
数据预处理
概念
机器学习中的数据预处理(Data Preprocessing) 是建模前最关键的步骤之一,直接影响模型性能。高质量的预处理能提升模型的准确性、稳定性和泛化能力。
🧹 1. 数据清洗(Data Cleaning)
常见问题:
- 缺失值(Missing values)
- 异常值(Outliers)
- 重复数据(Duplicates)
- 不一致格式(如日期、单位)
处理方法:
- 缺失值:使用
SimpleImputer、KNNImputer或删除 - 异常值:IQR 法、Z-score、或使用鲁棒模型(如 Isolation Forest)
- 去重:
pandas.DataFrame.drop_duplicates()
🔢 2. 特征缩放(Feature Scaling)
许多算法(如 SVM、KNN、神经网络、PCA)对特征尺度敏感。
常用方法:
| 方法 | 说明 | 适用场景 |
|---|---|---|
| StandardScaler | 标准化: | 数据近似正态分布 |
| MinMaxScaler | 归一化到 [0, 1]: | 神经网络、图像像素 |
| RobustScaler | 使用中位数和 IQR,抗异常值 | 含异常值的数据 |
| MaxAbsScaler | 按最大绝对值缩放,保留稀疏性 | 稀疏数据(如文本 TF-IDF) |
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
✅ 注意:先
fit在训练集上,再transform训练集和测试集,避免数据泄露!
🔠 3. 类别特征编码(Categorical Encoding)
机器学习模型通常只接受数值输入。
常用方法:
| 方法 | 说明 | 适用场景 |
|---|---|---|
| LabelEncoder | 将类别映射为整数(0,1,2...) | 仅用于目标变量 y(分类标签) |
| OrdinalEncoder | 对特征列做 Label 编码 | 有序类别(如“低<中<高”) |
| OneHotEncoder | 创建二元虚拟变量 | 无序类别(如颜色、城市) |
| TargetEncoder / LeaveOneOutEncoder | 用目标均值编码(需防过拟合) | 高基数类别(如用户ID) |
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
X_encoded = encoder.fit_transform(X_cat)
⚠️ 警惕 维度爆炸:若类别太多(如 >50),考虑分组、哈希编码(
HashingEncoder)或嵌入。
📏 4. 特征工程(Feature Engineering)
- 多项式特征:
PolynomialFeatures - 交互特征:手动创建或使用
ColumnTransformer - 分箱(Binning):将连续变量离散化(
KBinsDiscretizer) - 日期/时间分解:提取年、月、星期、是否周末等
from sklearn.preprocessing import KBinsDiscretizer
discretizer = KBinsDiscretizer(n_bins=5, encode='ordinal', strategy='uniform')
X_binned = discretizer.fit_transform(X_continuous)
具体步骤
第一步:导入
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('my_data.csv') #读入数据集,如下图所示
X = dataset.iloc[:, :-1].values
Y = dataset.iloc[:, 3].values
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = np.nan, strategy = ‘mean’, axis = 0)
imputer = imputer.fit(X[:, 1:3])
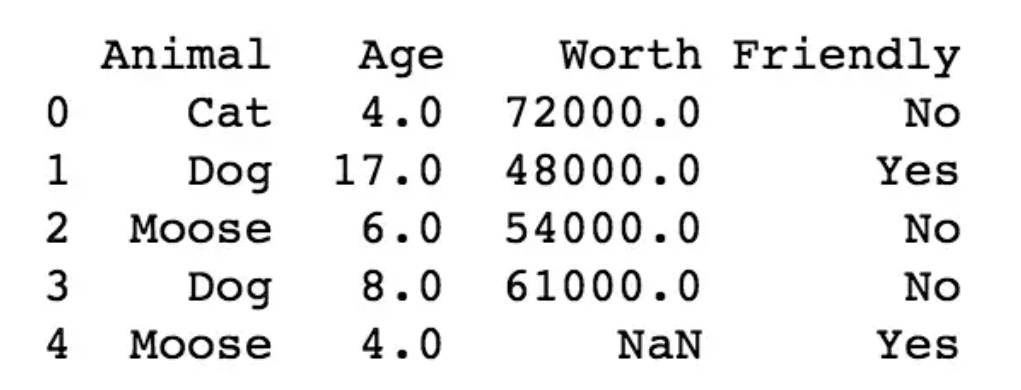
对于缺失数据的处理:
常用方法是采用所在列的均值来填充缺失。
class sklearn.impute.SimpleImputer(***, missing_values=nan, strategy='mean', fill_value=None, copy=True, add_indicator=False, keep_empty_features=False)
| 参数 | 说明 |
|---|---|
missing_values | 指定表示缺失值的值,默认是 np.nan |
strategy | 填充策略: - 'mean'(均值) - 'median'(中位数) - 'most_frequent'(众数) - 'constant'(常量,需配合 fill_value) |
fill_value | 当 strategy='constant' 时,指定填充值(如 0、"missing" 等) |
实践
具体运行内容可见:
详情
<!-- #include-env-start: D:/code/klc/test/share4ai/docs/book/dive_into_on_dl/dl_basic -->
```python
import os
import numpy as np
import pandas as pd
import torch
from numpy import nan as NaN
os.makedirs(os.path.join('.', 'data'), exist_ok=True) # 在上级目录创建data文件夹
datafile = os.path.join('.', 'data', 'house_tiny.csv') # 创建文件
with open(datafile, 'w') as f: # 往文件中写数据
f.write('NumRooms,Alley,Price\n') # 列名 房间数量、是否铺路,价格
f.write('NA,Pave,127500\n') # 第1行的值
f.write('2,NA,106000\n') # 第2行的值
f.write('4,NA,178100\n') # 第3行的值
f.write('NA,NA,140000\n') # 第4行的值
data = pd.read_csv(datafile) # 可以看到原始表格中的空值NA被识别成了NaN
print('1.原始数据:\n', data)
1.原始数据:
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
# 将数据框按列进行分割,分别提取特征(inputs)和标签(outputs)
inputs, outputs = data.iloc[:, 0: 2], data.iloc[:, 2]
print('2.inputs:\n',inputs)
print('\n')
print('3.outputs:\n', outputs)
2.inputs:
NumRooms Alley
0 NaN Pave
1 2.0 NaN
2 4.0 NaN
3 NaN NaN
3.outputs:
0 127500
1 106000
2 178100
3 140000
Name: Price, dtype: int64
# 分别处理数值列和非数值列
numeric_columns = inputs.select_dtypes(include=[np.number]).columns
non_numeric_columns = inputs.select_dtypes(exclude=[np.number]).columns
# 对数值列用均值填充
if len(numeric_columns) > 0:
inputs[numeric_columns] = inputs[numeric_columns].fillna(inputs[numeric_columns].mean())
# 对非数值列先不处理
print('4.数值类型列处理后的输入数据:\n', inputs)
4.数值类型列处理后的输入数据:
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
# 利用pandas中的get_dummies函数来处理离散值或者类别值。
# [对于 inputs 中的类别值或离散值,我们将 “NaN” 视为一个类别。] 由于 “Alley”列只接受两种类型的类别值 “Pave” 和 “NaN”
inputs = pd.get_dummies(inputs, dummy_na=True)
print('5.利用pandas中的get_dummies函数处理:\n', inputs)
5.利用pandas中的get_dummies函数处理:
NumRooms Alley_Pave Alley_nan
0 3.0 True False
1 2.0 False True
2 4.0 False True
3 3.0 False True
# 👇 关键修复:统一转为数值类型(如 float32)
inputs = inputs.astype(np.float32)
outputs = outputs.astype(np.float32)
print('6.统一转为数值类型 inputs:\n', inputs)
print('\n')
print('7.统一转为数值类型 outputs:\n', outputs)
6.统一转为数值类型 inputs:
NumRooms Alley_Pave Alley_nan
0 3.0 1.0 0.0
1 2.0 0.0 1.0
2 4.0 0.0 1.0
3 3.0 0.0 1.0
7.统一转为数值类型 outputs:
0 127500.0
1 106000.0
2 178100.0
3 140000.0
Name: Price, dtype: float32