全连接卷积神经网络
参考文献
背景与动机
在 FCN 提出之前(2014 年以前),主流的卷积神经网络(如 AlexNet、VGG)主要用于图像分类任务。这类网络通常包含:
- 多个卷积层 + 池化层(用于提取特征)
- 最后接若干全连接层(fully connected layers)进行分类。
这类网络存在的问题:
- 固定尺寸输入:为了匹配全连接层的权重矩阵,传统 CNN 通常要求输入图像被缩放到固定尺寸(如 224x224)。这会丢失细节信息。
- 输出单一:网络的最终输出是一个类别标签向量(如“猫”、“狗”),丢失了所有的空间信息。我们只知道“是什么”,但不知道“在哪里”。
- 不适用于密集预测任务:对于需要逐像素预测的任务(如语义分割、目标检测),传统 CNN 的结构天然不匹配,即无法提供像素级预测。
传统卷积神经网络的全连接层如下:
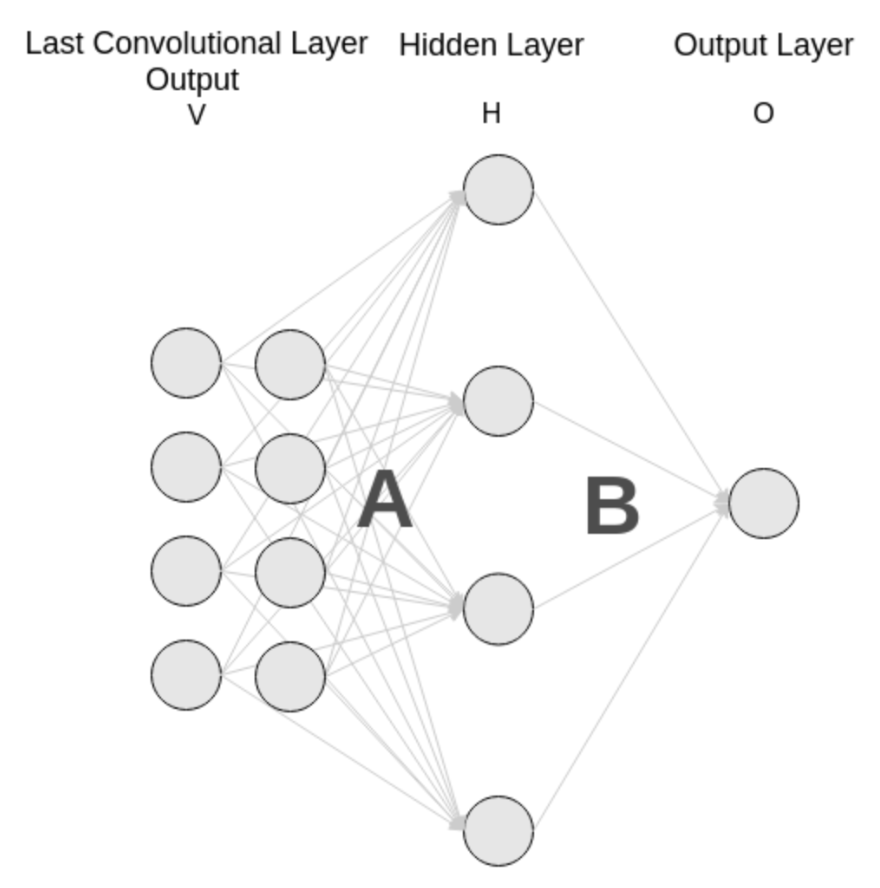
而许多计算机视觉任务(如语义分割)需要对每个像素进行分类,这就要求网络能输出与输入图像空间尺寸对应的密集预测图(dense prediction map)。
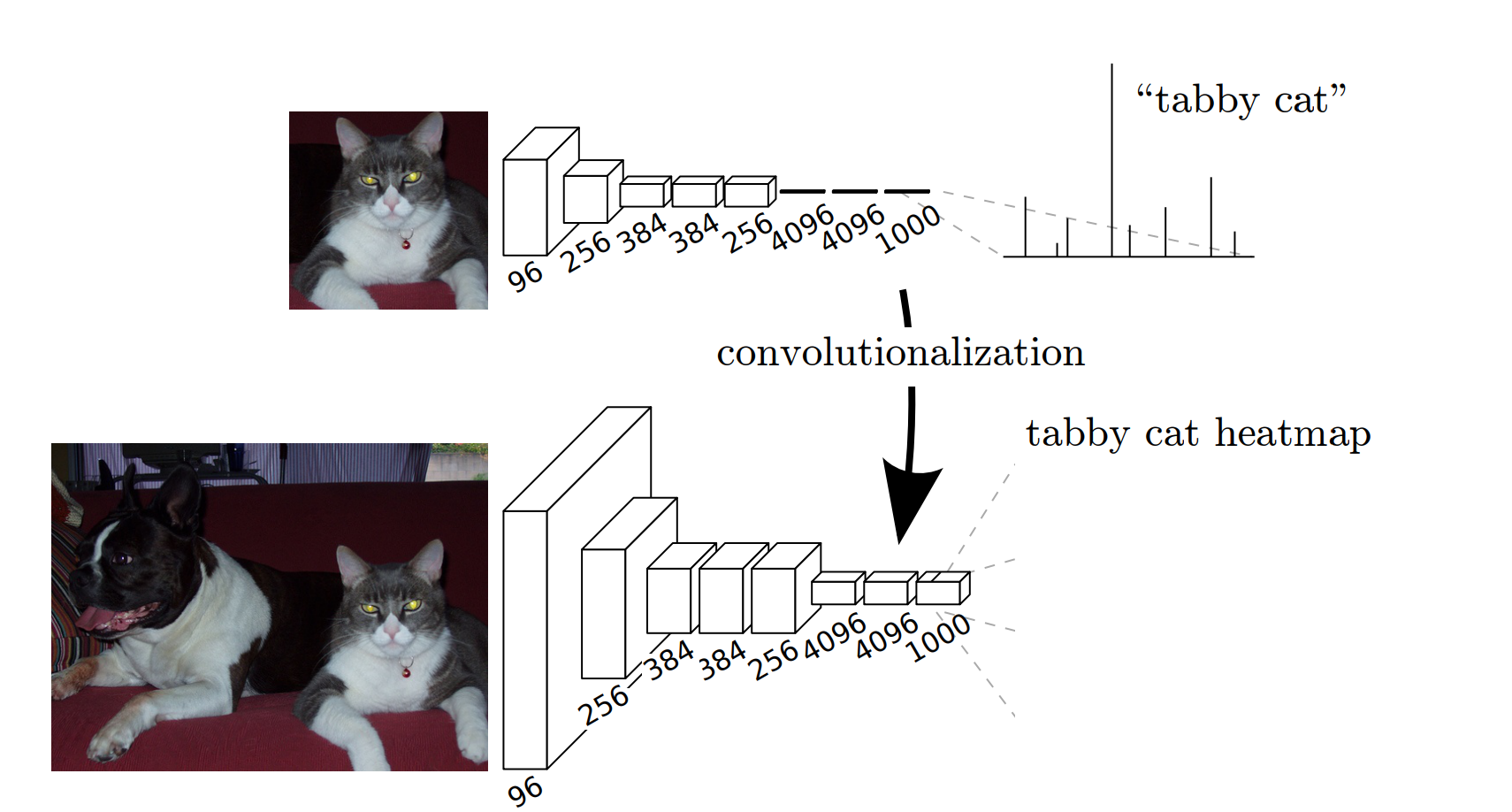
FCN 的核心思想:将传统 CNN 中的全连接层替换为卷积层,使整个网络完全由卷积操作构成,从而实现任意尺寸输入 → 像素级输出。
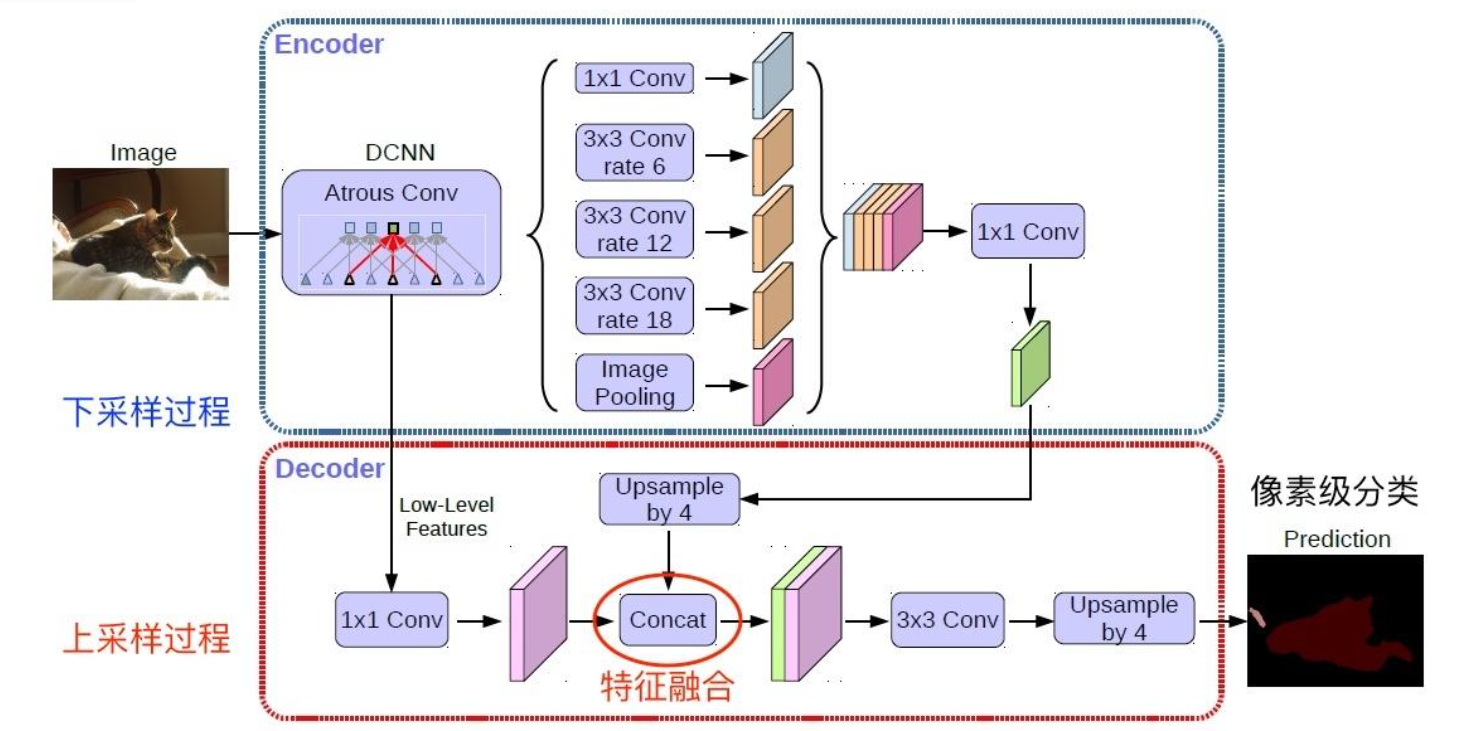
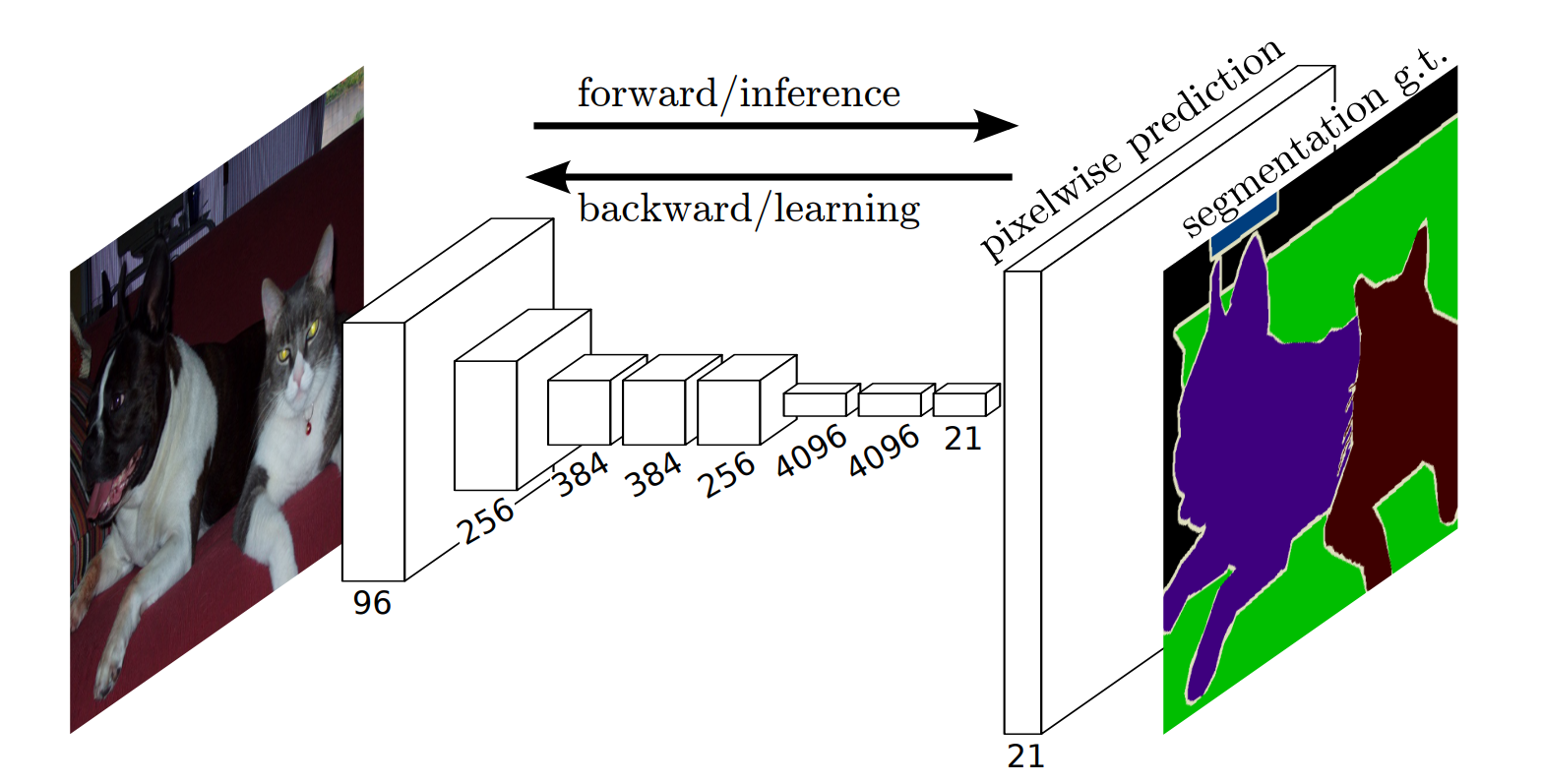
FCN把后面几个全连接都换成卷积,这样就可以获得一张2维的feature map,后接softmax获得每个像素点的分类信息,从而解决了分割问题,如图
网络结构
整个FCN网络基本原理如图所示:
- image经过多个conv和 + 一个max pooling变为pool1 feature,宽高变为1/2
- pool1 feature再经过多个conv + 一个max pooling变为pool2 feature,宽高变为1/4
- pool2 feature再经过多个conv + 一个max pooling变为pool3 feature,宽高变为1/8
- ......
- 直到pool5 feature,宽高变为1/32。
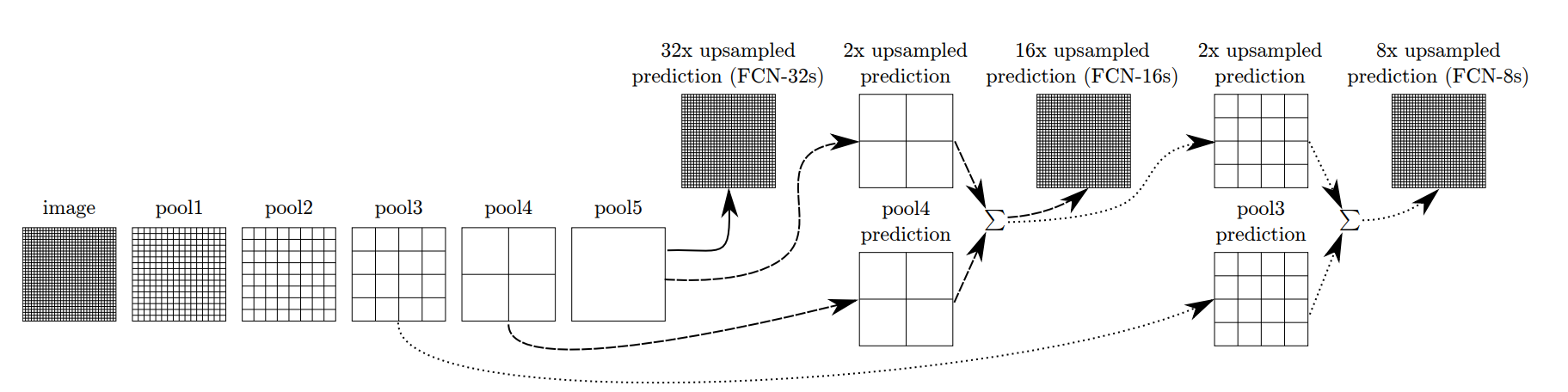
那么:
- 对于FCN-32s,直接对pool5 feature进行32倍上采样获得32 x upsampled feature,再对32 x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
- 对于FCN-16s,首先对pool4 feature进行2倍上采样获得2 x upsampled feature,再把pool4 feature和2 x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
- 对于FCN-8s,首先进行pool3 + 2x upsampled feature逐点相加,然后又进行pool3 +2 x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似,不再赘述。
作者在原文种给出3种网络结果对比,明显可以看出效果:FCN-32s < FCN-16s < FCN-8s,即使用多层feature融合有利于提高分割准确性。

上采样
上采样(upsampling)一般包括2种方式:
- Resize,如双线性插值直接缩放,类似于图像缩放;
- Deconvolution,也叫Transposed Convolution,转置卷积。
对于一般卷积,输入蓝色4x4矩阵,卷积核大小3x3。当设置卷积参数pad=0,stride=1时,卷积输出绿色2x2矩阵,如图:
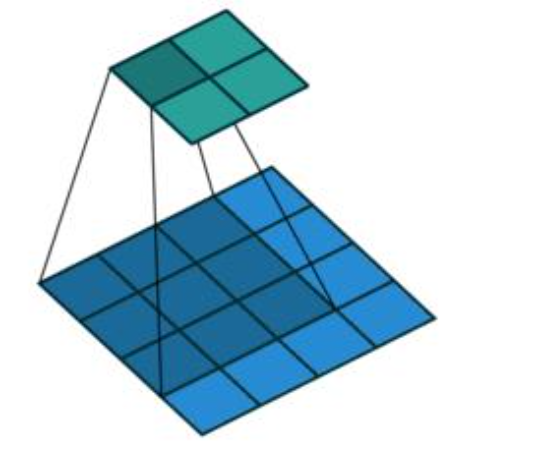
而对于转置卷积,相当于把普通卷积反过来,输入蓝色2x2矩阵(周围填0变成6x6),卷积核大小还是3x3。当设置反卷积参数pad=0,stride=1时输出绿色4x4矩阵,如图:
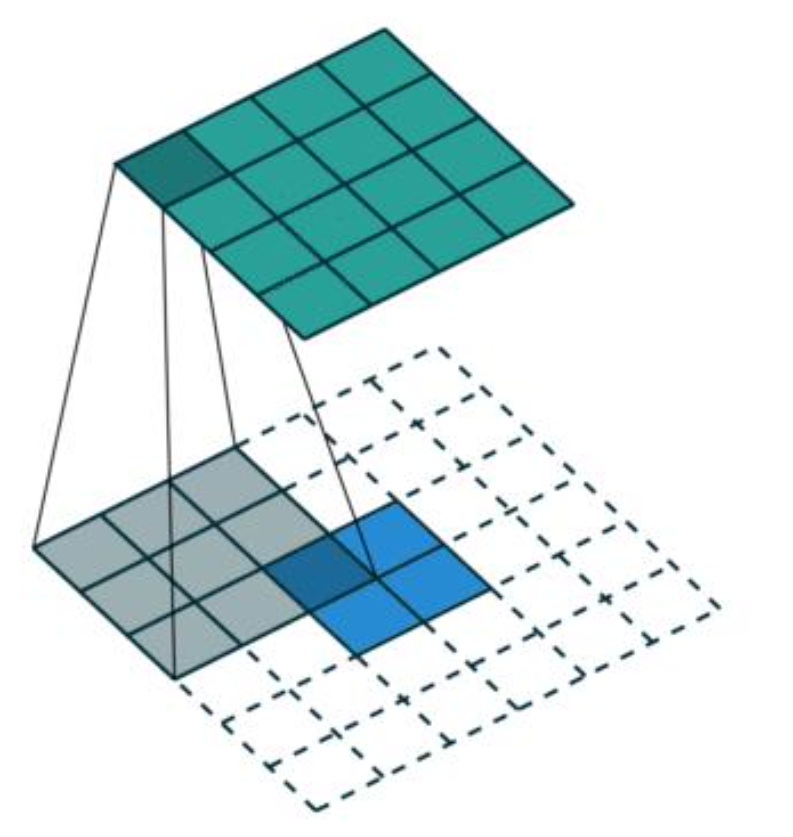
传统的网络是subsampling的,对应的输出尺寸会降低;upsampling的意义在于将小尺寸的高维度feature map恢复回去,以便做pixelwise prediction,获得每个点的分类信息。
可以看到经过上采样后恢复了较大的pixelwise feature map。这其实相当于一个Encode-Decode的过程。
总结
CNN图像语义分割也就基本上是这个套路:
- 下采样+上采样:Convlution + Deconvlution/Resize;
- 多尺度特征融合:特征逐点相加/特征channel维度拼接;
- 获得像素级别的segement map:对每一个像素点进行判断类别。
即使是更复杂的DeepLab v3+依然也是这个基本套路: