
HuggingFace - Model
类型
- 编码器模型:自编码模型,使用Encoder,拥有双向的注意力机制,即计算每一个词的特征时都看到完整上下文
- 解码器模型:自回归模型,使用Decoder,拥有单向的注意力机制,即计算每一个词的特征时都只能看到上文,无法看到下文
- 编码器解码器模型:序列到序列模型,使用Encoder+Decoder,Encoder部分使用双向的注意力,Decoder部分使用单向注意力
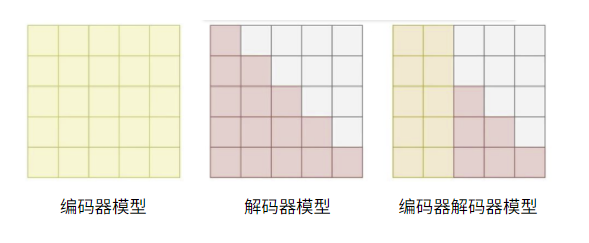
对比
| 特性 | 编码器模型 | 解码器模型 | 编码器-解码器模型 |
|---|---|---|---|
| 核心功能 | 理解与表示 | 生成与创造 | 转换与生成 |
| 工作原理 | 将输入序列压缩为一个固定长度的上下文向量(或序列),富含输入信息的语义。 | 自回归地生成输出序列,在每一步,根据之前的输出(或起始符)预测下一个 token。 | 两步走:编码器将输入编码为中间表示;解码器基于该表示自回归地生成输出。 |
| 注意力机制 | 通常使用自注意力来捕捉输入序列内部的关系(如BERT)。 | 使用掩码自注意力,确保生成时只能看到当前及之前的 token,不能看到未来的(如GPT)。 | 交叉注意力是关键。解码器在生成每个 token 时,会通过交叉注意力关注编码器输出的所有位置,动态提取相关信息。 |
| 典型架构 | Transformer Encoder Stack | Transformer Decoder Stack | 完整的Transformer:一个Encoder Stack + 一个Decoder Stack |
| 输入/输出 | 序列进,向量/序列出(与输入等长或池化) | 序列进,序列出(通常与输入不等长) | 序列进,序列出(输入与输出序列通常不等长) |
| 代表性模型 | BERT, RoBERTa, DistilBERT | GPT系列, BLOOM, LLaMA, ChatGLM | T5, BART, Transformer(原始论文模型) |
| 主要预训练任务 | 掩码语言模型,下一句预测 | 自回归语言模型(下一个token预测) | 去噪自编码(如T5的Span Corruption)、机器翻译 |
| 常见下游任务 | - 文本分类 - 情感分析 - 命名实体识别 - 自然语言推理 | - 文本生成(故事、代码、诗歌) - 对话系统(ChatGPT) - 零样本/少样本学习 | - 机器翻译 - 文本摘要 - 问答系统 - 语音识别 |
Model Head
AutoModel 是 Hugging Face 的 Transformers 库中的一个非常实用的类,它属于自动模型选择的机制。这个设计允许用户在不知道具体模型细节的情况下,根据给定的模型名称或模型类型自动加载相应的预训练模型。它减少了代码的重复性,并提高了灵活性,使得开发者可以轻松地切换不同的模型进行实验或应用。
Model Head(模型头)
Model Head 在预训练模型的基础上添加一层或多层的额外网络结构来适应特定的模型任务,方便于开发者快速加载 transformers 库中的不同类型模型,不用关心模型内部细节。
- ForCausalLM:因果语言模型头,用于 decoder 类型的任务,主要进行文本生成,生成的每个词依赖于之前生成的所有词。比如 GPT、Qwen
- ForMaskedLM:掩码语言模型头,用于 encoder 类型的任务,主要进行预测文本中被掩盖和被隐藏的词,比如 BERT。
- ForSeq2SeqLM:序列到序列模型头,用于 encoder-decoder 类型的任务,主要处理编码器和解码器共同工作的任务,比如机器翻译或文本摘要。
- ForQuestionAnswering:问答任务模型头,用于问答类型的任务,从给定的文本中抽取答案。通过一个 encoder 来理解问题和上下文,对答案进行抽取。
- ForSequenceClassification:文本分类模型头,将输入序列映射到一个或多个标签。例如主题分类、情感分类。
- ForTokenClassification:标记分类模型头,用于对标记进行识别的任务。将序列中的每个标记映射到一个提前定义好的标签。如命名实体识别,打标签
- ForMultiplechoice:多项选择任务模型头,包含多个候选答案的输入,预测正确答案的选项。
Model 基本使用方法
- 模型加载与保存
- 在线加载
- 模型下载
- 离线加载
- 模型加载参数
- 模型调用
- 不带 model head 的模型调用
- 带 model head 的模型调用
model 使用
参见:model_1.py