
Transformer - MoE
概念
混合专家模型,Mixture of Experts (MoE)
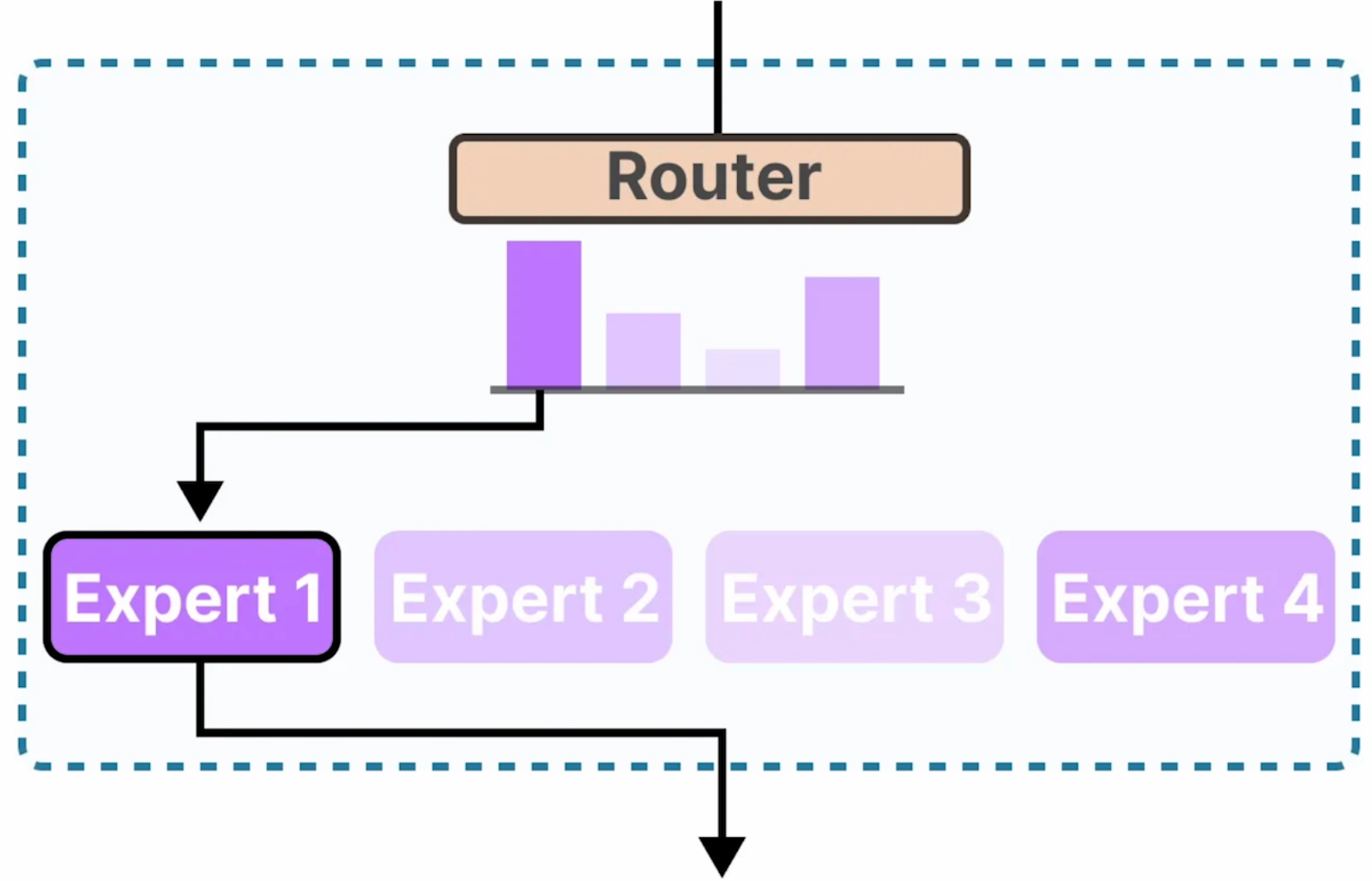
- 路由器充当分类器
- 使用多个子模型来提高 LLM 的质量
- 推荐博客: A Visual Guide to Mixture of Experts (MoE)
Intuition #1
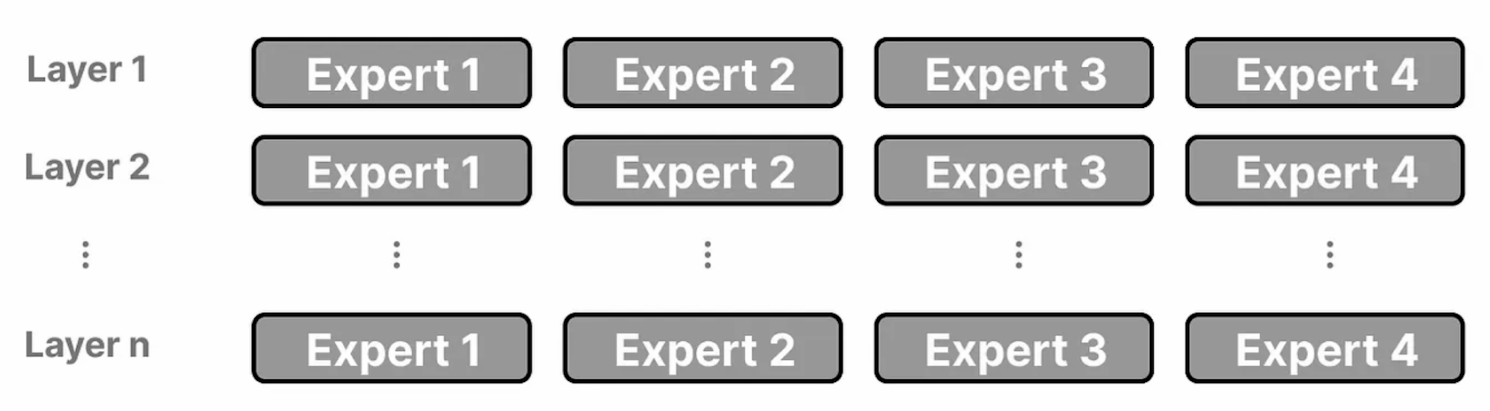
- 不应将每个专家视为一个整体组件
- 相反,每一层都有一组专门处理特定token的专家
Intuition #2
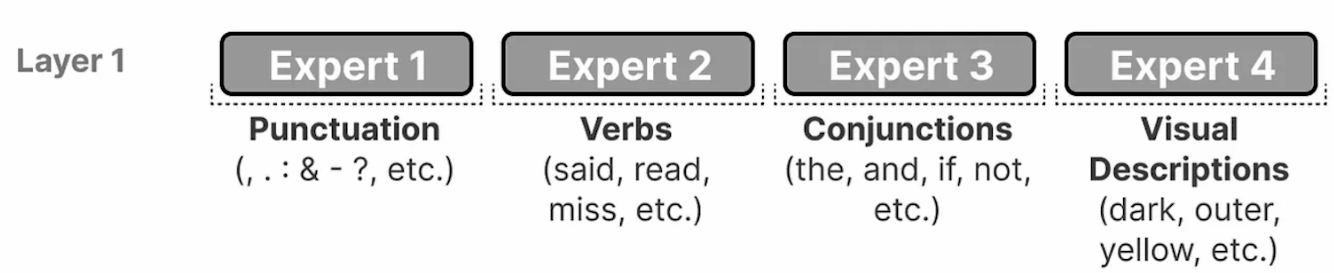
- “专家”并非专门研究特定领域的,例如“心理学”或“生物学”等
- 相反,这些“专家”可能倾向于关注特定类型的标记,并专注于如何最好地处理它们。
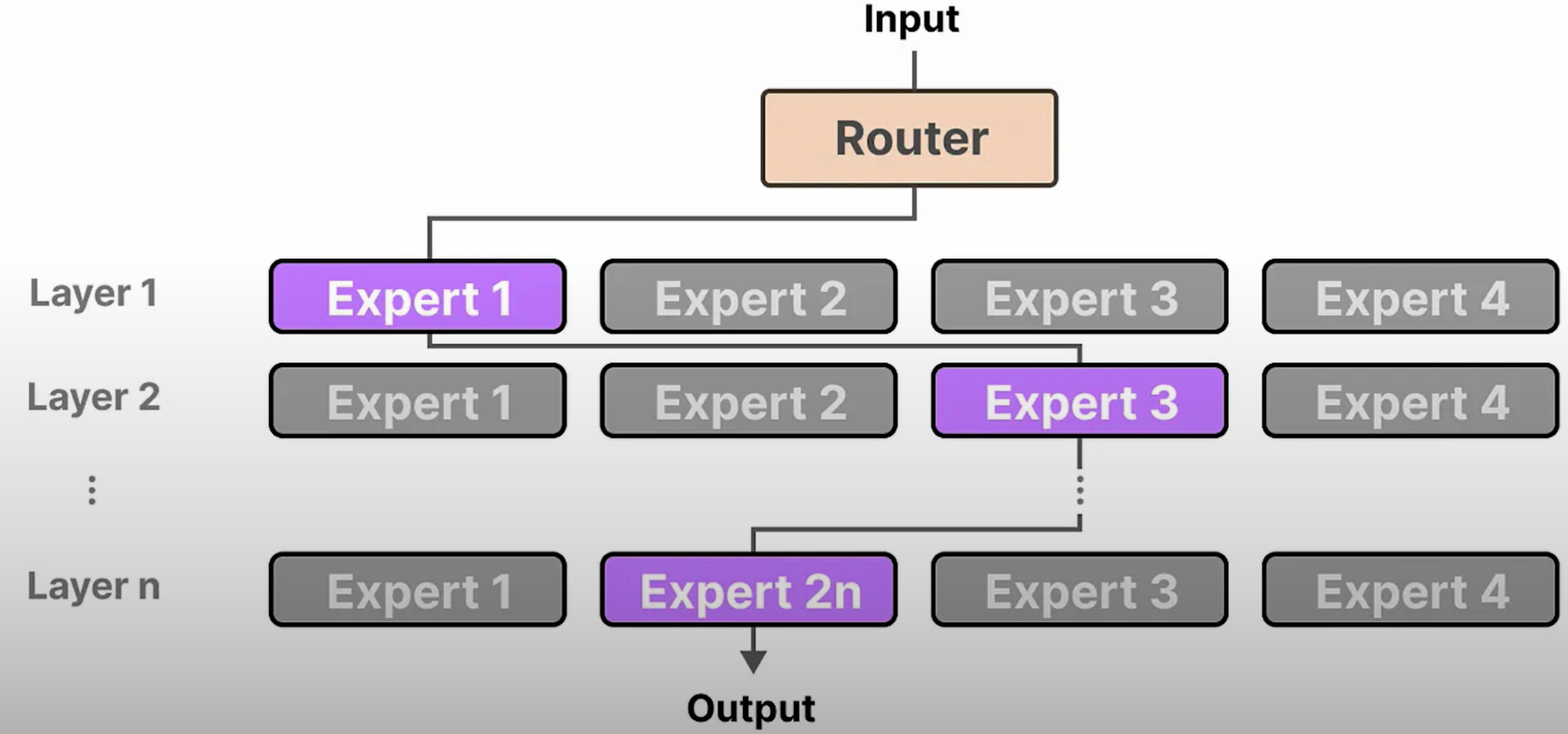
每层的路由器选择最佳专家来处理输入向量
MoE 组件取代单个 FFNN
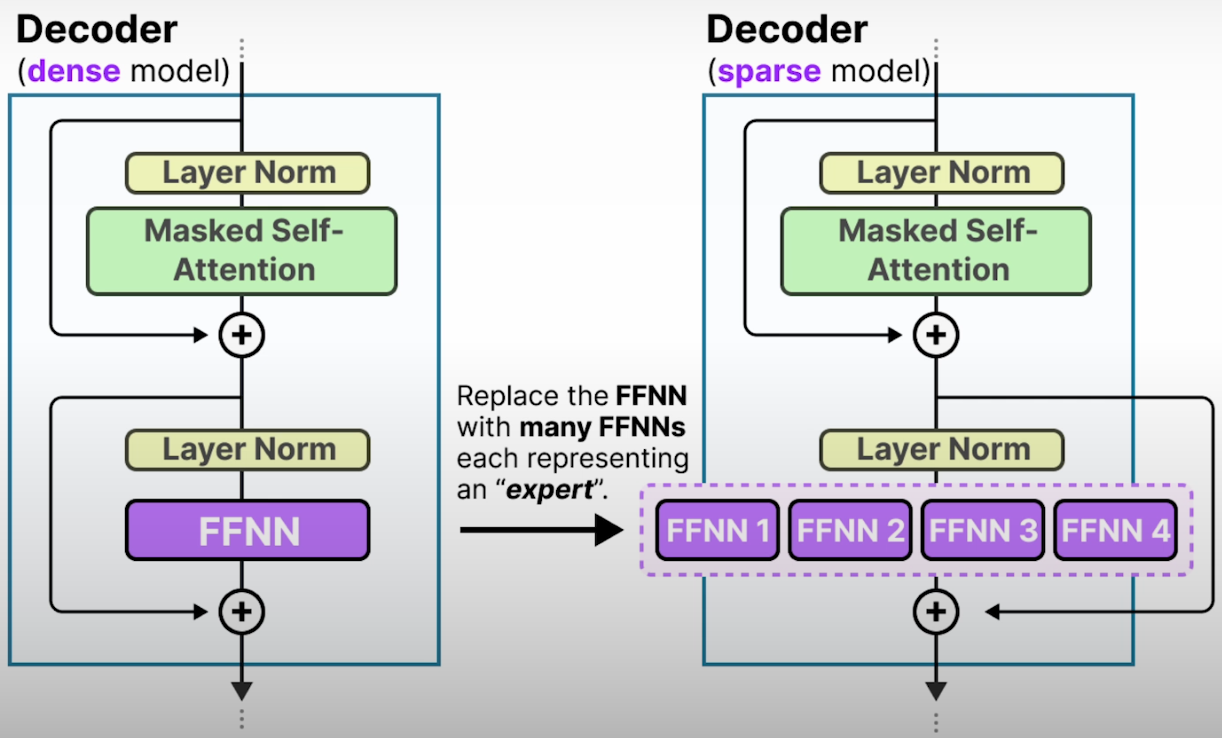
A Dense Neural Network
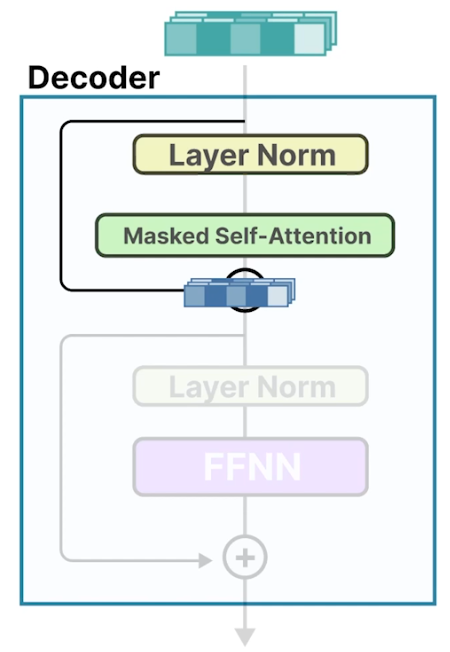
- 注意力层以这样的方式准备输入,即在向量中存储更多的上下文信息。
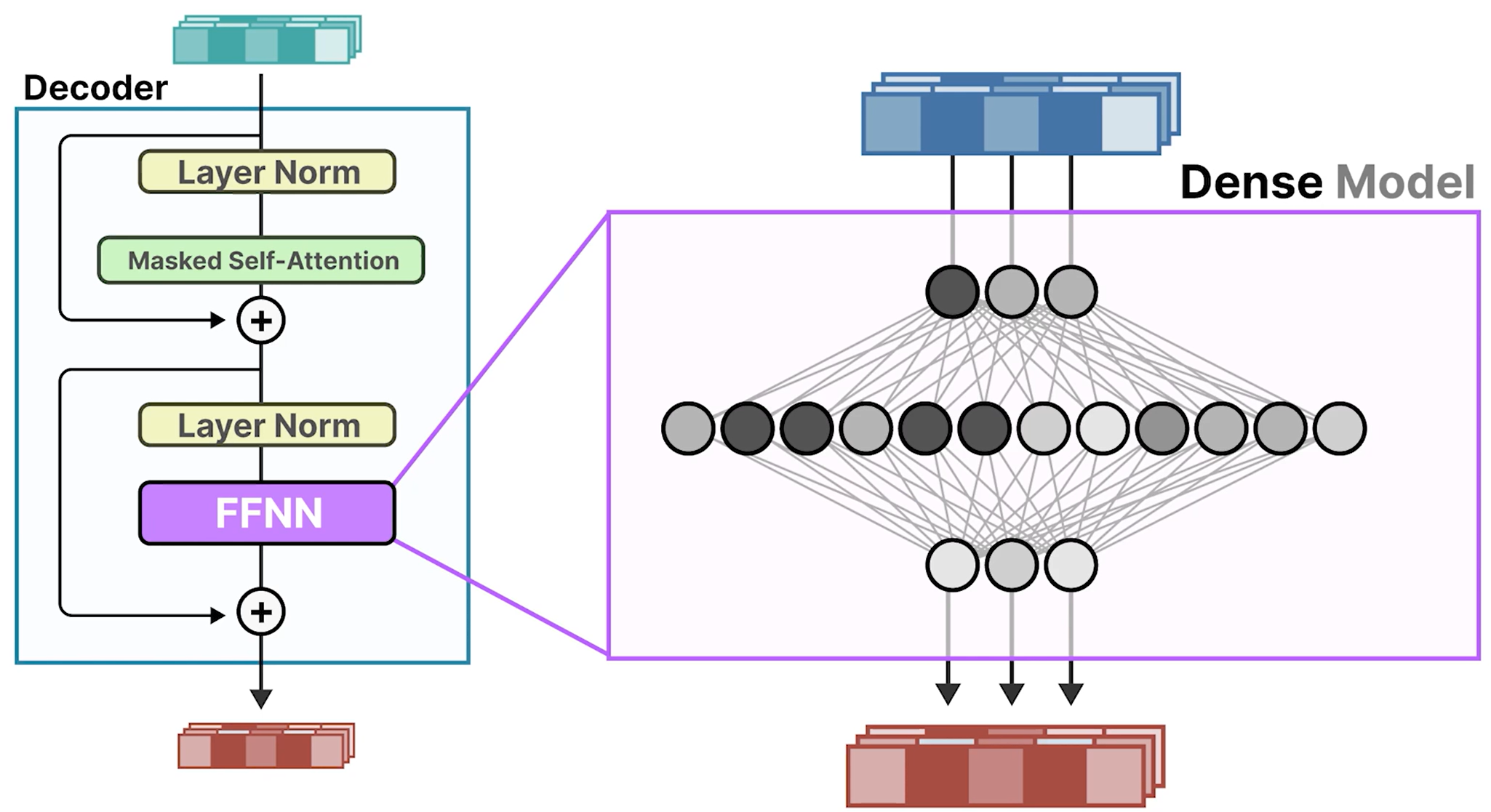
- 密集网络:所有参数均被利用
- 该网络通常是 LLM 中最大的组成部分之一。
What are Experts?
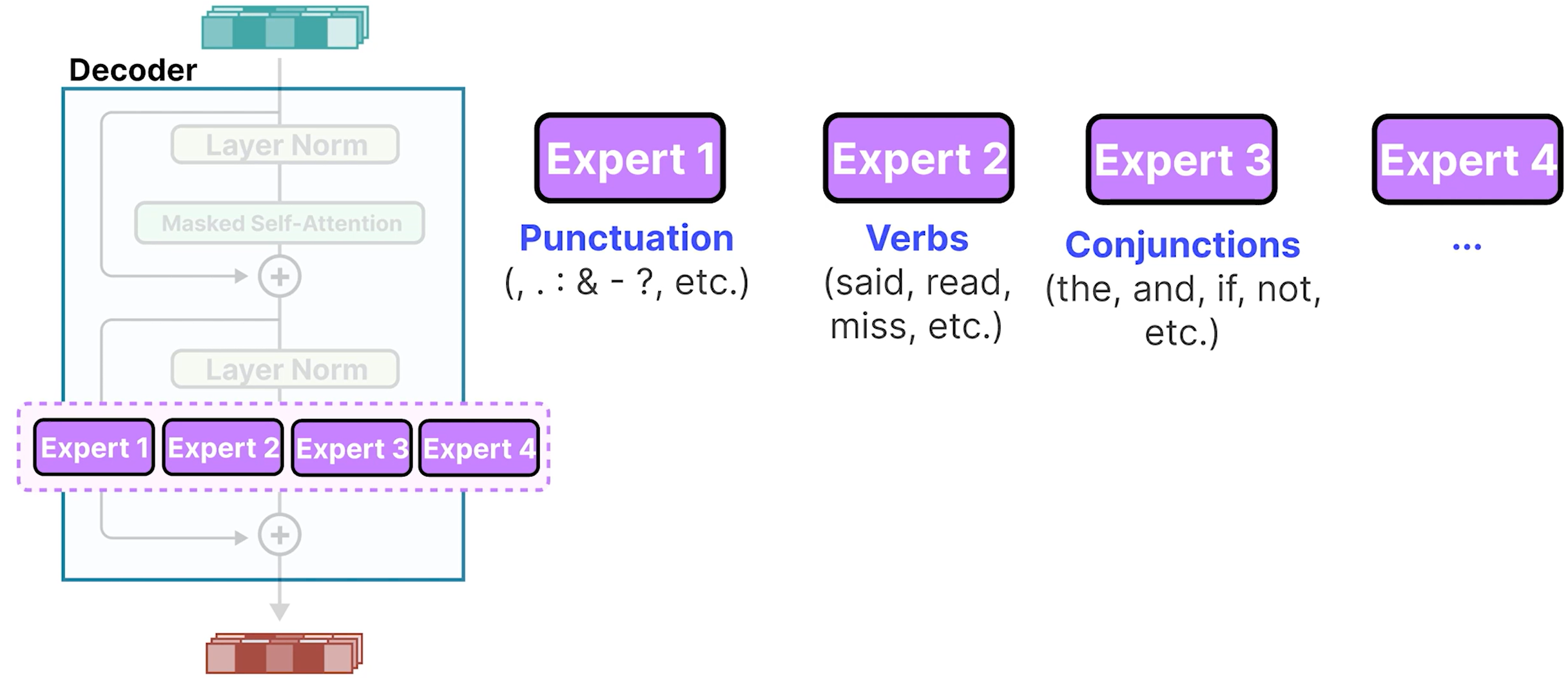
- Expert 并不专攻心理学或生物学等特定领域。
- 它最多在 token 级别上学习句法信息。
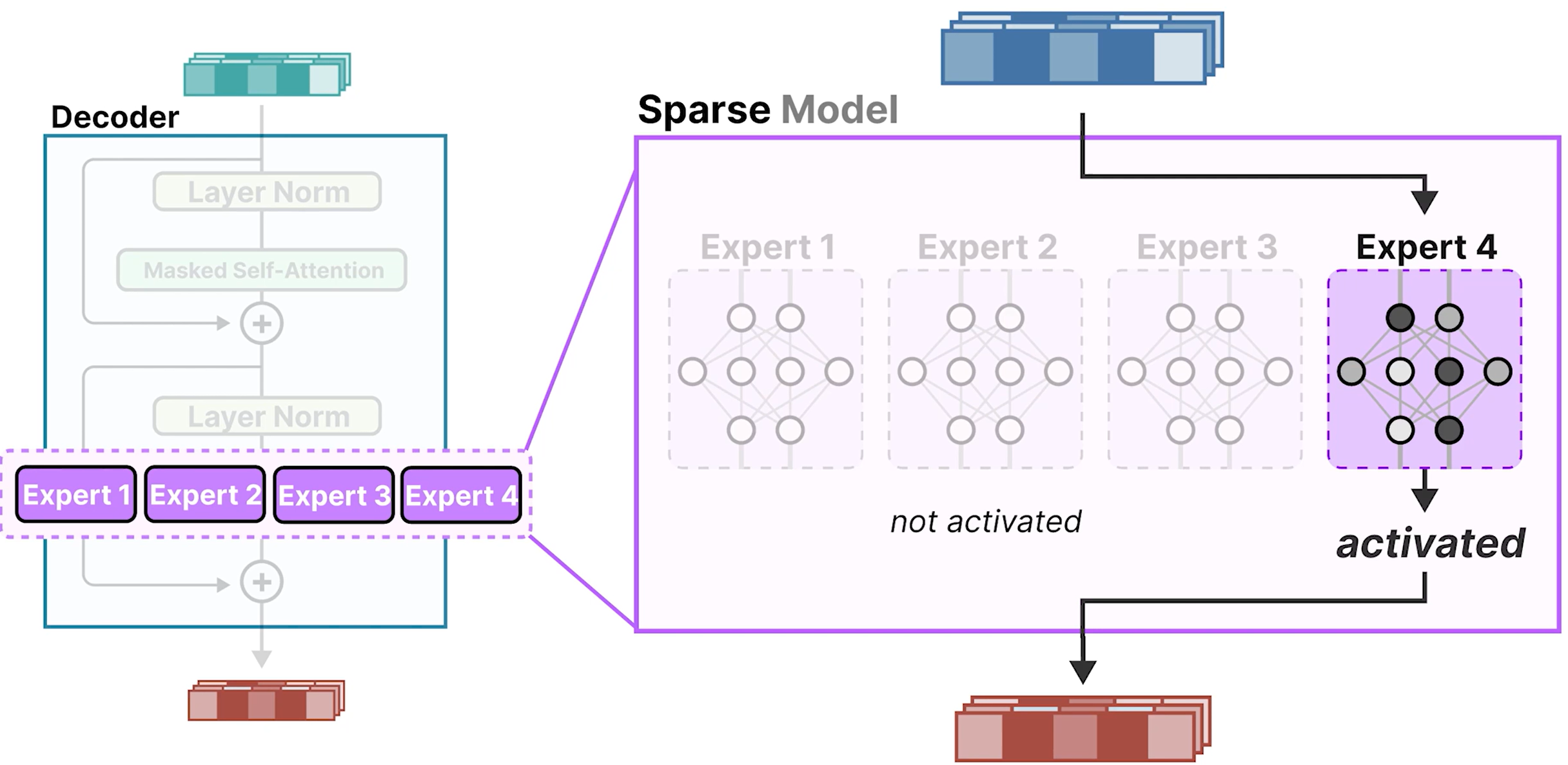
- Sparse model,稀疏模型
- 由于在给定时间内只有一部分专家被激活。
- 通常称为专家混合 (MoE) 层。
Routing the input
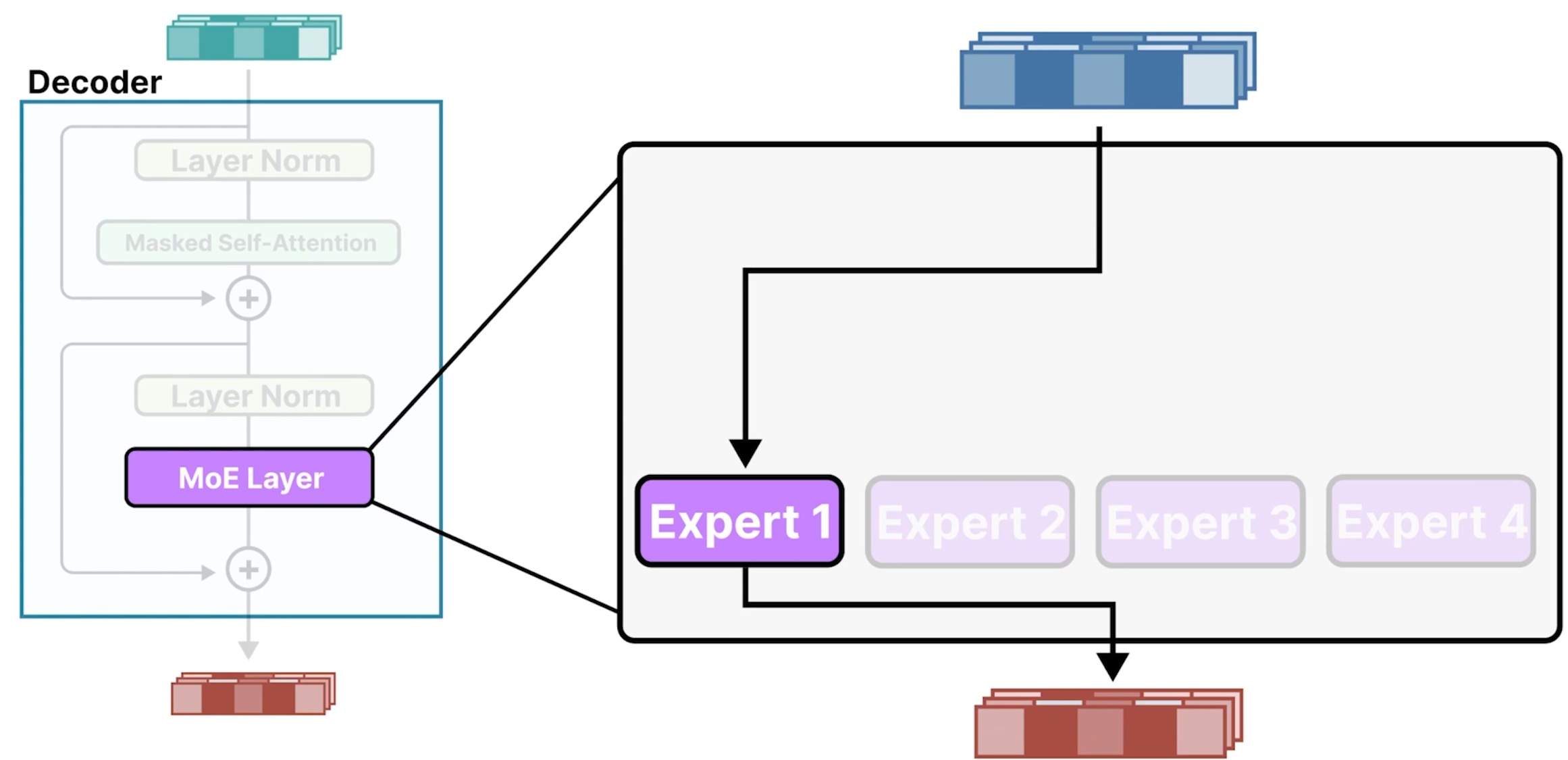
- 路由器获取输入数据并针对特定输入选择最适合的专家。
- 路由器本身是一个前馈神经网络,但与专家相比相当小。
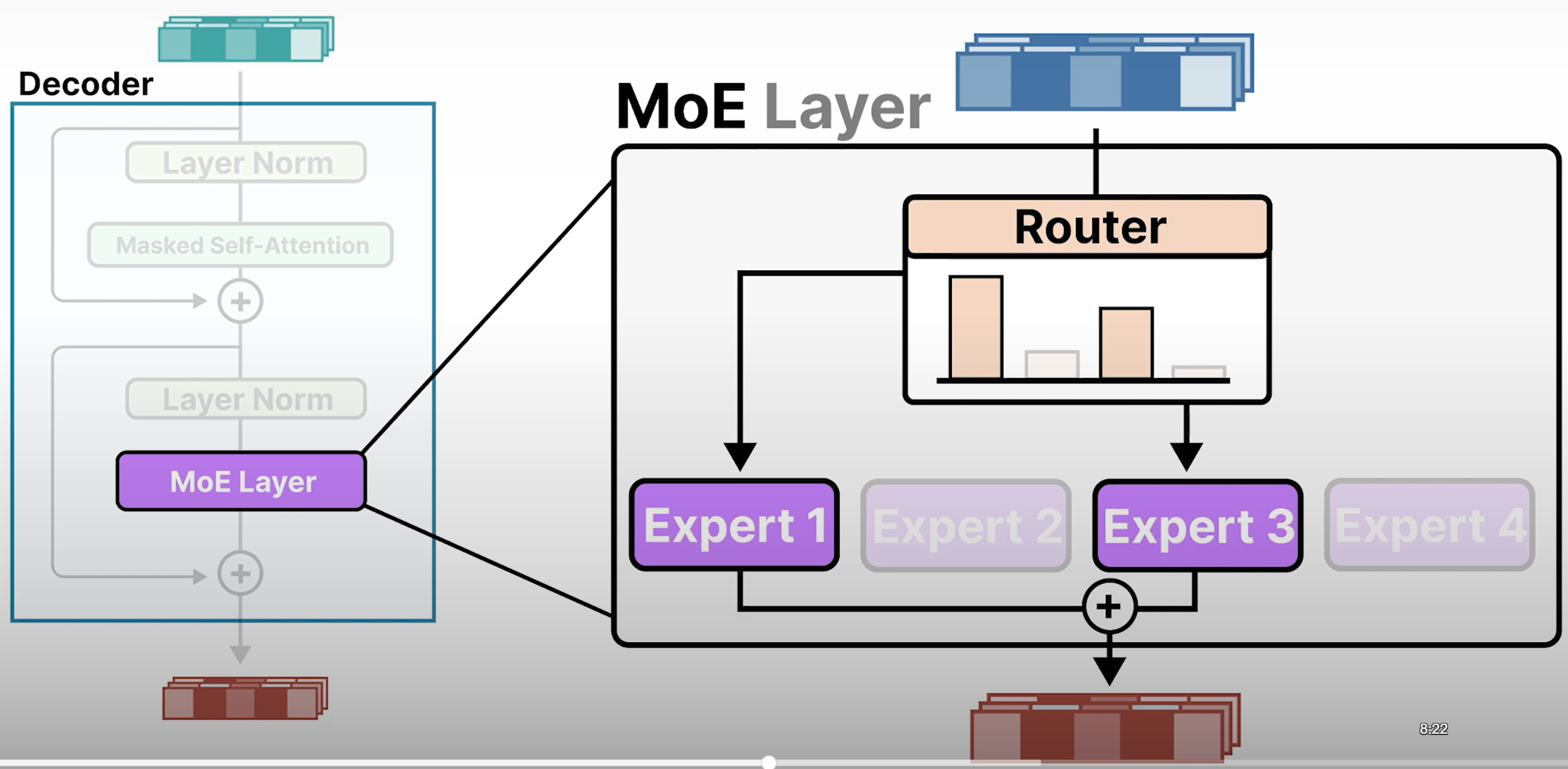
- 路由器可以选择单个或多个专家。
- 如果有多个专家,最终输出是加权和,权重是概率分数。
Computational Requirements
MoE 中使用的参数大致可分为五个部分:
- 输入嵌入
- 掩蔽自注意力
- 路由器
- 专家
- 输出嵌入
Sparse Parameters
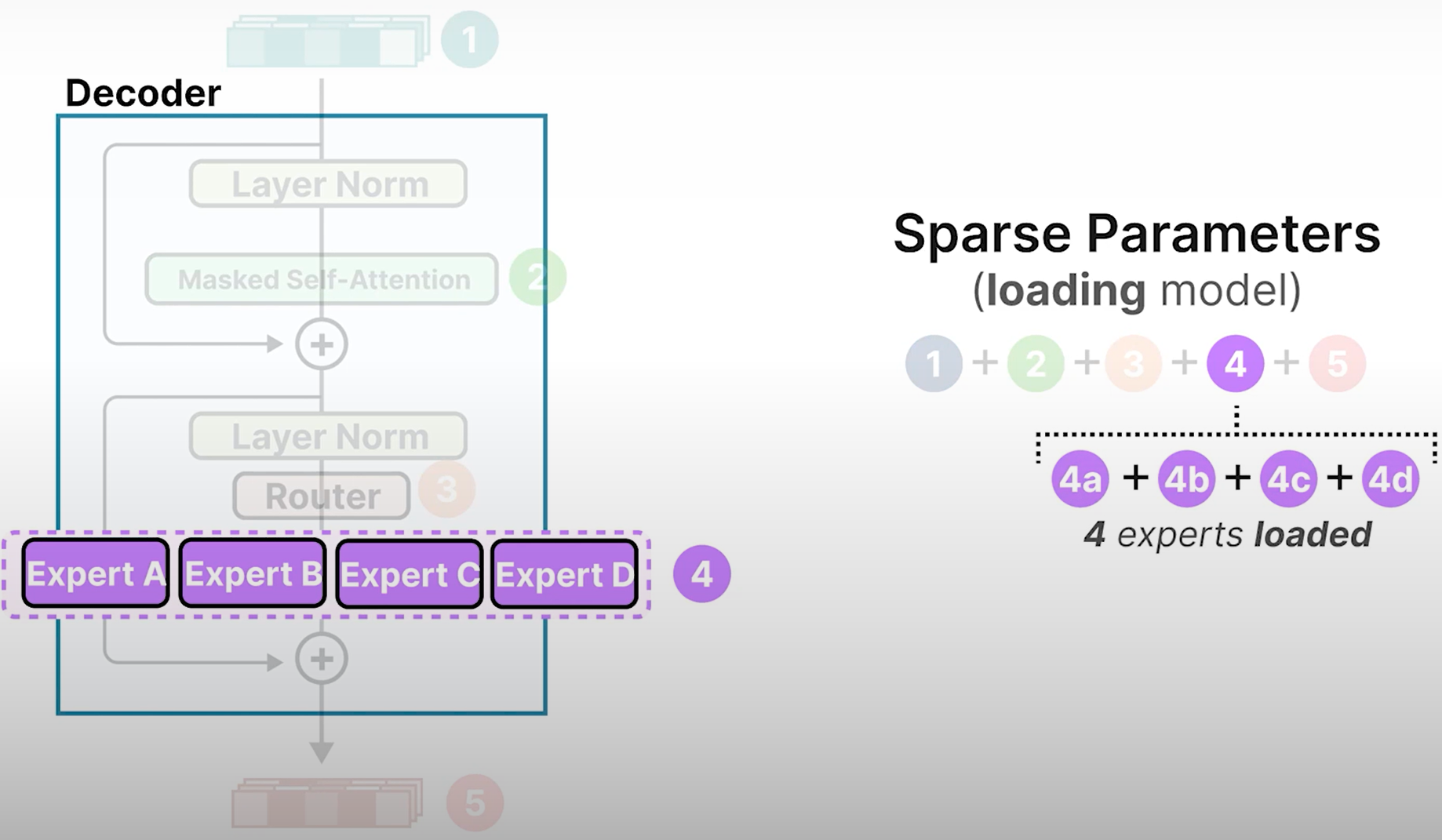
- Active Parameters
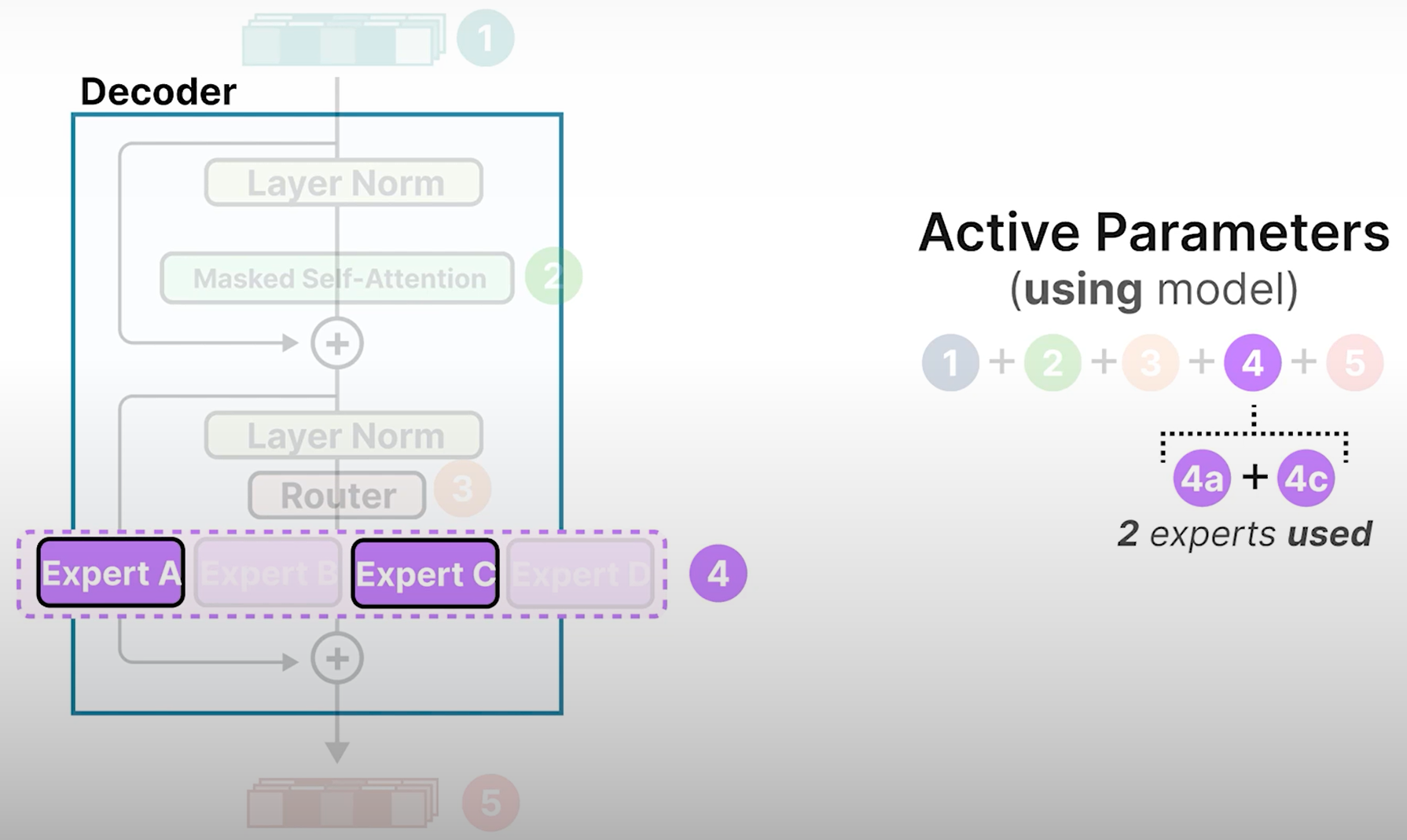
虽然所有专家都需要加载到内存中,但只有一部分用于推理。
Computing parameters in Mixtral 8x7B

- Sparse vs Active parameters
优缺点
- VRAM 视频随机存取存储器
- 加载高
- 推理低
- 过度拟合风险
- 单个专家过度拟合的风险
- 需要仔细平衡模型
- 性能
- 往往高于传统模型,因为专家有助于消除计算中的冗余
- 架构
- Complex: 需要仔细训练
- Flexible:
- 选择和使用的专家灵活
- 由于 MoE 层仅影响前馈层而不影响注意层,因此它可以被状态空间模型使用,例如 Mamba 和 Zamba