Transformers - Encoding and Decoding Context with Attention
概述
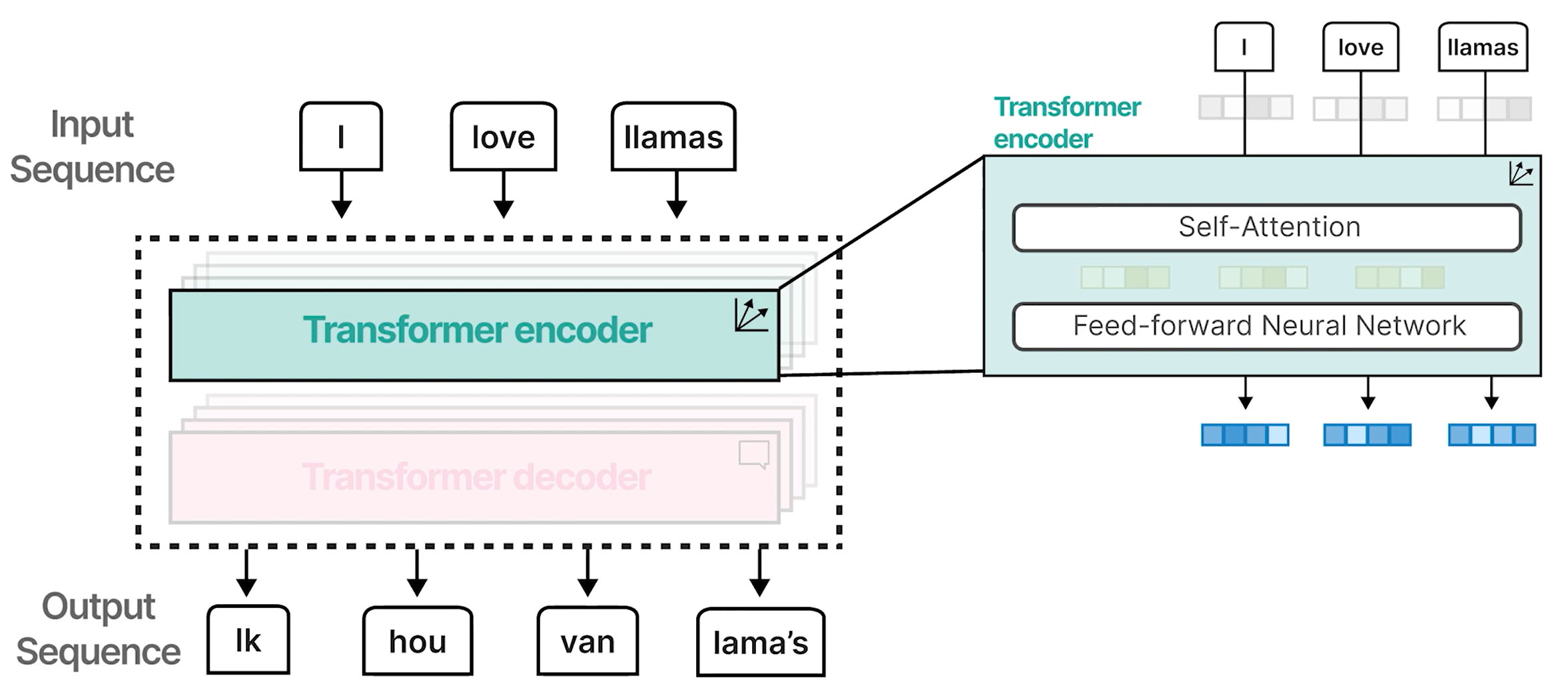
一种完全基于注意力机制、没有 RNN 的新架构
可以并行训练,从而显著加快计算速度
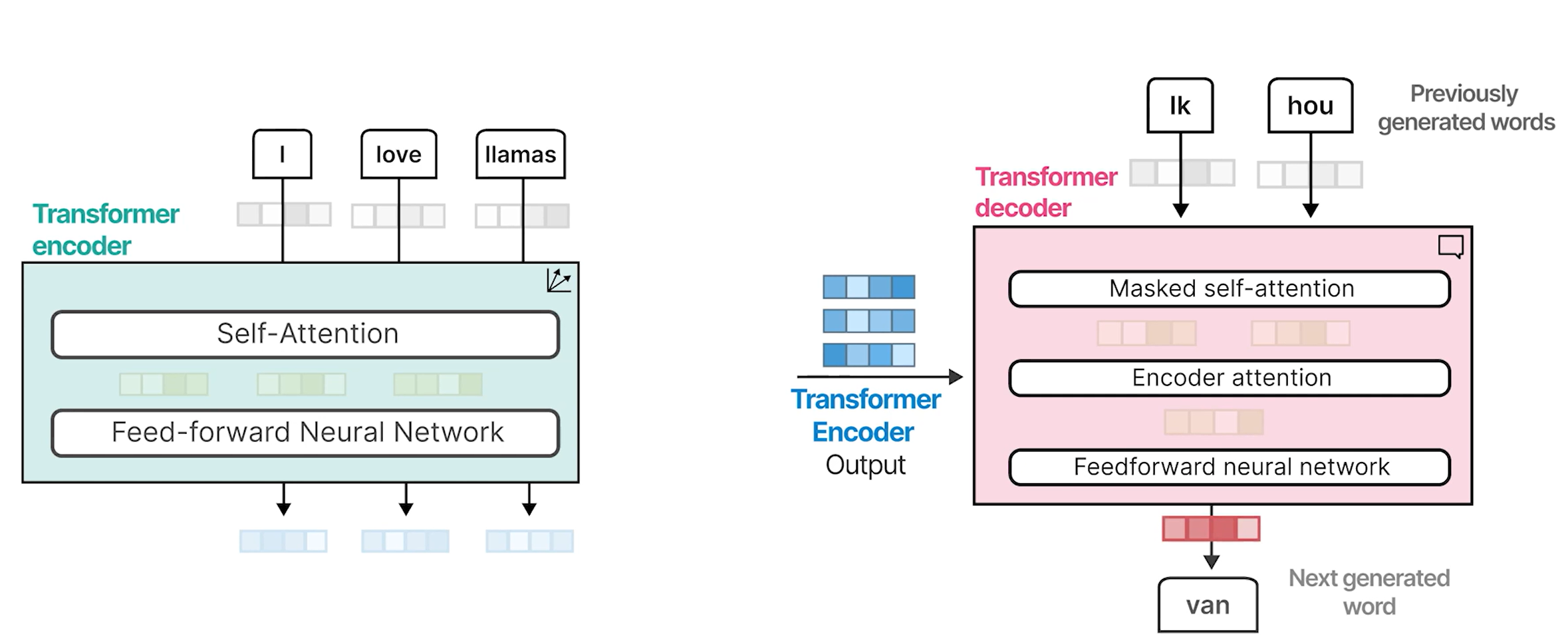
堆叠这些块可以增强编码器和解码器的强度。
表现模型
BERT
BERT(Bidirectional Encoder Representations from Transformers,来自 Transformer 的双向编码器表示)
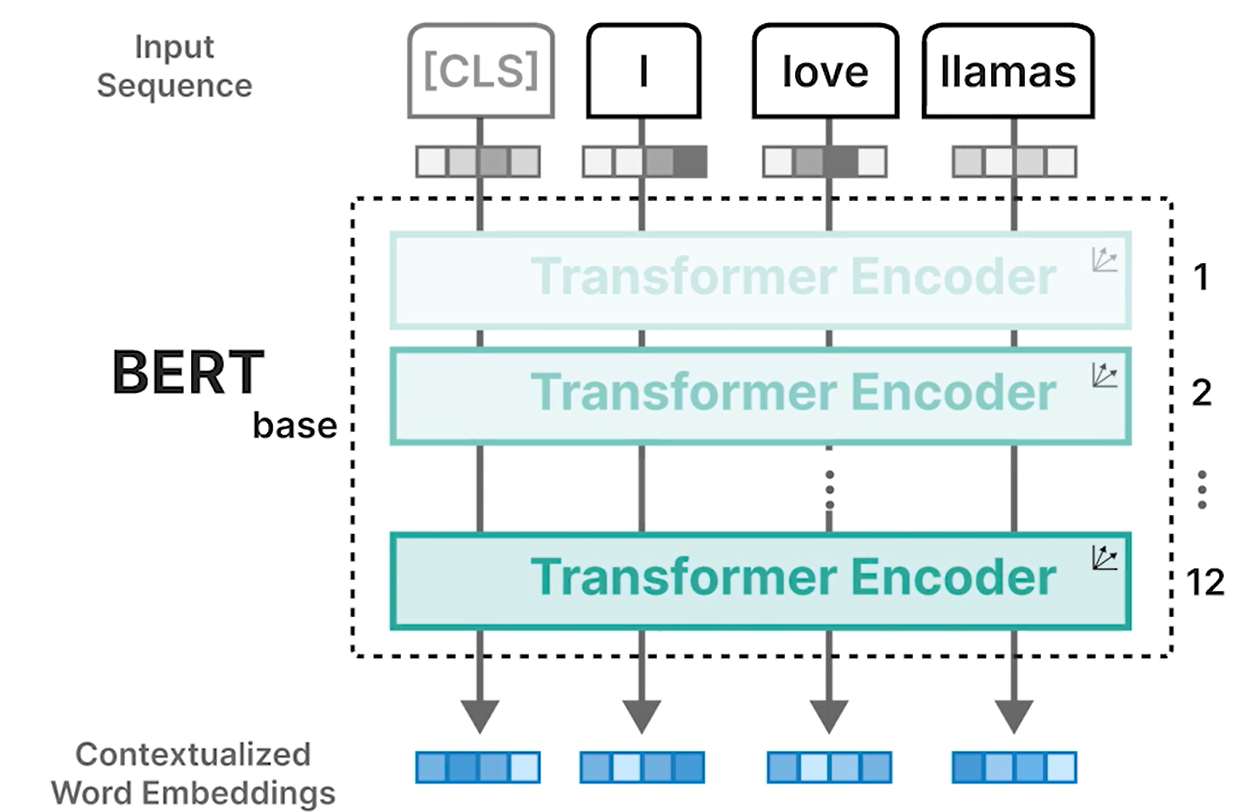
- BERT 专注于表示语言和生成上下文词嵌入
- [CLS] 标记(分类标记)
- 附加输入标记:用作整个输入的表示
- 通常用作输入嵌入,用于在分类等特定任务上微调模型
- 掩蔽语言建模
- 训练
- 输入序列中的一些单词随机被掩蔽
- 模型经过训练可以预测这些掩蔽的单词
- 通过这样做,模型在尝试解构这些掩蔽的单词时学会表示语言
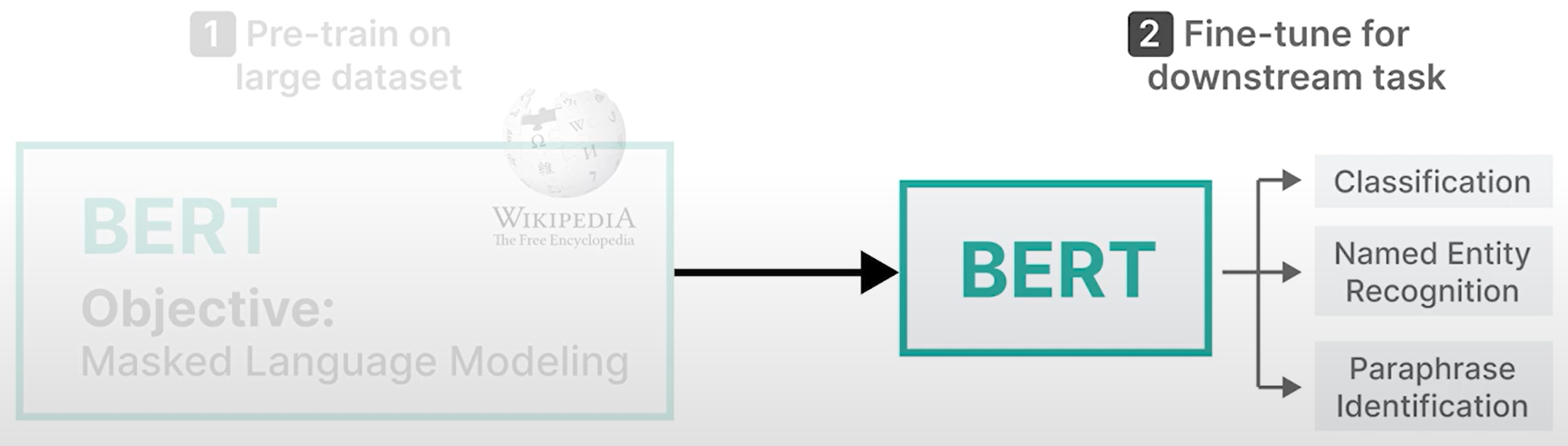
- 训练
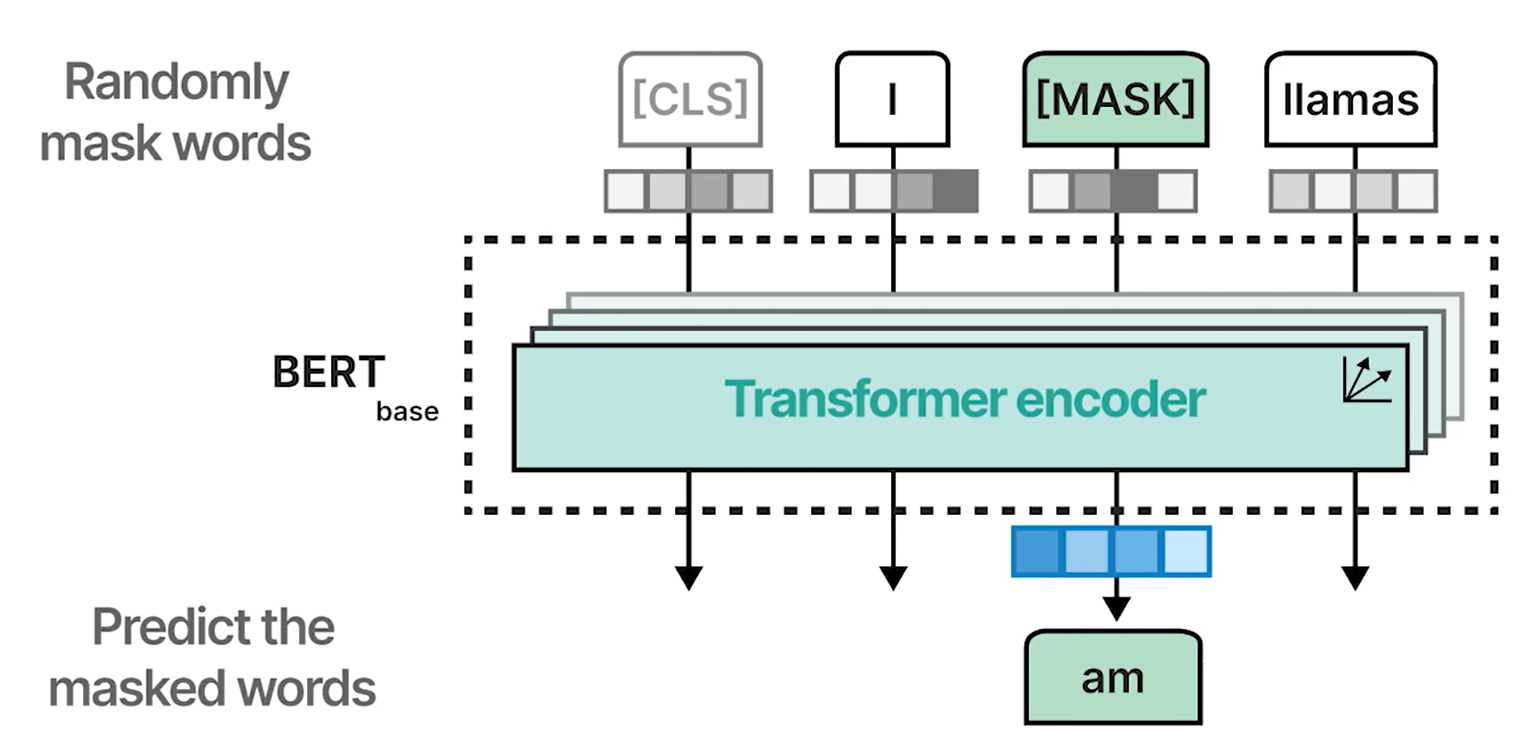
训练是一个两步过程:
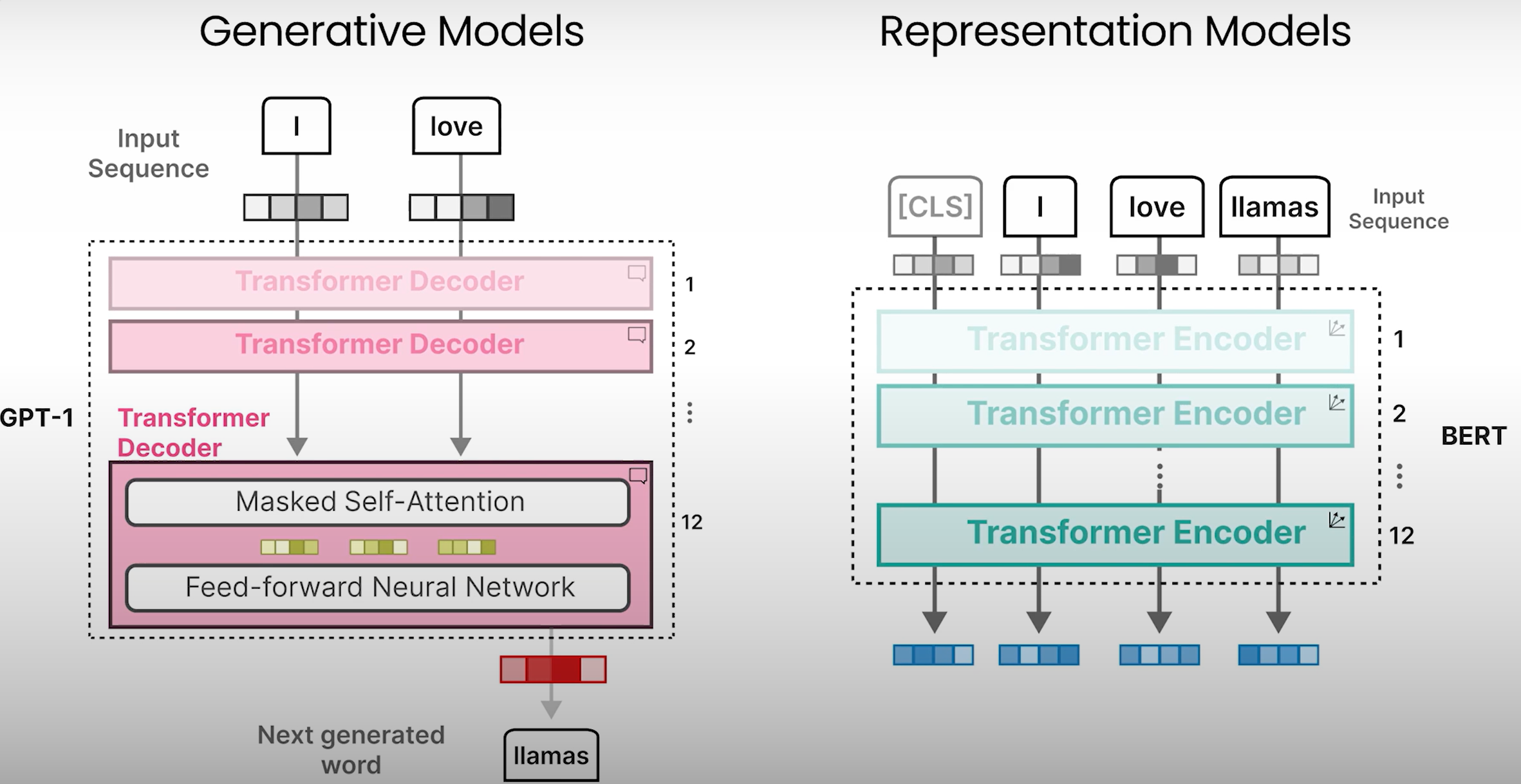
生成模型
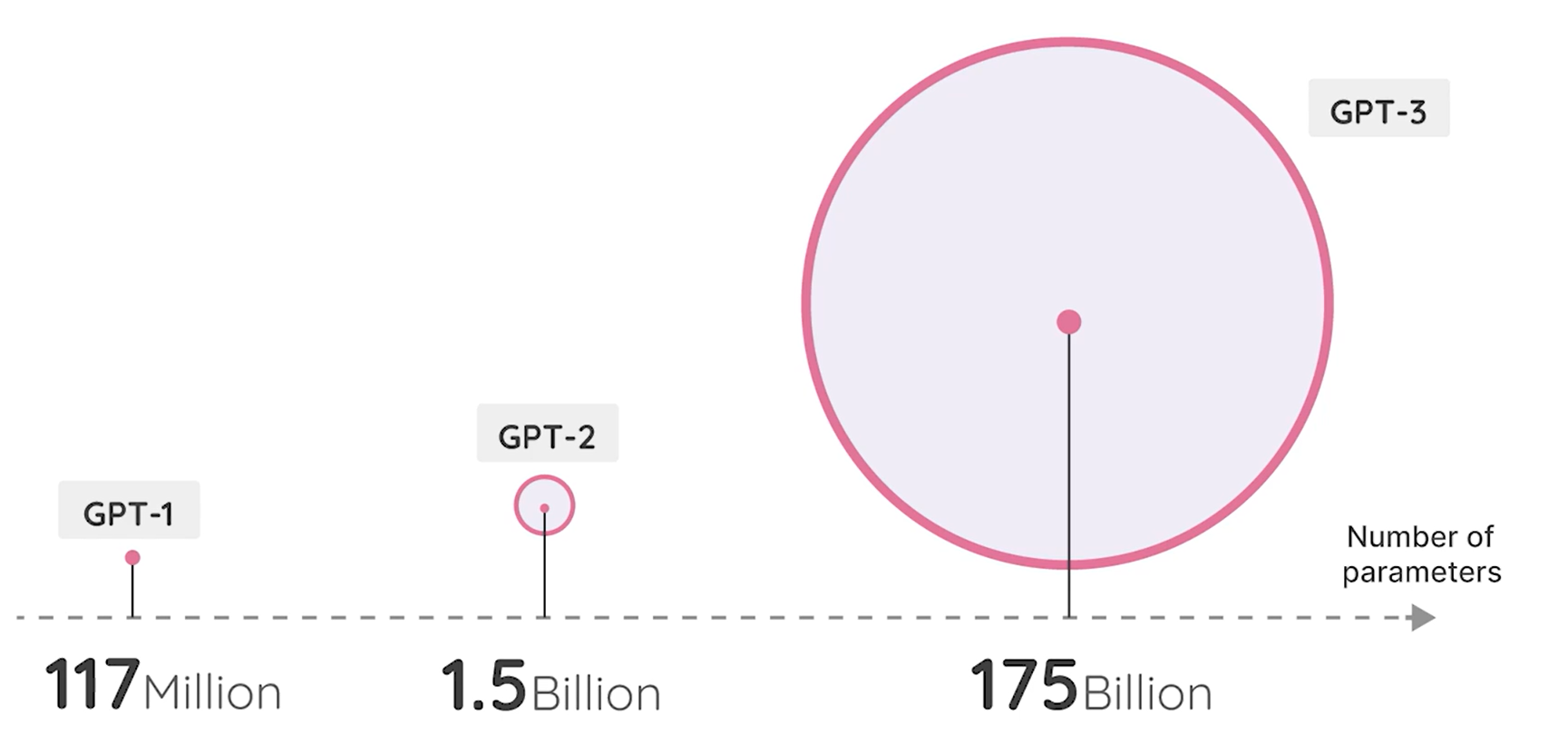
Generative Pre-Trained Transformer (GPT)
嵌入是随机初始化的
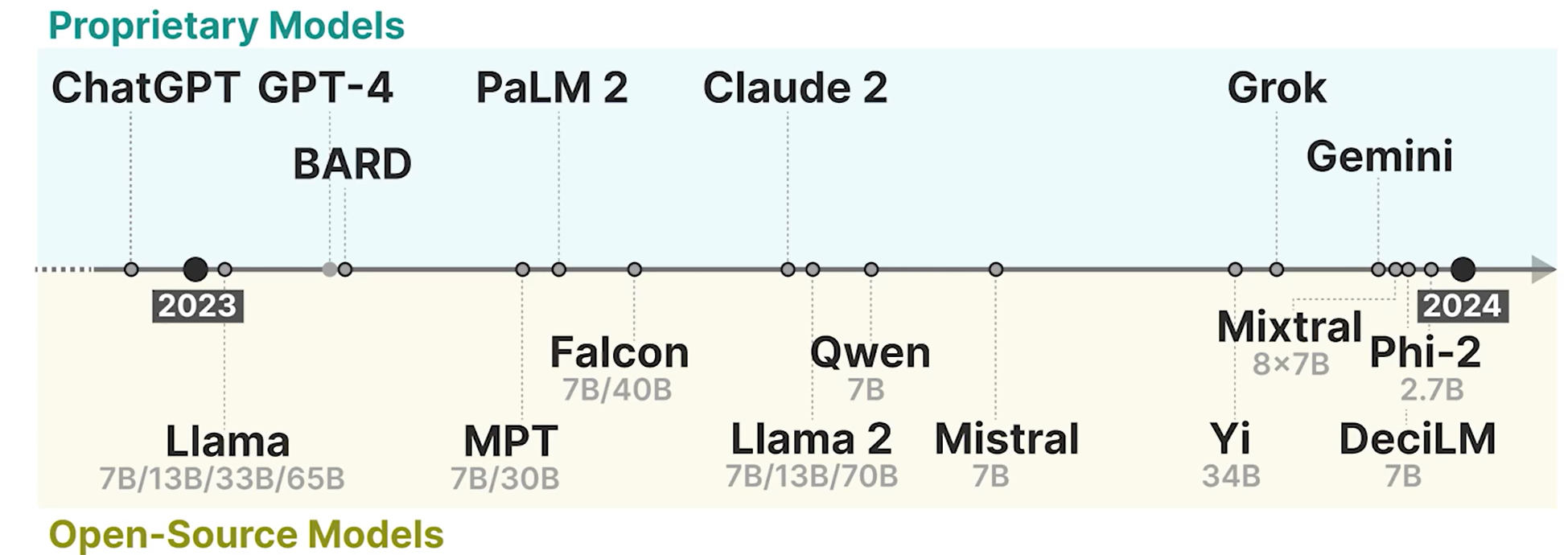
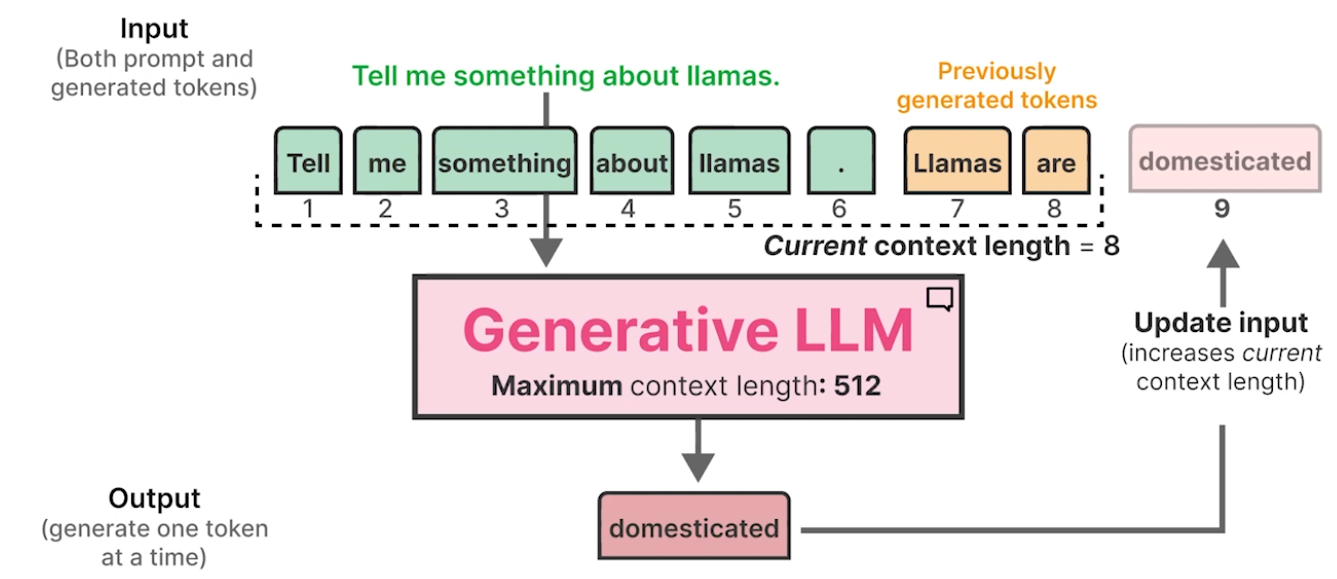
Context Length
Parameters
Year of Generative AI