
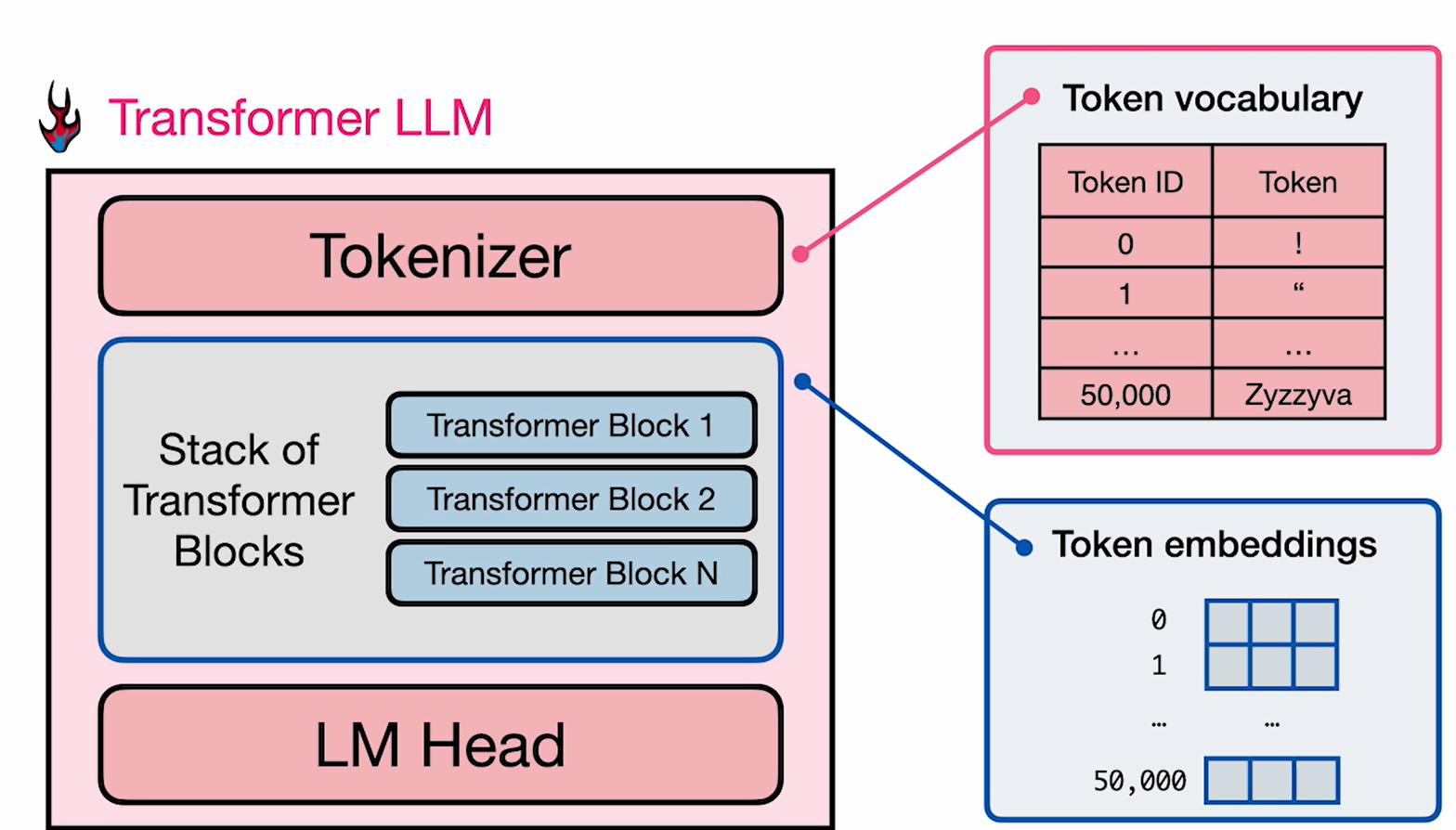
Transformer - 架构
组件
三个主要组件:
- Tokenizer
- Transformer块堆栈
- 语言模型头
Tokenizer 包含词汇表,模型包含token嵌入
语言模型头为下一个输出的最佳(最可能)token打分

存在多种解码策略来选择最佳输出token
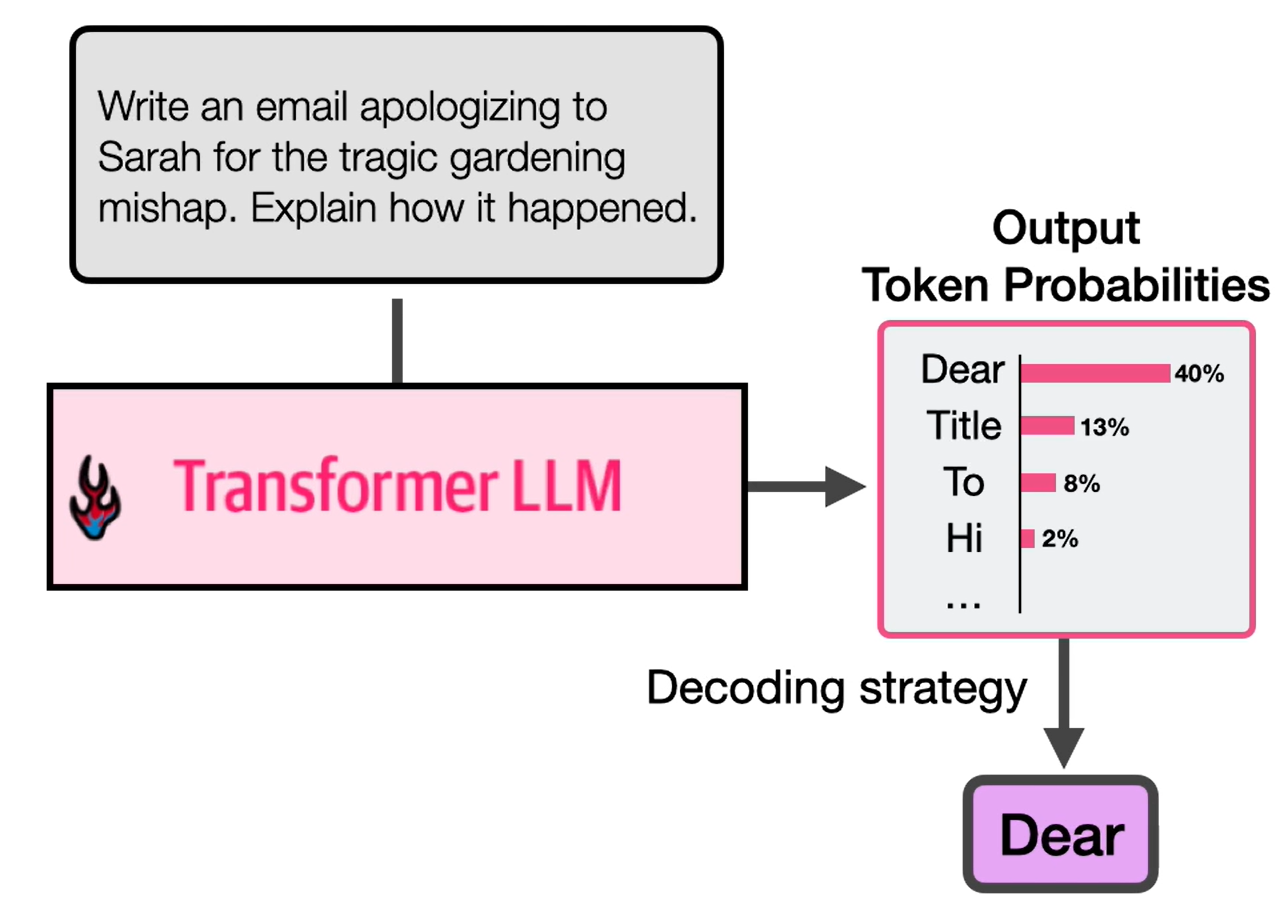
- 选择最高的
temperature= 0- 贪婪解码
- 选择
top_p- 这会根据概率考虑多个token,即不限于最高概率的token。
- 添加随机性
temperature> 0
并行多个轨道
- 轨道数量 = 上下文长度
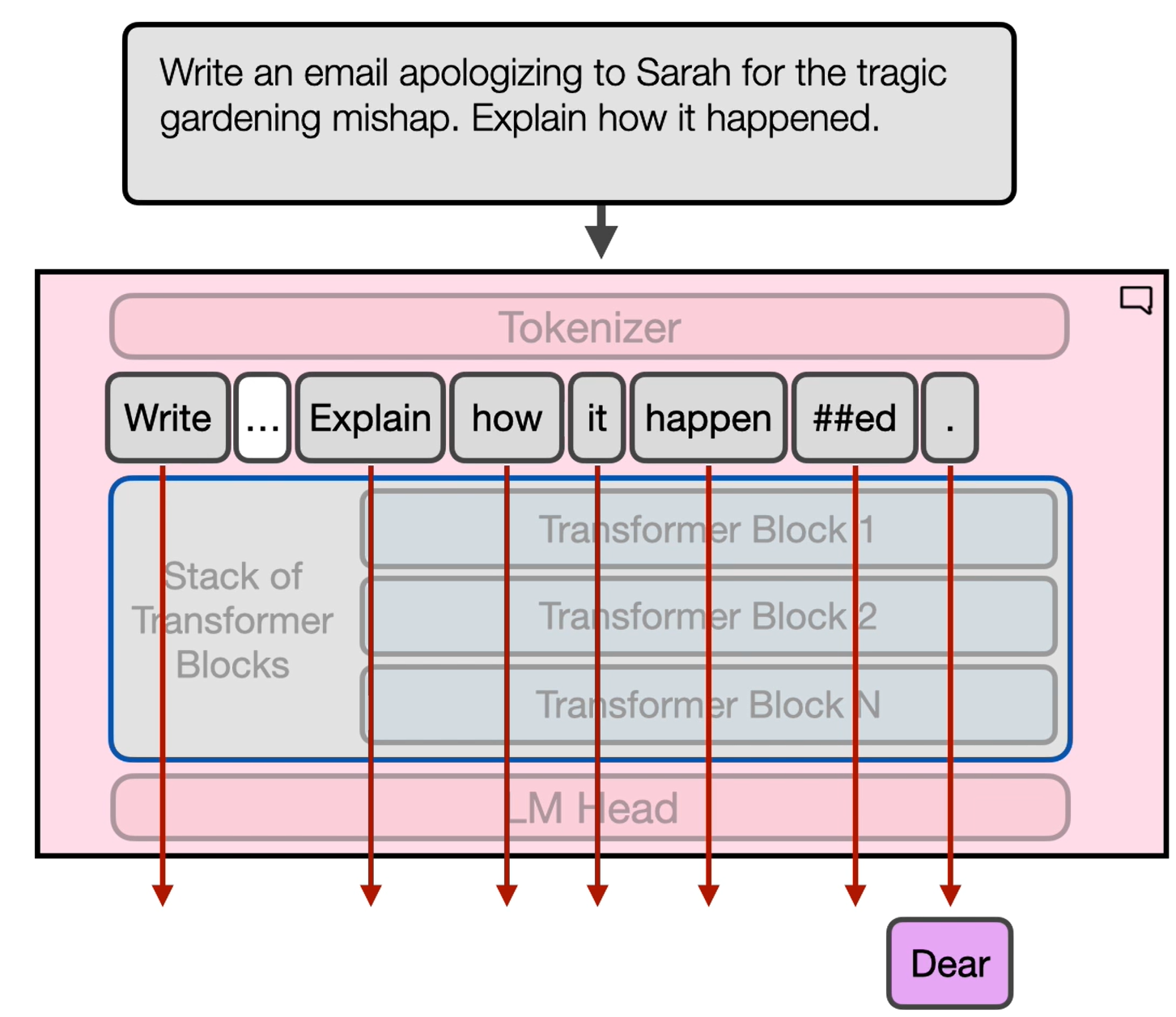
- Transformer 中生成的输出 token 是最终 token 的输出。
- TTFT:第一个 token 的时间
- 模型处理上述计算所花费的时间
KV 缓存
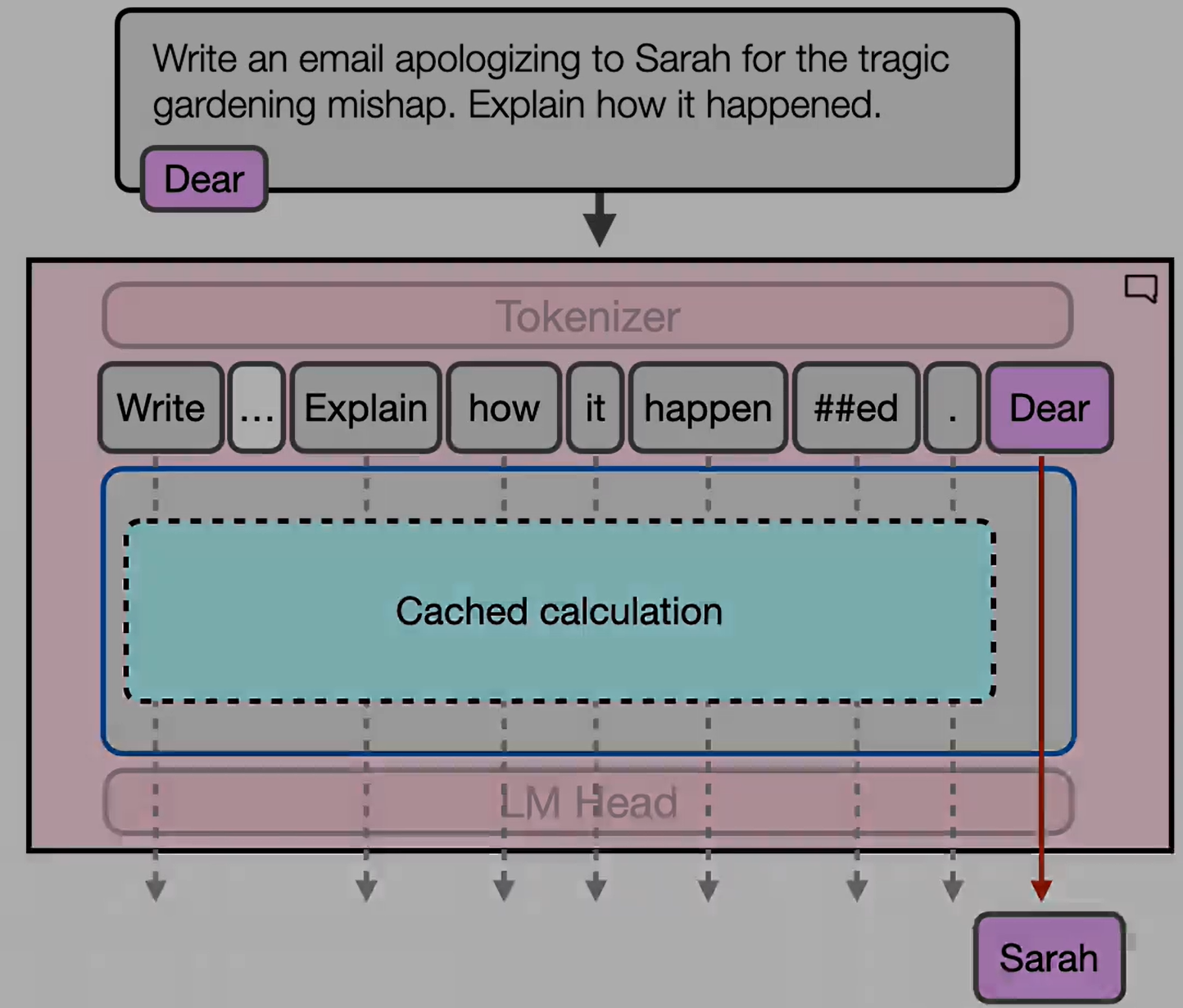
- 第一个 token 生成后,输入还包含生成的 token。