
目标检测
概念
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
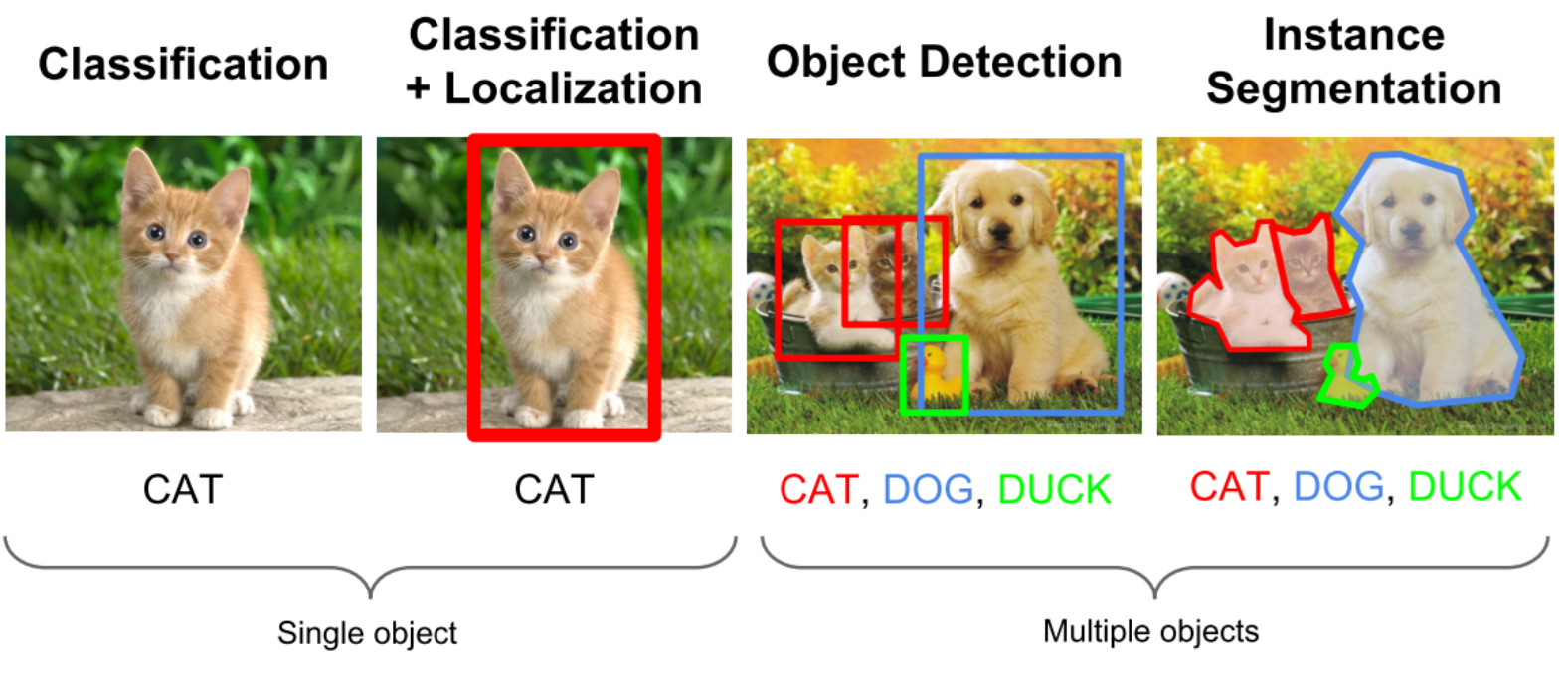
计算机视觉中关于图像识别有四大类任务:
(1)分类-Classification:给定一张图片或一段视频判断里面包含什么类别的目标。
(2)定位-Location:定位出这个目标的的位置。
(3)检测-Detection:定位出这个目标的位置并且知道目标物是什么。
(4)分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
Anchor Boxes(锚框)
在目标检测任务中,需要预测图像中物体的位置(用边界框表示,即(x, y, w, h))和类别。
核心问题:对于一张图像,我们不知道物体会出现多少个、出现在哪里、是什么形状。网络如何从“无结构”的像素输出“结构化”的边界框预测?
核心思想:
- 预先在图像的每个位置(特征图(Feature Map)上的点)定义一系列具有不同大小和宽高比的“参考框”(即锚框)。
- 然后,网络的任务不再是“凭空”预测一个框,而是 “基于这些锚框,预测其微调偏移量和类别”。
这本质上将“回归一个任意框”的问题,转换为了 “对参考框进行分类和精细调整” 的问题,极大地简化了学习难度。
解决的问题:
- 尺度与形状多样性:不同物体大小、形状各异,锚框提供了多种预设模板。
- 多物体检测:一个位置可以放置多个不同形状的锚框,从而覆盖多个重叠的物体。
- 训练稳定性:直接回归框的绝对坐标值可能导致梯度不稳定,而回归相对偏移量(相对于锚框)的数值范围更小、更容易学习。
锚框的生成原理
通常在特征图(Feature Map)的每个像素点上生成。
特征图的生成过程
- 输入:一张 640×640 的“无结构”像素图。
- 特征提取:CNN 将其压缩为 20×20 的特征图(假设 Stride=32)。此时数据变成了 20×20×C的结构化张量。
- 定义位置:我们将这 20×20 个点视为“预测中心”。
- 计算公式:
- 点 (0,0) 对应原图中心约 (16,16) 。
- 点 (19,19)对应原图中心约 (624,624) 。
- 注意:原图四个角最边缘的像素(0-15, 625-639 区域)没有直接对应的独立中心点,它们的特征被融合进了最近的中心点中。
- 计算公式:
- 生成锚框:在每个中心点上,放置 9 个预设好的框(k = 尺度数 × 宽高比数,3 种大小 × 3 种比例)。全图共 20×20×9=3600 个锚框。
- 尺度:锚框的大小。例如,
[32, 64, 128]像素(对应原始图像尺寸)。 - 宽高比:锚框的宽度和高度的比例。例如,
[1:1, 2:1, 1:2]通常写作[1.0, 2.0, 0.5]。 - 锚框的宽
w和高h的计算通常为(以某个尺度s和宽高比r为例):w = s * sqrt(r)h = s / sqrt(r)- 例如,尺度
s=64, 宽高比r=2,则w = 64 * 1.414 ≈ 90.5,h = 64 / 1.414 ≈ 45.2。
- 尺度:锚框的大小。例如,
- 网络预测:
- 网络不再预测“框在哪里”,而是针对这 3600 个已知的框,预测两个值:
- 分类分数:这个框里是猫、狗还是背景?
- 回归偏移量: (Δx,Δy,Δw,Δh),即“为了让这个锚框完美包住物体,我需要把它向左移多少、放大多少?”
- 网络不再预测“框在哪里”,而是针对这 3600 个已知的框,预测两个值:
- 输出:将偏移量应用到锚框上,得到最终的边界框。
锚框如何工作
训练阶段
训练的核心是 “匹配策略” 和 “监督信号的构建”。
正负样本分配:
- 正样本:通常,一个锚框如果与任意真实框的 IoU(交并比) 大于一个高阈值(如 0.7),则标记为正样本。
- 或者,对于每个真实框,与其 IoU 最大的锚框也标记为正样本(确保每个物体至少有一个锚框负责)。
- 负样本:与所有真实框的 IoU 都小于一个低阈值(如 0.3)的锚框,标记为负样本(背景)。
- 忽略样本:IoU 介于高低阈值之间的锚框通常不参与训练,以避免模糊样本。
- 正样本:通常,一个锚框如果与任意真实框的 IoU(交并比) 大于一个高阈值(如 0.7),则标记为正样本。
监督信号的构建:
- 分类任务:
- 对于正样本,其类别标签是与之匹配的真实框的类别;
- 对于负样本,其类别标签是背景(通常记为 0)。
- 回归任务:仅对正样本进行边界框回归。网络不是直接预测框的绝对坐标,而是预测 “从锚框变换到匹配的真实框所需的微调偏移量”。这通常包括四个值:
tx = (gx - ax) / aw(中心点 x 坐标的平移,归一化)ty = (gy - ay) / ah(中心点 y 坐标的平移,归一化)tw = log(gw / aw)(宽度缩放的对数变换)th = log(gh / ah)(高度缩放的对数变换)- 其中
(ax, ay, aw, ah)是锚框的中心坐标和宽高,(gx, gy, gw, gh)是匹配的真实框的中心坐标和宽高。
- 分类任务:
预测阶段
- 生成预测:网络为每个锚框输出两个部分:
- 分类得分:一个
(C+1)维向量(C 个物体类 + 背景),表示属于每个类别的概率。 - 边界框回归偏移量:一个 4 维向量
(tx, ty, tw, th)。
- 分类得分:一个
- 解码:使用与训练时相同的公式的逆运算,将预测的偏移量应用于对应的锚框,得到预测框在原始图像中的坐标:
px = aw * tx + axpy = ah * ty + aypw = aw * exp(tw)ph = ah * exp(th)
- 后处理:
- 非极大值抑制(NMS):由于成千上万个锚框会产生大量重叠的预测框,NMS 会过滤掉那些与得分最高的预测框重叠度高(IoU 大)且得分较低的框,只保留最简洁、最准确的预测结果。
总结
Anchor Boxes 是一种将先验知识注入目标检测网络的强大技术。
- 它通过提供一组预设的参考框,将复杂的检测问题分解为对每个参考框的“分类(是哪种物体/背景)”和“微调(如何调整得更准)”两个相对简单的子问题,奠定了两阶段和许多单阶段检测器的基础。