
优化算法
深度学习中的优化算法是训练神经网络的核心,旨在通过最小化损失函数来更新模型参数。
凸性
凸性(convexity)在优化算法的设计中起到至关重要的作用, 这主要是由于在这种情况下对算法进行分析和测试要容易。在进行凸分析之前,我们需要定义凸集(convex sets)和凸函数(convex functions)。
凸集 (Convex Set)
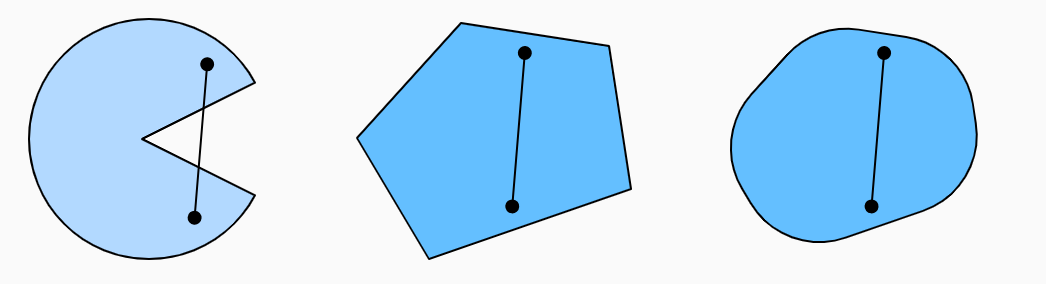
定义:集合中任意两点间的线段仍完全属于该集合。
- 简单地说,如果对于任何 , 连接a和b的线段也位于 中,则向量空间中的一个集合是凸(convex)的。 在数学术语上,这意味着对于所有,我们得到:
- 简单地说,如果对于任何 , 连接a和b的线段也位于 中,则向量空间中的一个集合是凸(convex)的。 在数学术语上,这意味着对于所有,我们得到:
意义:在凸集上优化时,局部最优解即为全局最优解(若目标函数也是凸的)。
特性:
第一组是非凸的,另外两组是凸的。
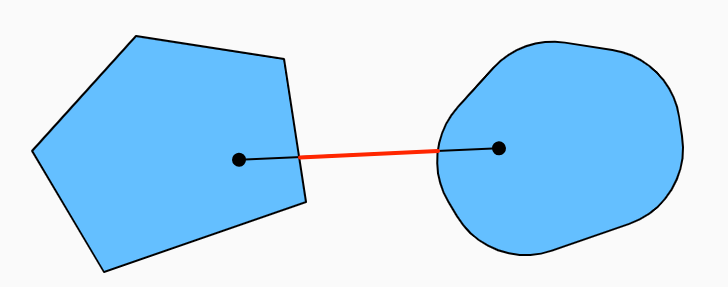
两个凸集的交集是凸的。
两个凸集的并集不一定是凸的。
凸函数 (Convex Function)
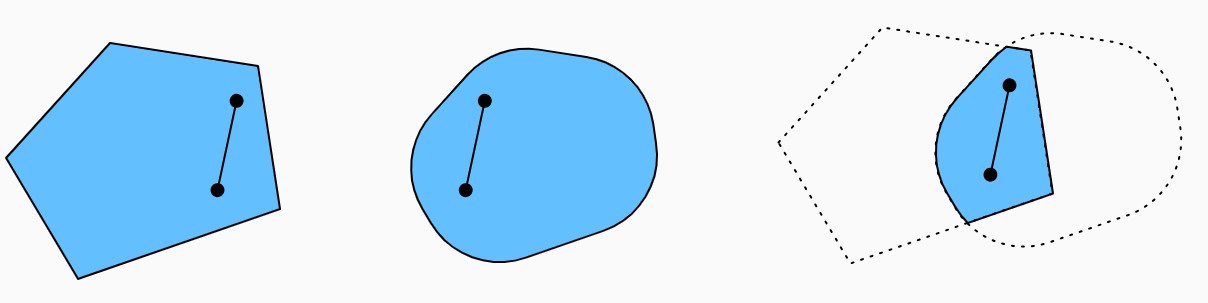
定义:函数图像上任意两点间的线段位于图像上方。
- 即给定一个凸集,如果对于所有和所有,函数是凸的,我们可以得到
性质:
- 局部最小值 = 全局最小值。
- 梯度下降可保证收敛到全局最优。
深度学习的现实:神经网络的损失函数通常是非凸的(存在多个局部极小值和鞍点),但优化算法仍能有效工作。
梯度下降
(2) 批量梯度下降
一维梯度下降
一维梯度下降(1D Gradient Descent)是优化算法中最基础的形式,用于寻找单变量函数 的最小值。
核心思想
梯度下降通过迭代方式更新参数。在每一步,计算当前点的导数(即一维情况下的“梯度”),然后沿着导数的反方向移动一小步。因为导数表示函数增长最快的方向,所以反方向就是函数下降最快的方向。
更新公式
对于单变量函数 ,第 次迭代的更新规则为:
其中:
- :当前时刻的参数值。
- :函数在 处的导数(斜率)。
- (Eta):学习率 (Learning Rate),控制每一步移动的幅度()。
- :更新后的参数值。
直观解释
- 如果 :说明函数在当前点处于上升阶段(斜率为正),为了减小函数值,我们需要向左移动(减小 )。公式中 会使 。
- 如果 :说明函数在当前点处于下降阶段(斜率为负),为了减小函数值,我们需要向右移动(增大 )。公式中 会使 。
- 如果 :到达极值点(可能是最小值、最大值或鞍点),不再更新。
进一步理解
梯度下降 (Gradient Descent, GD),通常特指批量梯度下降 (Batch Gradient Descent, BGD),是优化算法中最基础的形式。它的核心特点是:在每次更新参数时,使用整个训练数据集来计算损失函数的梯度。
公式:
其中 是训练样本总数。这意味着每走一步,都要遍历所有数据。
(2) 随机梯度下降 (Stochastic Gradient Descent, SGD)
- 原理:每次迭代仅用一个样本计算梯度。
- 公式:
- 优点:计算快,可在线学习,能跳出局部极小值(因噪声)。
- 缺点:梯度波动大,收敛路径震荡,可能无法精确收敛到最小值。
(3) 小批量随机梯度下降 (Mini-batch SGD)
- 原理:每次迭代使用一小批样本(如 32、64、128 个)计算梯度。
- 公式:
( 为批量大小)
- 优势:
- 平衡计算效率与梯度稳定性。
- 利用矩阵运算加速(向量化)。
- 实际深度学习中的默认选择。
改进优化算法
(1) 动量法 (Momentum)
核心思想:引入“惯性”,累积历史梯度方向以加速收敛并抑制震荡。
公式:
( 通常取 0.9, 为速度向量)
效果:
- 在平坦区域加速。
- 在震荡方向(如峡谷地形)抑制摆动。
理解:
速度向量 不是直接计算出来的(不像梯度 那样通过求导得到),而是通过迭代更新(递归累积)得到的。
你可以把它理解为一个**“滚雪球”**的过程:当前的速度 = 上一刻的速度(保留惯性) + 当前的梯度(新的推力)。
具体步骤:从 0 开始怎么算?
速度向量的获取是一个逐步累积的过程。假设我们要优化一个有 2 个参数 的模型,那么速度向量 也是一个 2 维向量 。
第 0 步:初始化 (Initialization)
在训练开始前,我们没有任何历史速度,所以将所有速度分量初始化为 0。
第 1 次迭代 (t=1)
- 计算梯度:算出当前位置的梯度 。
- 假设 。
- 更新速度:
此时, 完全由当前梯度决定,因为之前没有速度。
第 2 次迭代 (t=2)
- 计算梯度:算出新位置的梯度 。
- 假设方向没变,梯度稍微变小:。
- 更新速度(关键步骤):
注意:速度变大了!因为旧速度(0.018)和新梯度贡献(0.018)方向一致,叠加了。这就是加速。
第 3 次迭代 (t=3) - 假设发生震荡
- 计算梯度:假设撞到了山谷壁,梯度方向反转。
- (x方向反向了)。
- 更新速度:
注意 x 分量:之前的速度是 0.0324,加上负的梯度贡献 -0.015,结果变小了(0.0174)。这就是抵消震荡,速度没有因为反向梯度而剧烈反转,而是被惯性“拉”住了。*
(2) Adam (Adaptive Moment Estimation)
- 核心思想:结合动量法与自适应学习率(类似 RMSProp),对每个参数动态调整步长。
- 步骤:
- 计算一阶矩(均值,类似动量):
- 计算二阶矩(未中心化的方差):
- 偏差修正(避免初期估计偏小):
- 参数更新:
- 计算一阶矩(均值,类似动量):
- 默认参数:。
- 优势:
- 自动适应不同参数的梯度尺度。
- 对超参数(如学习率)鲁棒性强。
- 目前最流行的默认优化器。
4. 算法对比与选择建议
| 算法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| BGD | 小规模凸优化问题 | 理论收敛保证 | 计算慢,内存需求高 |
| SGD | 在线学习、大数据集 | 简单,可跳出局部最优 | 震荡严重,需精细调学习率 |
| Mini-batch SGD | 大多数深度学习任务 | 效率与稳定性平衡 | 仍需手动调学习率 |
| Momentum | 损失函数存在峡谷或平坦区域 | 加速收敛,减少震荡 | 增加一个超参数 |
| Adam | 默认首选(尤其复杂非凸问题) | 自适应学习率,收敛快,鲁棒 | 可能泛化性略逊于调优后的 SGD |
注:近年研究发现,在某些任务(如图像分类)中,精心调参的 SGD + 动量 可能比 Adam 获得更好的泛化性能,但 Adam 仍是快速原型开发的首选。