
线性模型
线性模型(Linear Model)是统计学和机器学习中最基础、最广泛应用的一类模型。它假设目标变量与一个或多个输入特征之间存在线性关系。
基本形式
对于一个有 p 个特征的样本,线性模型的预测值为:
其中:
- :预测值。
- :截距 或 偏置项。
- :系数 或 权重,对应每个特征的重要性。
- :样本的特征值。
用向量形式表示更加简洁:
线性模型可以看作单层神经网络
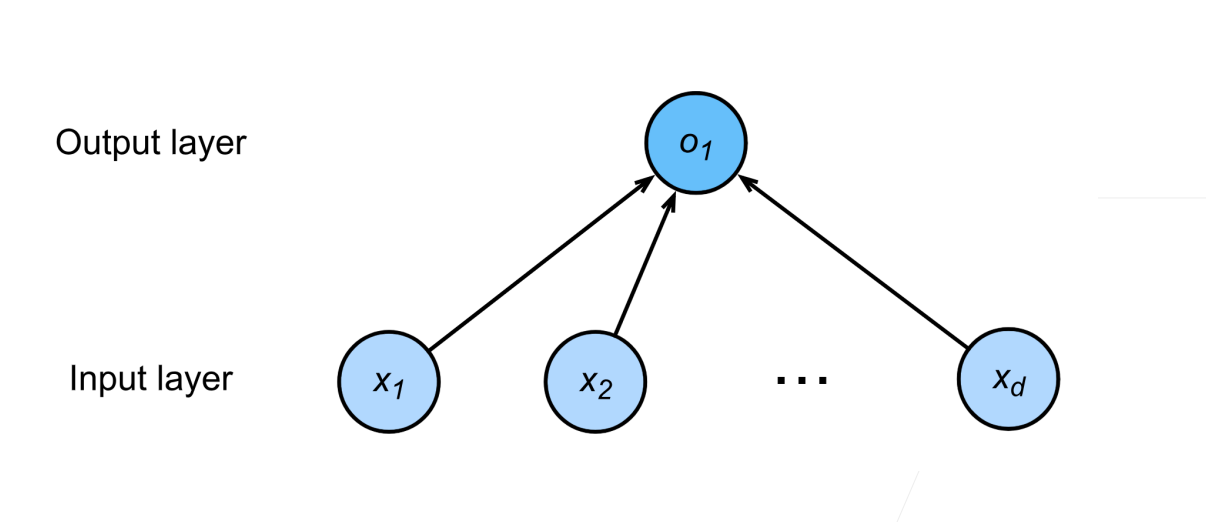
二、常见类型
线性回归(Linear Regression)
- 用于连续目标变量。
- 损失函数常为均方误差(MSE):
- 解析解(普通最小二乘法 OLS):
逻辑回归(Logistic Regression)
- 虽名为“回归”,实为分类模型(通常是二分类)。
- 使用 sigmoid 函数将线性组合映射到概率:
岭回归(Ridge Regression)与 Lasso 回归
- 引入正则化防止过拟合:
岭回归:
Lasso:
- 引入正则化防止过拟合:
三、优点
- 可解释性强:每个特征的系数直接反映其对输出的影响方向和大小。
- 计算高效:训练和预测速度快,尤其在特征维度不高时。
- 理论成熟:有完善的统计推断框架(如假设检验、置信区间等)。
四、局限性
- 线性假设强:无法捕捉非线性关系(除非手动构造高阶/交互特征)。
- 对异常值敏感(尤其是普通最小二乘)。
- 多重共线性问题:当特征高度相关时,参数估计不稳定。
五、扩展与应用
- 广义线性模型(GLM):将线性预测器通过链接函数连接到指数族分布的期望(如泊松回归、逻辑回归都属于 GLM)。
- 线性判别分析(LDA):虽不是严格意义上的线性模型,但决策边界是线性的。
- 在深度学习中:全连接层(Dense Layer)本质就是线性变换 + 非线性激活。
实践
具体运行内容可见:
详情
<!-- #include-env-start: D:/code/klc/test/share4ai/docs/book/dive_into_on_dl/dl_basic -->
```python
import random
import torch
# 线性模型参数
# 根据带有噪声的线性模型构造一个人造数据集。 我们使用线性模型参数w=[2,−3.4]⊤、b=4.2和噪声项ϵ生成数据集及其标签:y=Xw+b+ϵ
true_w = torch.tensor([2, -3.4])
true_b = 4.2
true_w,true_b
(tensor([ 2.0000, -3.4000]), 4.2)
# 构建人造数据集
#使用 torch.normal(mean, std, size) 从标准正态分布(均值为 0,标准差为 1)中随机采样。生成形状为 (nums_example, len(w)) 的张量 X。
# torch.matmul(X, w) 是矩阵乘法
def create_data(w, b, nums_example):
X = torch.normal(0, 1, (nums_example, len(w))) # 1000x2
y = torch.matmul(X, w) + b # 1000x2 x 2 + 1
print("y_shape:", y.shape)
y += torch.normal(0, 0.01, y.shape) # 加入噪声
return X, y.reshape(-1, 1) # y从行向量转为列向量
features, labels = create_data(true_w, true_b, 1000)
y_shape: torch.Size([1000])
# 读数据集
def read_data(batch_size, features, lables):
nums_example = len(features)
indices = list(range(nums_example)) # 生成0-999的元组,然后将range()返回的可迭代对象转为一个列表
random.shuffle(indices) # 将序列的所有元素随机排序。
for i in range(0, nums_example, batch_size): # range(start, stop, step)
index_tensor = torch.tensor(indices[i: min(i + batch_size, nums_example)])
yield features[index_tensor], lables[index_tensor] # 通过索引访问向量
batch_size = 10
for X, y in read_data(batch_size, features, labels):
print("X:", X, "\ny", y)
break;
X: tensor([[ 0.7177, 0.4722],
[-1.7149, 1.2582],
[ 2.0986, -1.6757],
[-0.0352, -1.3807],
[ 0.7049, -0.8611],
[ 0.5767, -0.6256],
[ 1.8972, -1.1276],
[-1.1685, 0.5828],
[ 1.4574, 0.5796],
[ 0.1173, -1.5745]])
y tensor([[ 4.0115],
[-3.4985],
[14.0839],
[ 8.8337],
[ 8.5391],
[ 7.4879],
[11.8439],
[-0.0963],
[ 5.1459],
[ 9.8055]])
#初始化参数
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
w,b
(tensor([[ 0.0047],
[-0.0054]], requires_grad=True),
tensor([0.], requires_grad=True))
# 定义模型
def net(X, w, b):
return torch.matmul(X, w) + b
# 定义损失函数
def loss(y_hat, y):
# print("y_hat_shape:",y_hat.shape,"\ny_shape:",y.shape)
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2 # 这里为什么要加 y_hat_shape: torch.Size([10, 1]) y_shape: torch.Size([10])
# 定义优化算法
def sgd(params, batch_size, lr):
with torch.no_grad(): # with torch.no_grad() 则主要是用于停止autograd模块的工作,
for param in params:
param -= lr * param.grad / batch_size ## 这里用param = param - lr * param.grad / batch_size会导致导数丢失, zero_()函数报错
param.grad.zero_() ## 导数如果丢失了,会报错‘NoneType’ object has no attribute ‘zero_’
# 训练模型
lr = 0.03
num_epochs = 3
for epoch in range(0, num_epochs):
for X, y in read_data(batch_size, features, labels):
f = loss(net(X, w, b), y)
# 因为`f`形状是(`batch_size`, 1),而不是一个标量。`f`中的所有元素被加到一起,
f.sum().backward() # 并以此计算关于[`w`, `b`]的梯度
sgd([w, b], batch_size, lr) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print("{0}th epoch:\n w {1} \nb {2} \nloss {3:f}".format(epoch, w, b, float(train_l.mean())))
print("w误差 ", true_w - w, "\nb误差 ", true_b - b)
0th epoch:
w tensor([[ 2.0008],
[-3.3998]], requires_grad=True)
b tensor([4.2002], requires_grad=True)
loss 0.000048
1th epoch:
w tensor([[ 2.0004],
[-3.4001]], requires_grad=True)
b tensor([4.1996], requires_grad=True)
loss 0.000048
2th epoch:
w tensor([[ 2.0008],
[-3.4002]], requires_grad=True)
b tensor([4.2001], requires_grad=True)
loss 0.000048
w误差 tensor([[-7.5245e-04, -5.4008e+00],
[ 5.4002e+00, 2.4295e-04]], grad_fn=<SubBackward0>)
b误差 tensor([-0.0001], grad_fn=<RsubBackward1>)