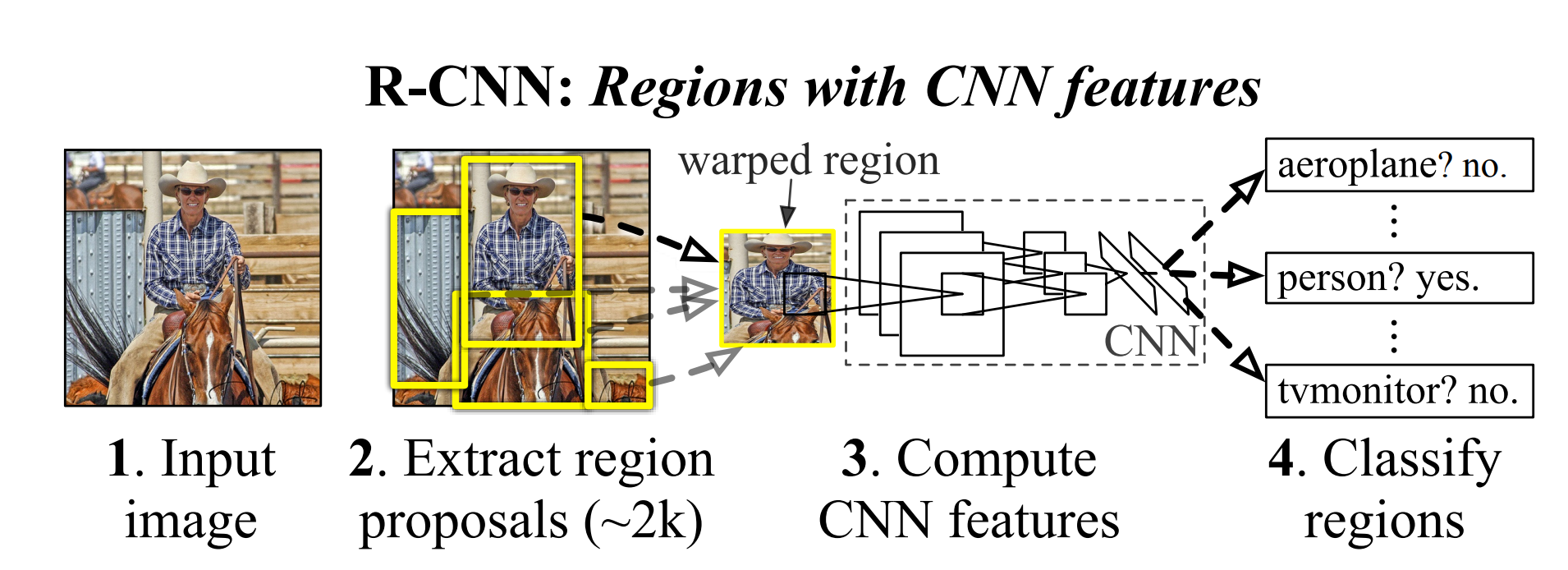
R-CNN是一种基于Region Proposal的CNN网络结构,Region Proposals 是指可能包含目标对象的图像区域的候选集合。
换句话说,它们是图像中那些可能包含想要检测的对象的区域。在 R-CNN 和类似模型中,这些区域会进一步被处理以确定它们确实包含对象,并且确定对象的类型和位置。算法流程如下(以AlexNet网络为基准):
- 区域提名(Region Proposal):通过区域提名的方法从原始图片中提取2000个左右的区域候选框,一般选择Selective Search(SS);
- 区域大小归一化:将所有候选框大小缩放固定大小(eg:227*227);
- 特征提取:通过CNN网络,对每个候选区域框提取高阶特征,将高阶特征保存磁盘;
- 分类与回归:在高阶特征的基础上添加两个全连接层,再使用SVM分类器来进行识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归器(类似OverFeat的class specific结构)。
候选区域的生成
采用一定区域候选算法(Selective Search)将图像分割成小区域,然后合并包含同一物体可能性高的区域作为候选区域输出,这里也需要采用一些合并策略。不同候选区域会有重合部分,如下图所示(黑色框是候选区域):

Selective Search在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
截取与缩放
传统的CNN限制了输入必须固定大小,所以在实际使用中往往需要对原图片进行crop(裁剪) 或 **warp(几何变换/扭曲)**的操作。
首先,截取原图片的一个固定大小的patch,然后将原图片的ROI(Region of Interest , “感兴趣区域”)缩放到一个固定大小的patch。无论是截取还是缩放,都无法保证在不失真的情况下将图片传入到CNN当中。会使用一些方法尽量让图片保持最小的变形:
- 各向异性缩放:即直接缩放到指定大小,这可能会造成不必要的图像失真;
- 各向同性缩放:在原图上出裁剪侯选区域, (采用侯选区域的像素颜色均值)填充到指定大小在边界用固定的背景颜色。

特征提取
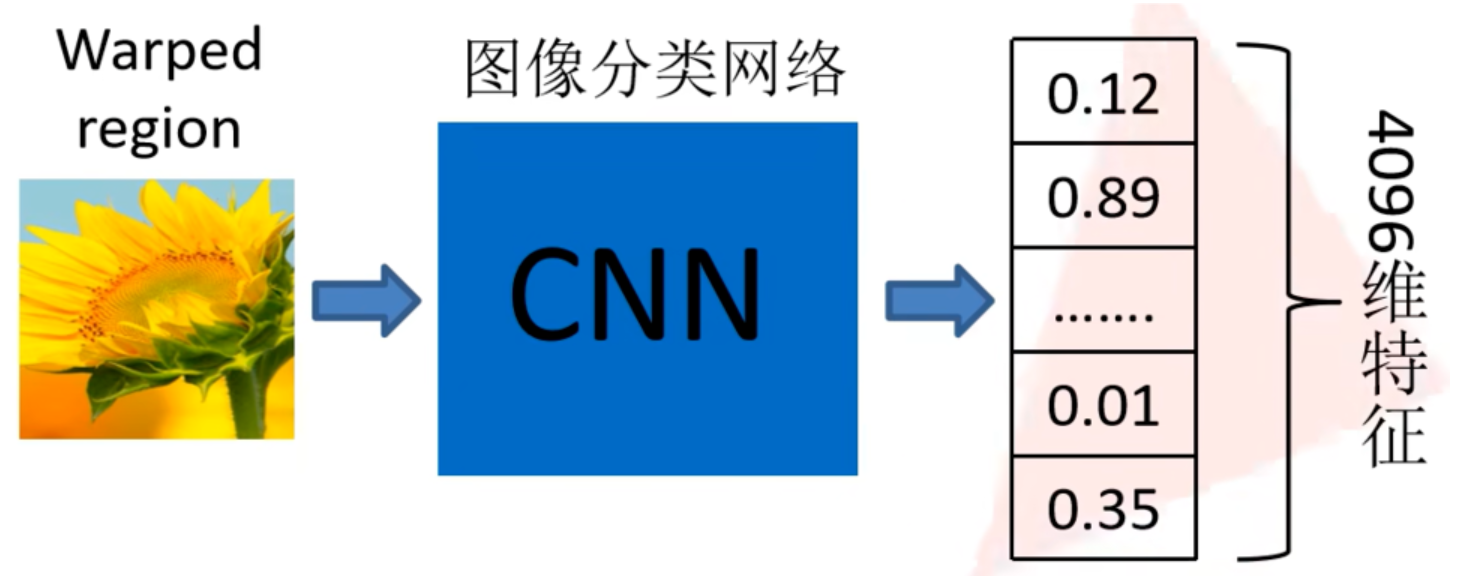
事先选择一个预训练神经网络(如AlexNet、VGG),并重新训练全连接层,即微调技术的应用。通常涉及到将 CNN 的最后一层(全连接层)替换为新的层,然后在新数据集上继续训练。
在训练时,根据 IoU 阈值(大于0.5为正样本,小于0.5为负样本)来选择用于训练的样本。然后将候选区域输入训练好的AlexNet CNN网络,得到固定维度的特征输出(4096维),得到2000×4096的特征矩阵。
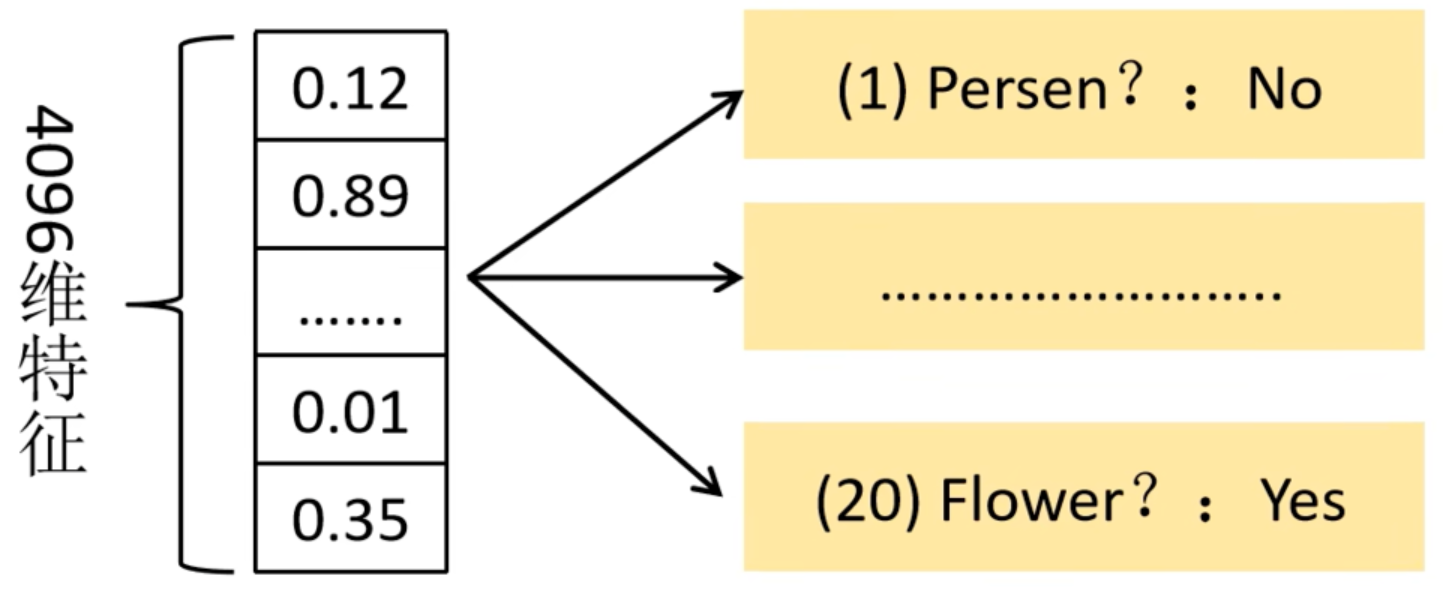
SVM分类器
以PASCAL VOC数据集为例,该数据集中有20个类别,因此设置20个SVM分类器。将 2000×4096 的特征与20个SVM组成的权值矩阵 4096×20 相乘,获得 2000×20 维的矩阵,表示2000个候选区域分别属于20个分类的概率,因此矩阵的每一行之和为1。
最后,分别对上述2000×20维矩阵中每一列(即每一类)进行非极大值抑制剔除重叠建议框,得到该列即该类中概率最大的一些候选框。
非极大值抑制
首先定义 IoU 指数(Intersection over Union),即 (A∩B) / (AUB) ,即AB的重合区域面积与AB总面积的比。
- 直观上来讲 IoU 就是表示AB重合的比率, IoU越大说明AB的重合部分占比越大,即A和B越相似。
然后找到每一类中2000个候选区域中概率最高的区域,计算其他区域与该区域的IoU值,删除所有IoU值大于阈值的候选区域。这样可以只保留少数重合率较低的候选区域,去掉重复区域。
比如下面的例子,A是向日葵类对应的所有候选框中概率最大的区域,B是另一个区域,计算AB的IoU,其结果大于阈值,那么就认为AB属于同一类(即都是向日葵),所以应该保留A,删除B,这就是非极大值抑制。

使用 SVM 进行二分类的一个问题是样本不均衡:背景图片很多,前景图片很少;导致 SVM 的训练需要解决样本不均衡的问题。
修正候选区域
通过 Selective Search算法得到的候选区域位置不一定准确,因此用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的目标区域。
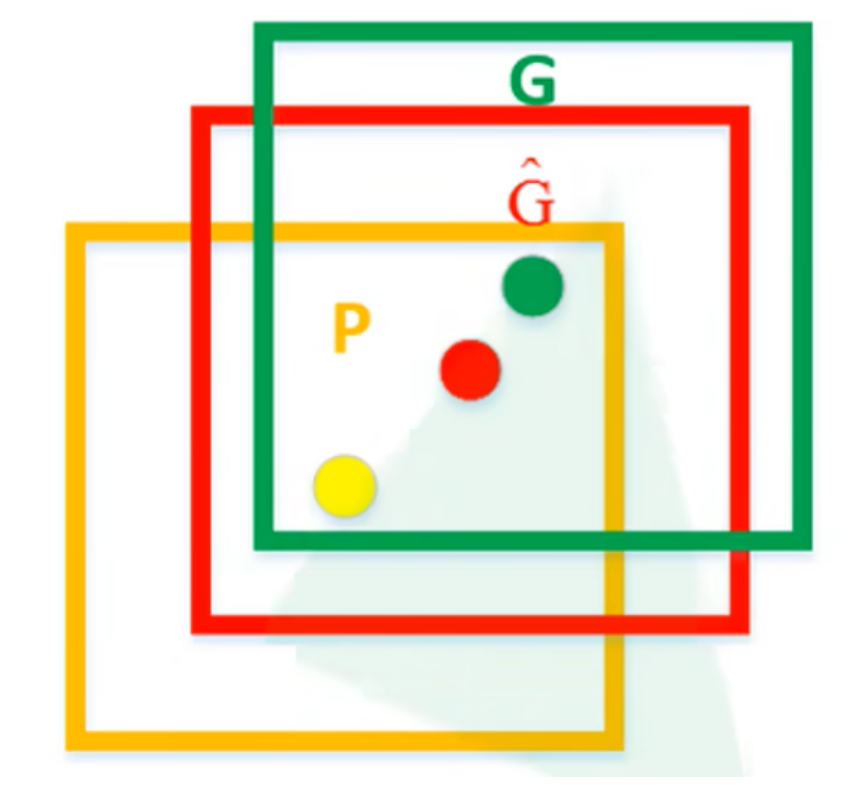
如图,黄色框表示候选区域 Region Proposal,绿色窗口表示实际区域Ground Truth(人工标注的),红色窗口表示 Region Proposal 进行回归后的预测区域,可以用最小二乘法解决线性回归问题。
通过回归器可以得到候选区域的四个参数,分别为:候选区域的x和y的偏移量,高度和宽度的缩放因子。可以通过这四个参数对候选区域的位置进行精修调整,就得到了红色的预测区域。
总结
R-CNN由四个部分组成:SS算法、CNN、SVM、bbox regression。

- 区域提议 (Region Proposals):使用选择性搜索 (Selective Search) 生成约 2000 个候选框。
- 特征提取 (Feature Extraction):将每个候选框缩放后输入 CNN (如 AlexNet) 提取 4096 维特征。
- 分类 (Classification):使用 SVM (支持向量机) 对特征进行分类。
- 回归 (Regression):使用线性回归模型修正边界框位置。
优点
- 精度革命:首次将深度学习引入目标检测,将检测精度(mAP)从传统方法的 ~33% 大幅提升至 53.7%,确立了 CNN 在该领域的统治地位。
- 特征强大:证明了预训练的 CNN 特征远超手工设计特征(如 HOG/SIFT),且具有极强的迁移学习能力。
- 架构灵活:模块化设计(提议->特征->分类->回归),允许单独优化每个环节。
缺点
- 速度极慢:对每个候选框独立进行卷积计算,导致大量重复运算。处理一张图需 40~50秒,无法实时应用。
- 训练繁琐:流程割裂(多阶段串行),需分别训练 CNN、SVM 和回归器,无法端到端联合优化。
- 资源消耗大:需将数百万个候选框的特征保存到磁盘,占用 海量存储空间 (GB/TB级)。
- 依赖外部:候选框生成依赖传统的“选择性搜索”算法,速度慢且不可学习。
一句话总结:R-CNN 是**“高精度的开创者”,但因“速度慢、训练难”**而被后续的 Fast/Faster R-CNN 迅速迭代取代。