
感知机
感知机(Perceptron)和多层感知机(Multi-Layer Perceptron, MLP)是人工神经网络发展史上的两个里程碑概念。理解它们的关键在于从线性分类到非线性映射的跨越。
感知机 (Perceptron):神经网络的“原子”
感知机由弗兰克·罗森布拉特(Frank Rosenblatt)于1957年提出,它是最简单的前馈神经网络单元,可以看作是生物神经元的数学简化模型。
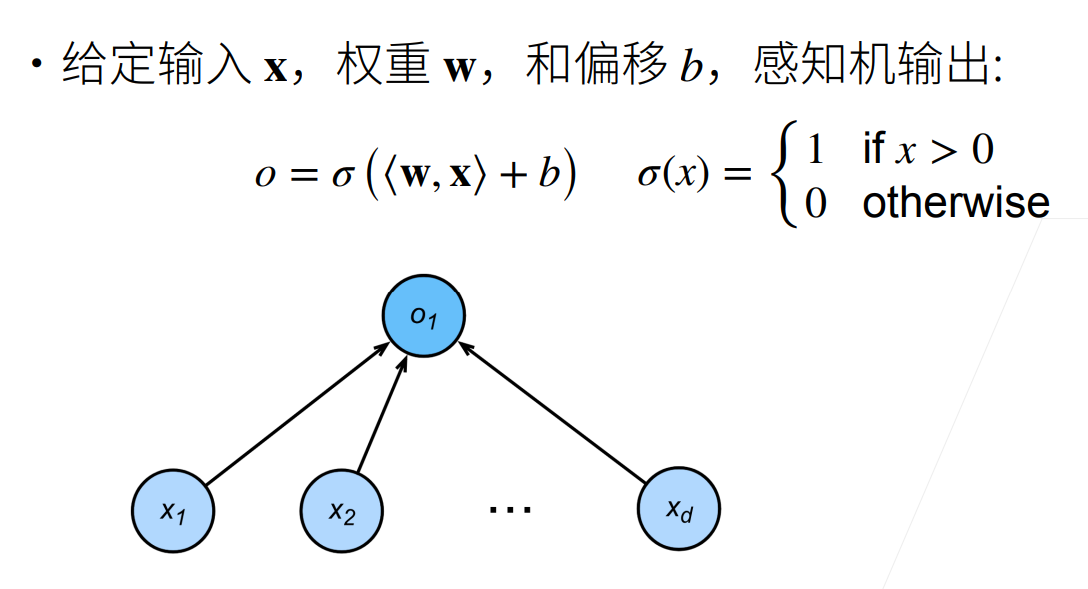
核心结构
一个标准的感知机包含三个部分:
- 输入层:接收特征向量 。
- 加权求和与偏置:计算净输入 。
其中 是权重, 是偏置(bias)。
- 激活函数:通常使用阶跃函数(Step Function)。
直观理解
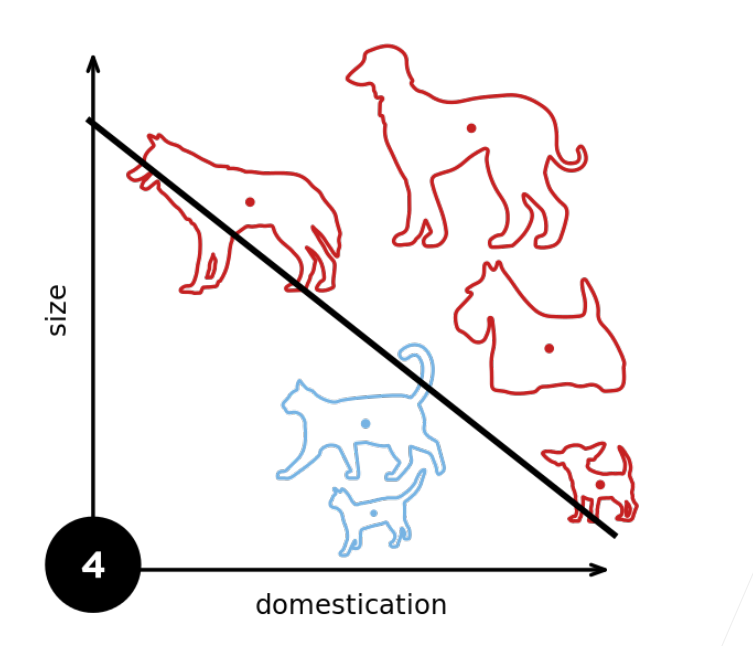
几何意义:感知机本质上是一个线性分类器。在二维空间中,它画出一条直线将数据分为两类;在三维空间中,它画出一个平面;在高维空间中,它是一个超平面。
能力边界:它只能解决线性可分的问题(例如:逻辑与 AND、逻辑或 OR)。
致命缺陷:它无法解决线性不可分的问题,最著名的例子是**异或(XOR)**问题。1969年,Minsky和Papert在《感知机》一书中证明了单层感知机的这一局限性,导致神经网络研究进入了第一个“寒冬”。
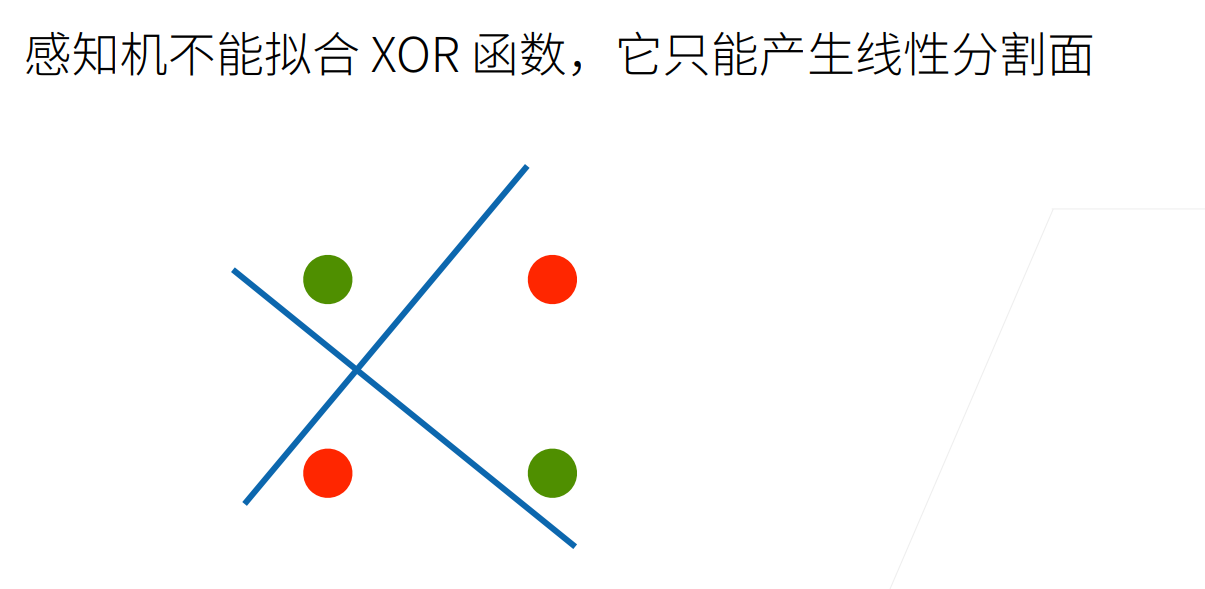
多层感知机 (MLP):突破线性限制
为了解决单层感知机无法处理非线性问题(如XOR)的缺陷,研究人员引入了隐藏层,从而诞生了多层感知机(MLP)。
核心结构
MLP 是一种前馈人工神经网络,包含:
- 输入层:接收原始数据。
- 一个或多个隐藏层:这是关键所在。每一层包含多个神经元,且层与层之间全连接(Fully Connected)。
- 输出层:产生最终预测结果。
关键进化点
非线性激活函数: MLP 中的神经元不再使用阶跃函数,而是使用可微的非线性激活函数,如 Sigmoid、Tanh 或现代常用的 ReLU (Rectified Linear Unit)。 * 为什么重要? 如果没有非线性激活函数,无论多少层网络叠加,数学上最终都等价于一个单层的线性变换(),依然无法解决非线性问题。非线性激活函数赋予了网络拟合复杂曲线的能力。
反向传播算法 (Backpropagation): 这是训练 MLP 的核心算法。
- 前向传播:数据从输入层流向输出层,计算预测值。
- 计算损失:比较预测值与真实值,计算误差(Loss)。
- 反向传播:利用链式法则(Chain Rule),将误差从输出层逐层向后传递,计算每个权重的梯度。
- 参数更新:使用梯度下降法(Gradient Descent)更新权重和偏置,使误差最小化。
万能近似定理 (Universal Approximation Theorem)
数学理论证明:只要隐藏层神经元数量足够多,包含至少一个隐藏层的 MLP 可以以任意精度逼近任何连续函数。 这意味着,理论上 MLP 可以解决任何复杂的分类和回归问题(如图像识别、自然语言处理等),只要数据量足够且网络结构合理。
核心区别
| 特性 | 感知机 (Perceptron) | 多层感知机 (MLP) |
|---|---|---|
| 层数 | 仅输入层和输出层(无隐藏层) | 输入层 + 至少一个隐藏层 + 输出层 |
| 激活函数 | 通常是阶跃函数(不可导) | Sigmoid, Tanh, ReLU 等(可导、非线性) |
| 解决问题类型 | 仅线性可分问题 (AND, OR) | 线性及非线性问题 (XOR, 图像, 语音等) |
| 训练算法 | 感知机学习规则 (简单迭代) | 反向传播 (Backpropagation) + 梯度下降 |
| 表达能力 | 弱,只能画直线/平面 | 强,可拟合任意复杂曲面 |
| 历史地位 | 神经网络的起源,但在早期遭遇瓶颈 | 现代深度学习的基础架构组件 |
总结
- 感知机是构建神经网络的“砖块”。单独一块砖(单层)只能砌直墙(线性分类)。
- 多层感知机是将这些砖块通过特定的方式(隐藏层+非线性激活)堆叠起来,并配合精妙的施工图纸(反向传播算法),从而能够建造出摩天大楼(解决复杂的AI任务)。
在现代深度学习中:
虽然我们现在很少直接称呼复杂的网络为“MLP”,但 MLP 的结构依然是现代深度学习的基石。
- 卷积神经网络 (CNN) 的全连接层部分本质上是 MLP。
- Transformer 模型中的“前馈神经网络 (Feed-Forward Network, FFN)”模块,实际上就是一个两层结构的 MLP。
- 当我们说“全连接层 (Dense Layer)”时,指的就是 MLP 中的层结构。
理解感知机到 MLP 的演变,就是理解人工智能如何从简单的逻辑判断走向处理现实世界复杂模式的关键一步。