
Transformer - 概述
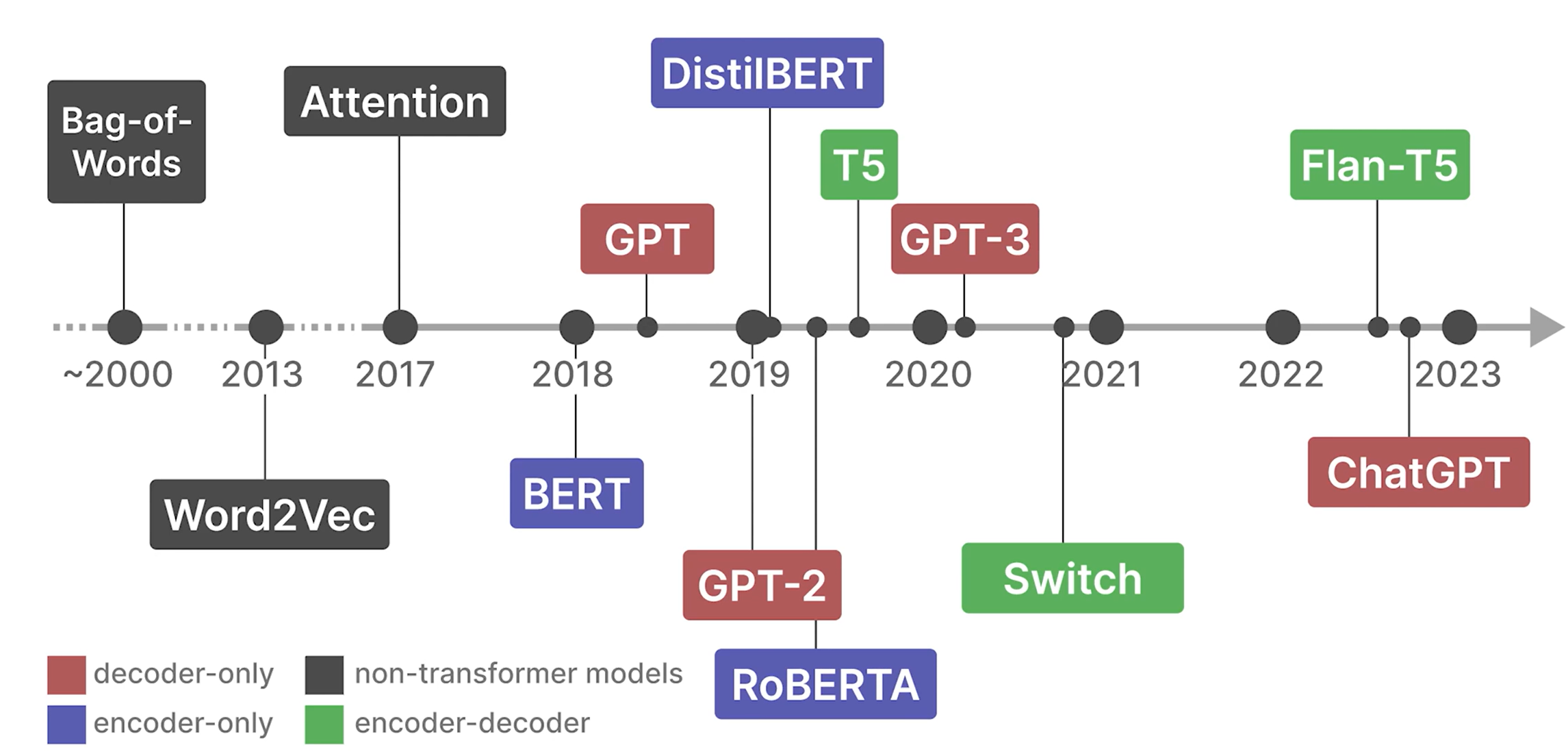
理解语言模型的发展
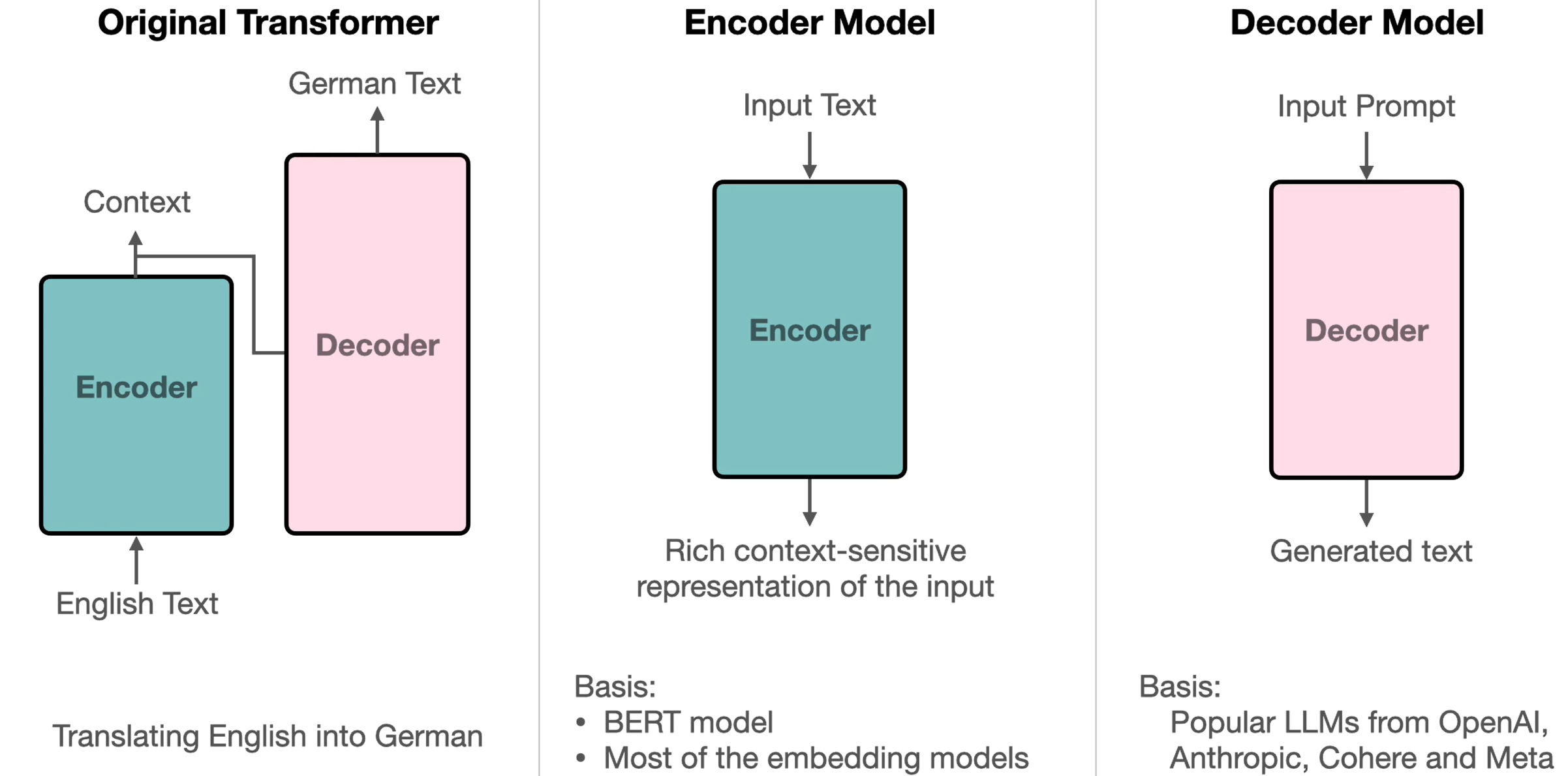
模型架构
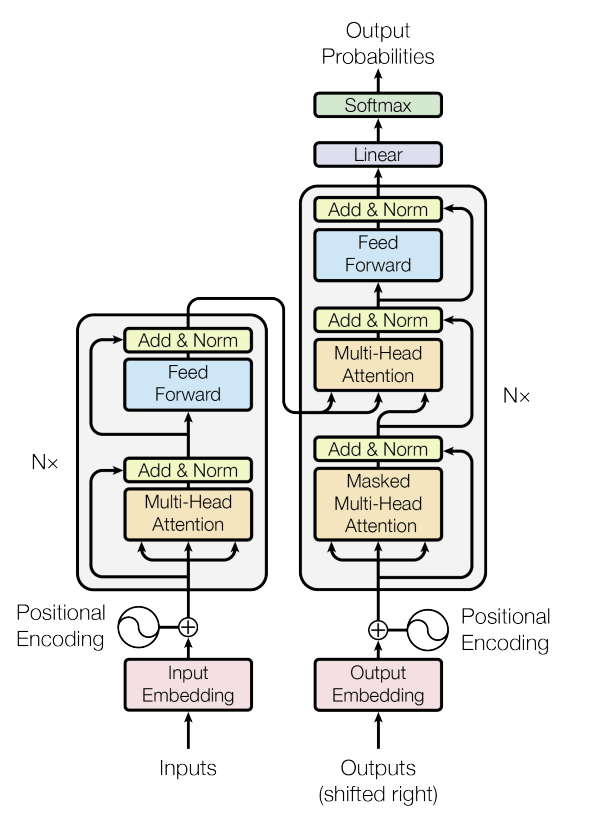
理解语言模型
语言模型
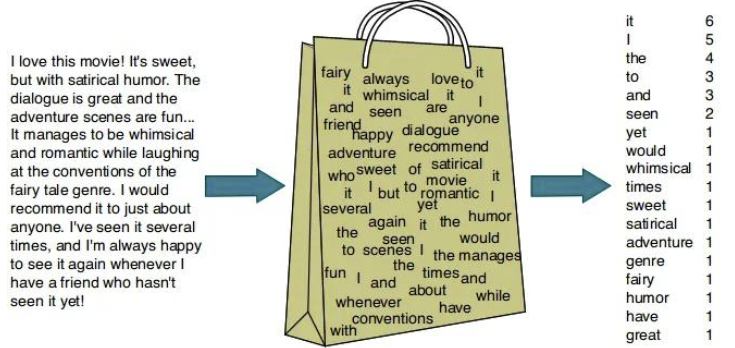
- Bag of Words, 词袋模型
- 将单词表示为大型稀疏向量或数字数组
- 这些数字简单地记录单词的存在,并不考虑单词在语义场景中的本质
- 通过统计词语的出现频率来表示文档,并忽略了词序、句法结构和语义关系。
Word2Vec
- 单词表示在几个相邻单词的上下文中捕获单词的含义
- 如果两个单词倾向于有相同的邻居,那么它们的嵌入将彼此更接近
- 单词表示在几个相邻单词的上下文中捕获单词的含义
Transformers
- 密集向量在句子或段落的上下文中捕获单词的含义
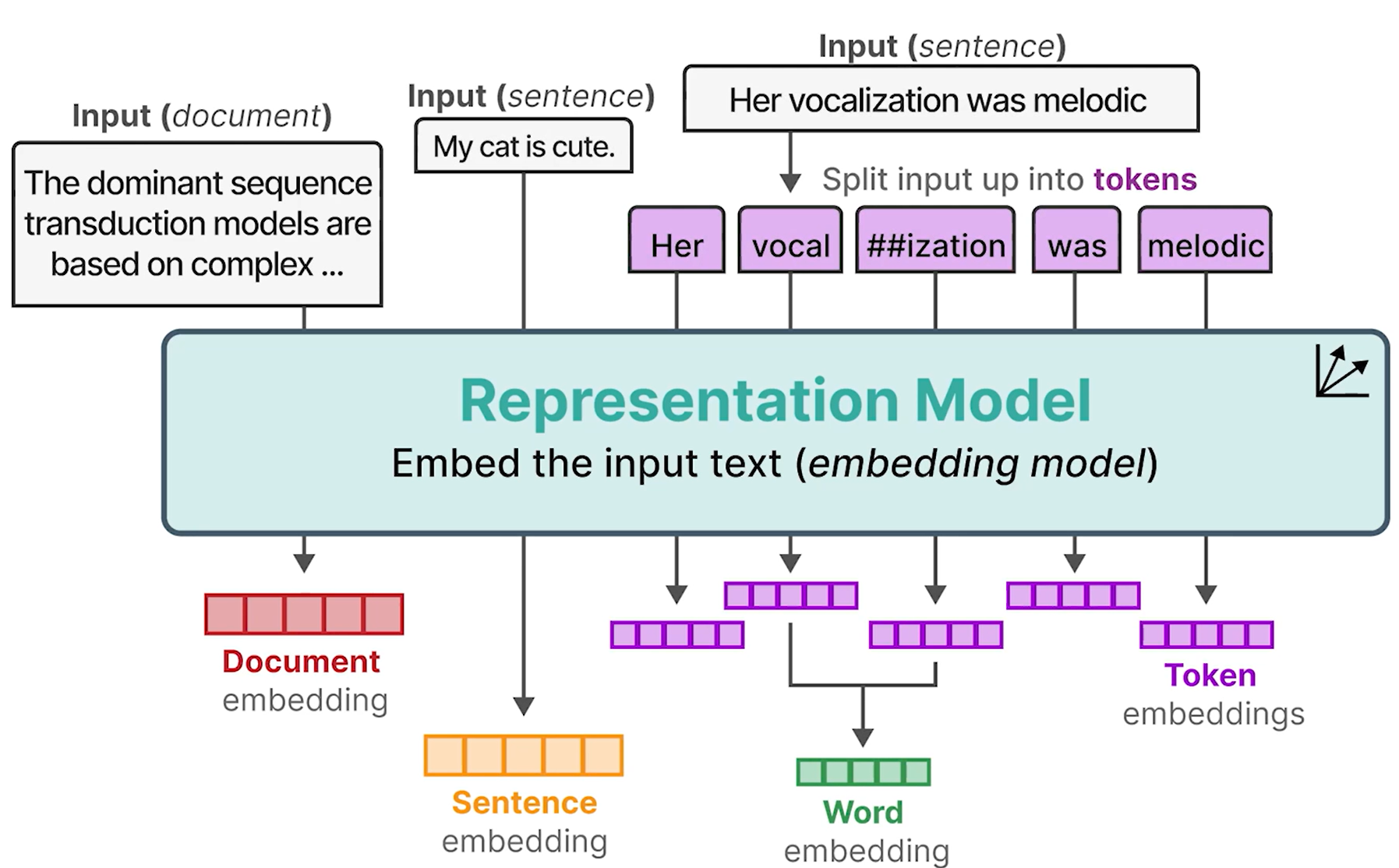
嵌入
"Embedding"指的是将离散的变量(如单词、字符或其他分类数据)映射到连续向量空间的过程。这种表示方法允许模型捕捉到输入数据之间的语义关系。以下是几种常见的嵌入类型:
- Word Embeddings(词嵌入)
- 根据标记器的词汇表将单词拆分为标记。
- 通过平均拆分标记的嵌入来创建词嵌入。
- Character Embeddings(字符嵌入)
- Subword Embeddings(子词嵌入)
- Contextual Embeddings(上下文嵌入)
- Position Embeddings(位置嵌入)
- Sentence/Document Embeddings(句子/文档嵌入)
用注意力机制对上下文进行编码和解码
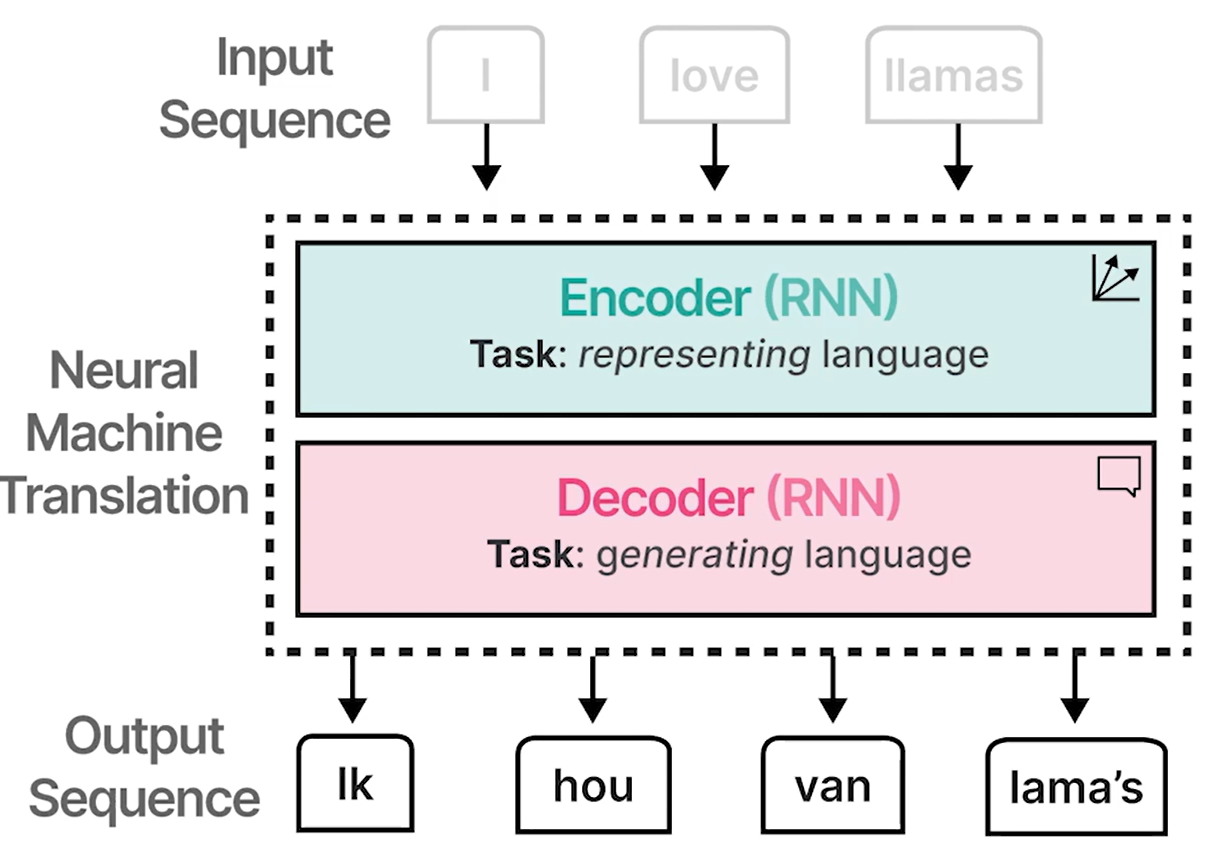
循环神经网络 (RNN)
- 用于对整个序列进行建模
- 一种动态考虑上下文的方法
示例:将英文句子翻译成荷兰语句子
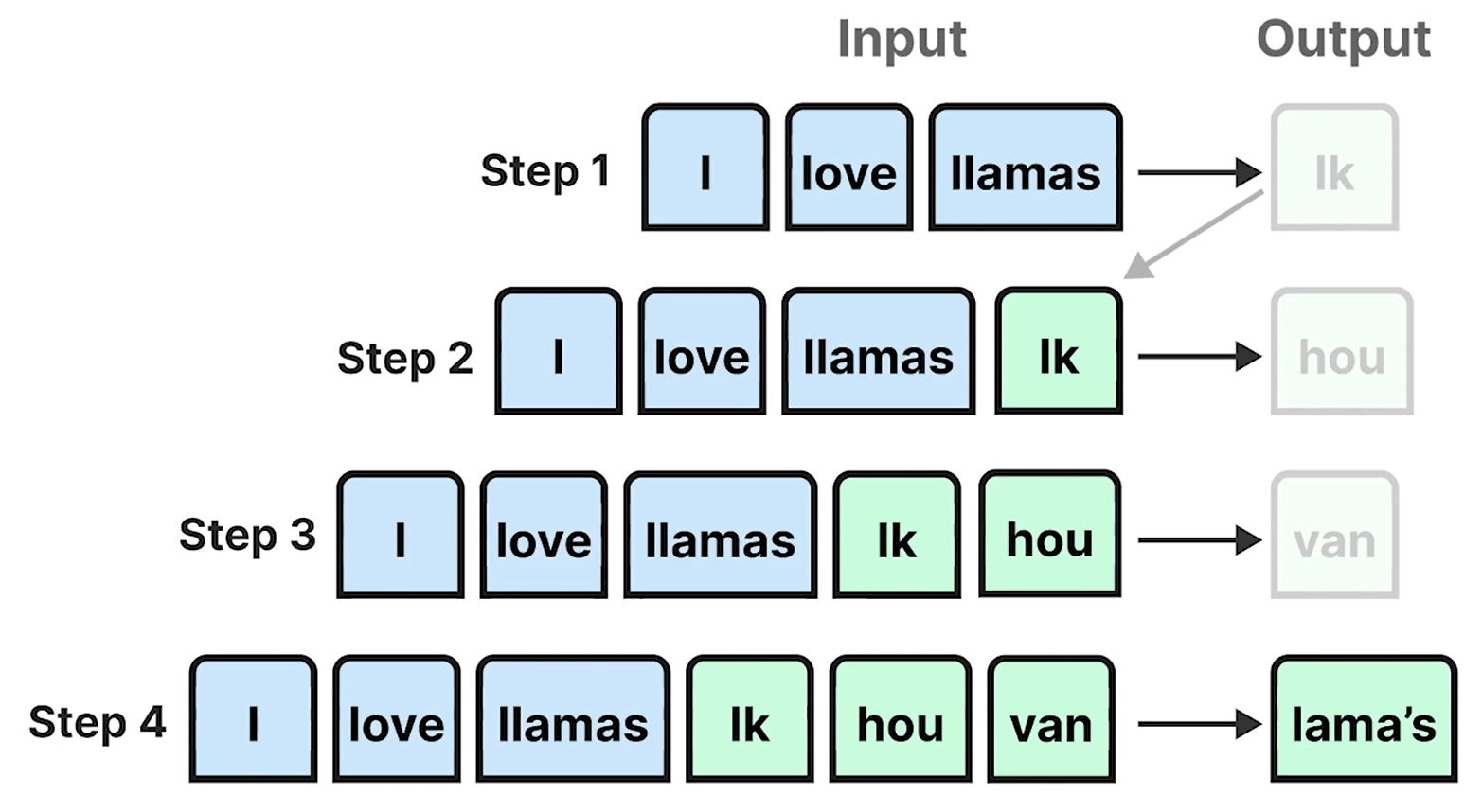
Auto-Regressive
自回归(Autoregression, AR)是一种时间序列分析方法,用于预测未来值基于该序列过去的值。
Generates one token at a time
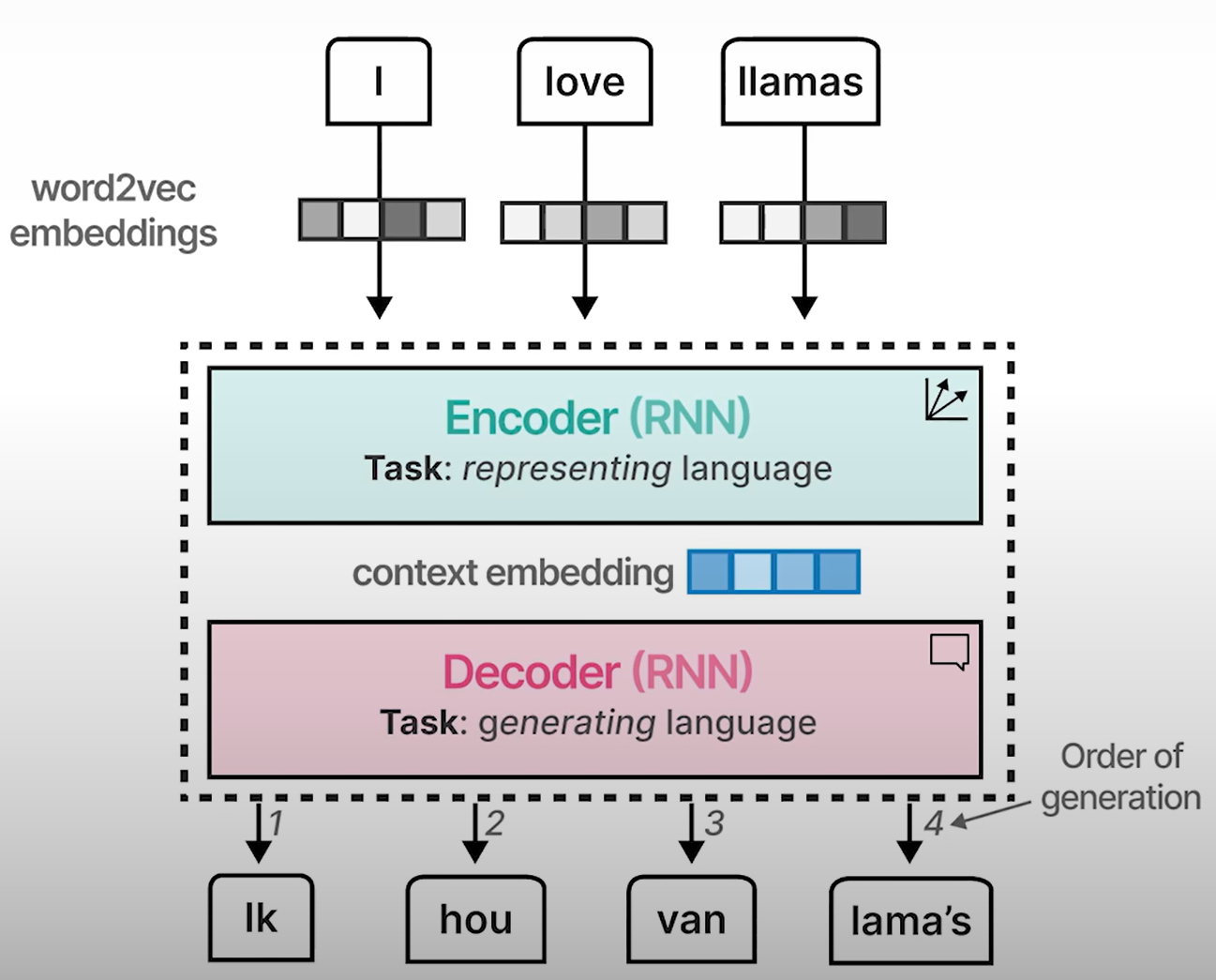
编码和解码上下文
缺点
- 上下文嵌入是针对整个文本序列的单一嵌入。
- 它可能不足以捕捉长序列的上下文。
Attention,注意力
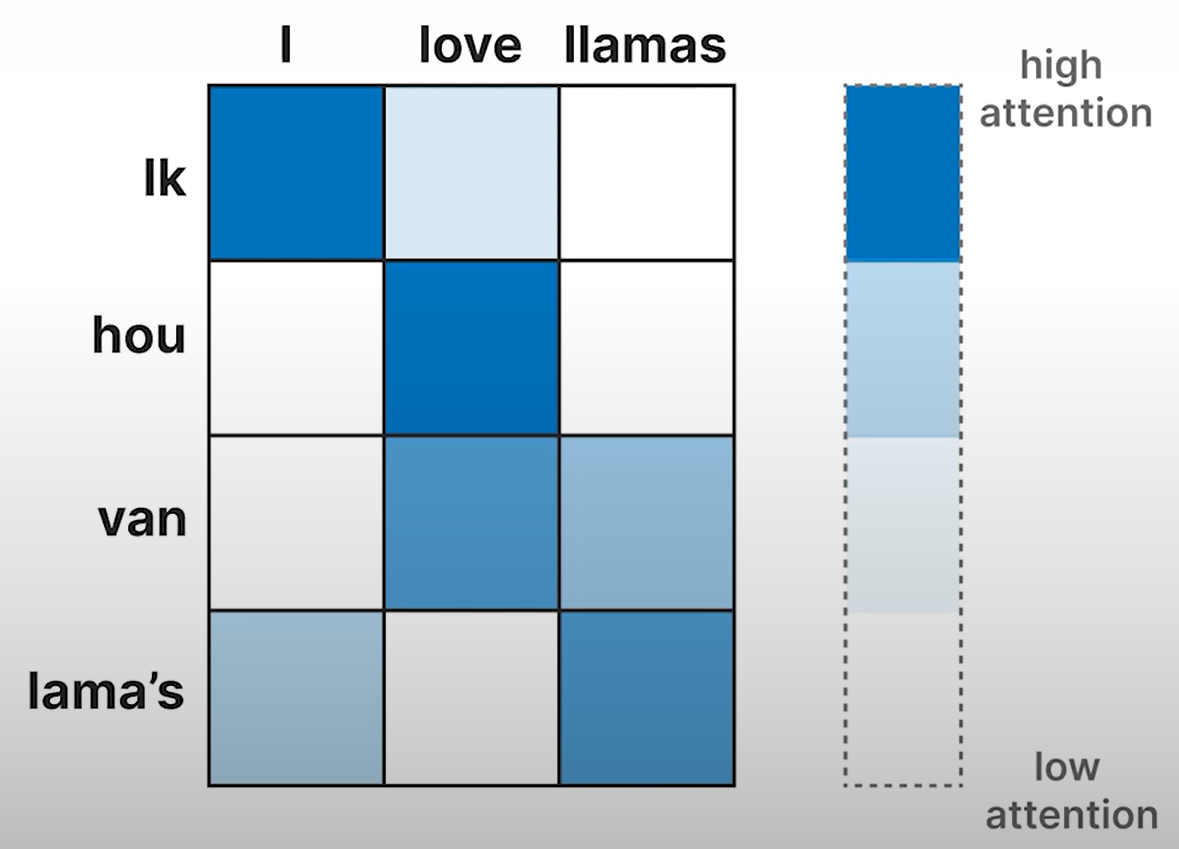
- 注意力机制允许模型将注意力集中在输入中彼此相关的部分
- “关注”彼此并放大其信号
自回归
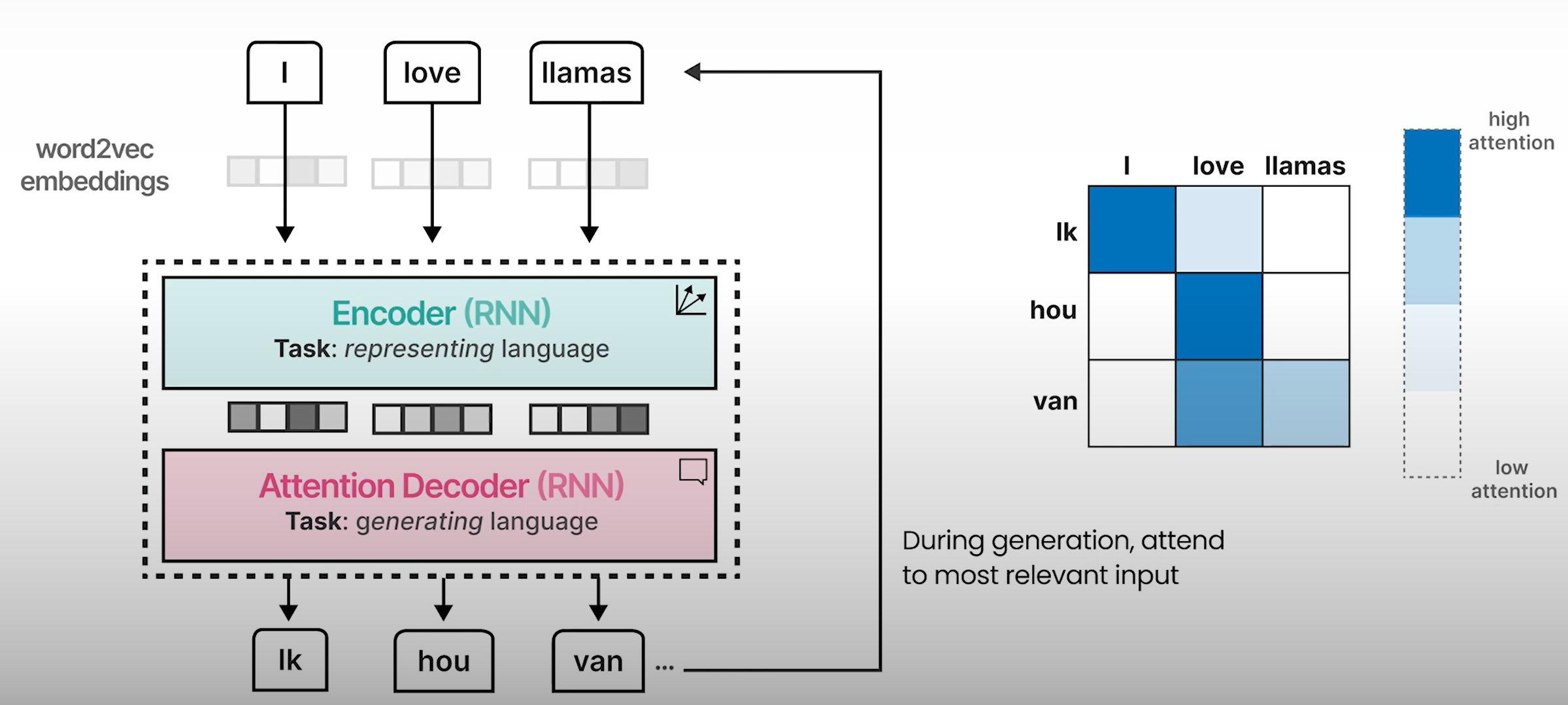
由于注意力机制的存在,输出往往会好得多,因为我们现在使用每个标记的嵌入来查看整个序列,而不是更小、更有限的上下文嵌入。
这种架构的顺序性阻碍了模型训练期间的并行化。