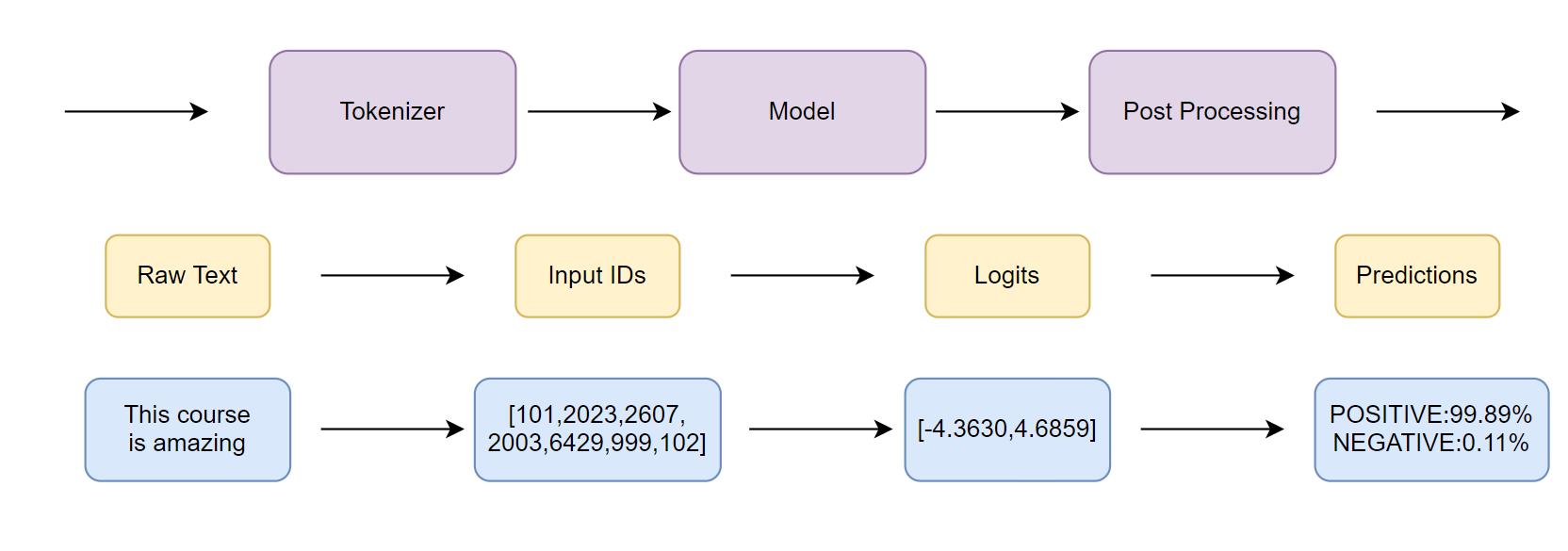
HuggingFace - Pipeline
- 将数据预处理、模型调用、结果后处理三部分组装成的流水线
- 使我们能够直接输入文本便获得最终的答案
创建与使用
# Pipeline创建与使用
# 根据任务类型直接创建Pipeline
pipe = pipeline("text-classification")
# 指定任务类型,再指定模型,创建基于指定模型的Pipeline
pipe = pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")
# 预先加载模型,再创建Pipeline
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
# 使用GPU进行推理加速
pipe = pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese", device=0)
详细解释:
pipe = pipeline("text-classification")
- 工作原理: 这是最简单的创建方式。Hugging Face 库会为你指定的任务(如
text-classification)自动选择一个默认的模型。对于文本分类,这通常是一个在通用数据集(如 SST-2)上训练过的英语模型。 - 优点:
- 极其方便:一行代码即可开始使用,无需关心模型细节。
- 缺点:
- 缺乏控制: 你无法选择模型,可能不适用于你的特定领域(如中文、法律文本、医疗文本)。
- 隐性下载: 第一次运行时会自动下载默认模型,如果网络不好会很慢,且你可能不知道下载了什么。
- 总结:仅适用于快速测试和体验,不适合处理中文或严肃项目。
pipe = pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")
- 工作原理: 你明确指定了要使用的模型。Pipeline 会自动从 Hugging Face Hub 下载这个指定的模型及其对应的分词器(Tokenizer)。
- 优点:
- 针对性强的便利: 依然非常方便,但可以精确控制使用哪个模型。例如,这里指定了一个在中文点评数据上微调过的模型,非常适合做中文情感分析。
- 行业最佳实践: 这是最常见的使用方式,很好地平衡了便利性和效果。
- 缺点:
- 每次运行脚本(在新环境中)都可能需要重新下载模型。
- 总结: 最常用和推荐的方式,适用于绝大多数项目和实验,能够确保使用最合适的模型。
预先加载模型 (model = AutoModelFor..., tokenizer = AutoTokenizer...)
- 工作原理: 你将模型的加载和使用分成了两个明确的步骤。首先手动加载模型和分词器,然后将它们传递给
pipeline函数。 - 优点:
- 极致灵活与控制:
- 精细控制加载: 可以在加载模型时传入更多参数,如
from_pretrained(..., torch_dtype=torch.float16)进行半精度加载以节省显存。 - 复用组件: 加载的
model和tokenizer对象可以独立于pipeline使用,方便进行调试、自定义预处理或后处理逻辑。 - 离线使用: 可以先将模型下载到本地,然后从本地路径
./local-path-to-model加载,避免每次联网下载。
- 精细控制加载: 可以在加载模型时传入更多参数,如
- 极致灵活与控制:
- 缺点:
- 代码冗长: 需要写更多代码。
- 需要更多知识: 需要了解
AutoModel和AutoTokenizer等类。
- 总结: 适用于高级用户和需要高度定制的场景,例如模型量化、自定义处理逻辑或离线部署。
pipe = pipeline(..., device=0)
- 工作原理: 这个参数可以与前三种方法中的任何一种结合使用(如方法二)。
device=0告诉 Pipeline 将模型加载到第一个 GPU(CUDA 设备 0)上运行,从而利用 GPU 的并行计算能力大幅加速推理过程。 - 优点:
- 极速推理: 对于大模型或批量处理,GPU 带来的加速效果是数量级的提升。
- 缺点:
- 需要配备 NVIDIA GPU 和正确的 CUDA 环境。
- 如果模型本身很大,需要确保 GPU 显存足够容纳它。
- 总结: 在生产环境或需要处理大量数据时必备的优化手段。
device=-1表示使用 CPU。
Pipeline的背后实现
Step1 初始化Tokenizer
tokenizer = AutoTokenizer.from pretrained("uer/roberta-base-finetuned-dianping-chinese")Step2 初始化Model
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")Step3 数据预处理
input text =“我觉得不太行!"
inputs = tokenizer(input text, return tensors="pt")
Step4 模型预测
res = model(**inputs).logitsStep5 结果后处理
pred = torch.argmax(torch.softmax(logits, dim=-1)).item()
result = model.config.id2label.get(pred)
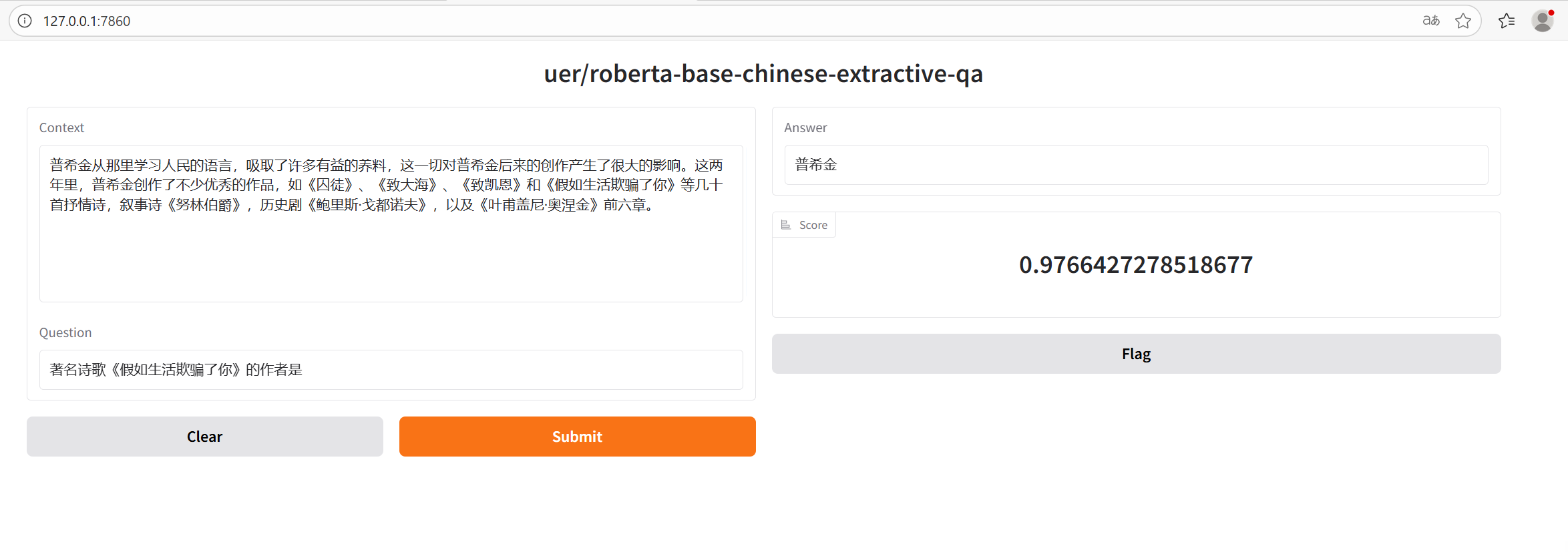
示例
执行示例question_answering.py