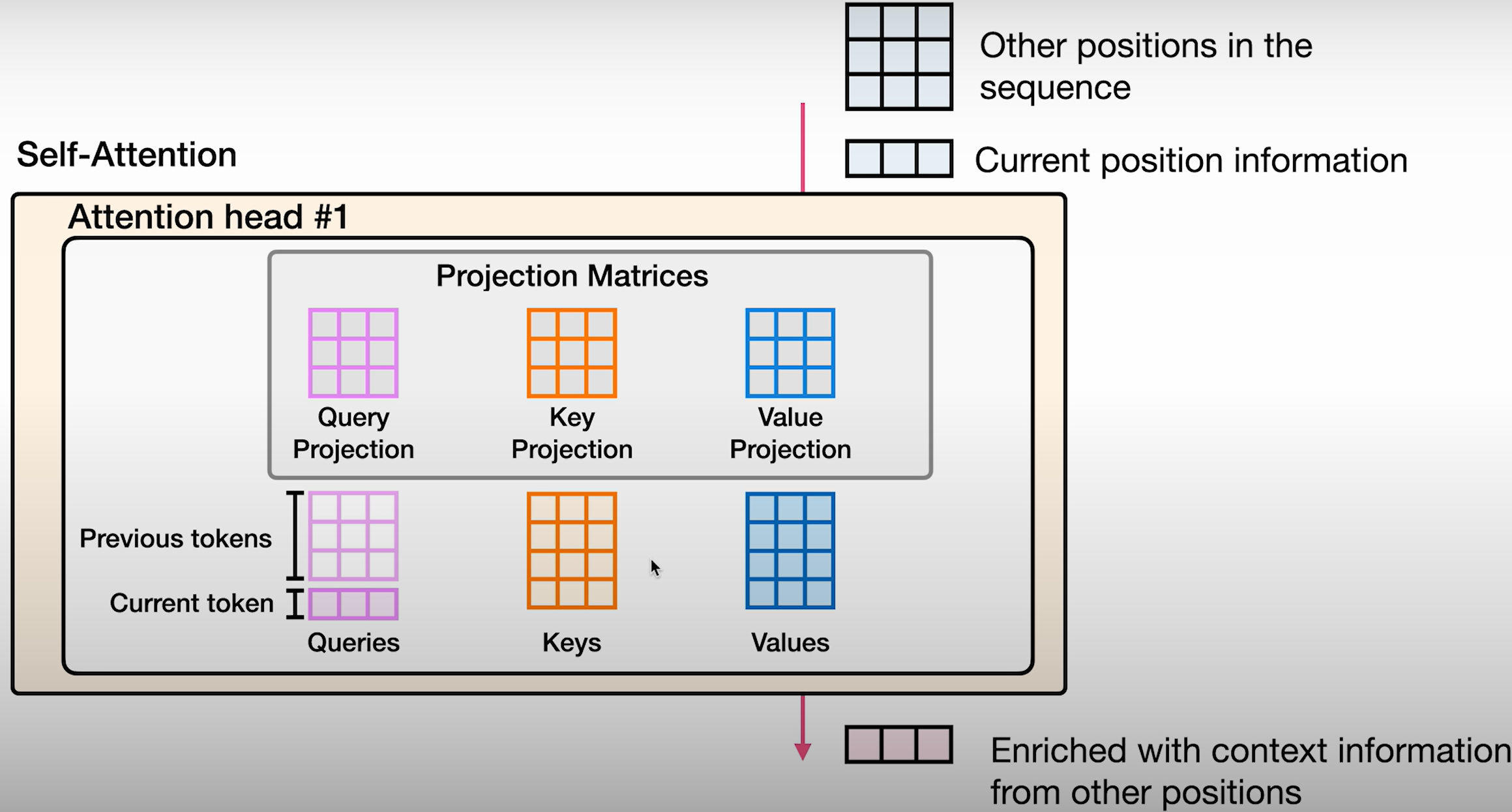
Transformer - 自注意力
概念
投影矩阵
相关性评分的最终目标
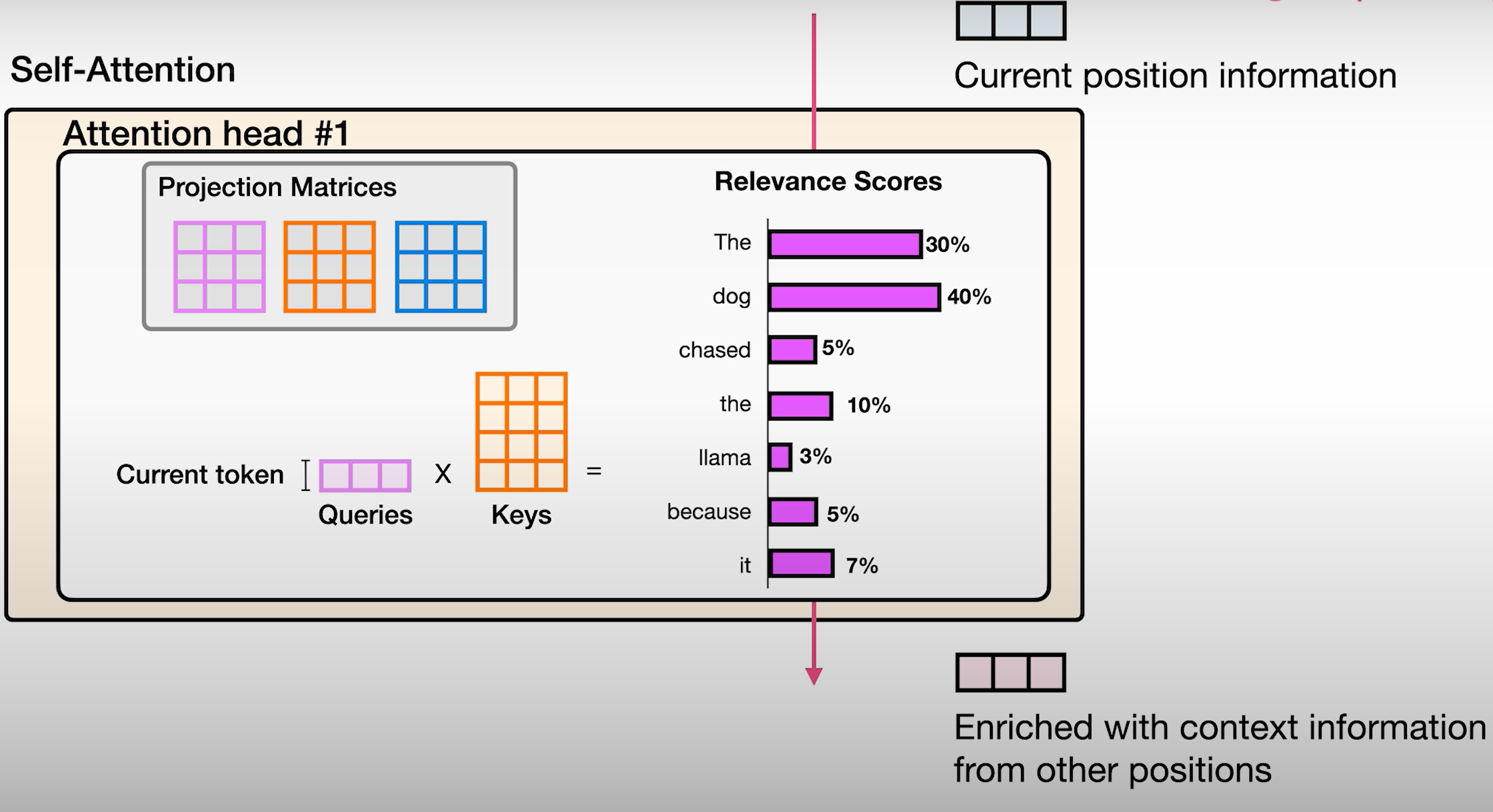
推荐的注意力课程:
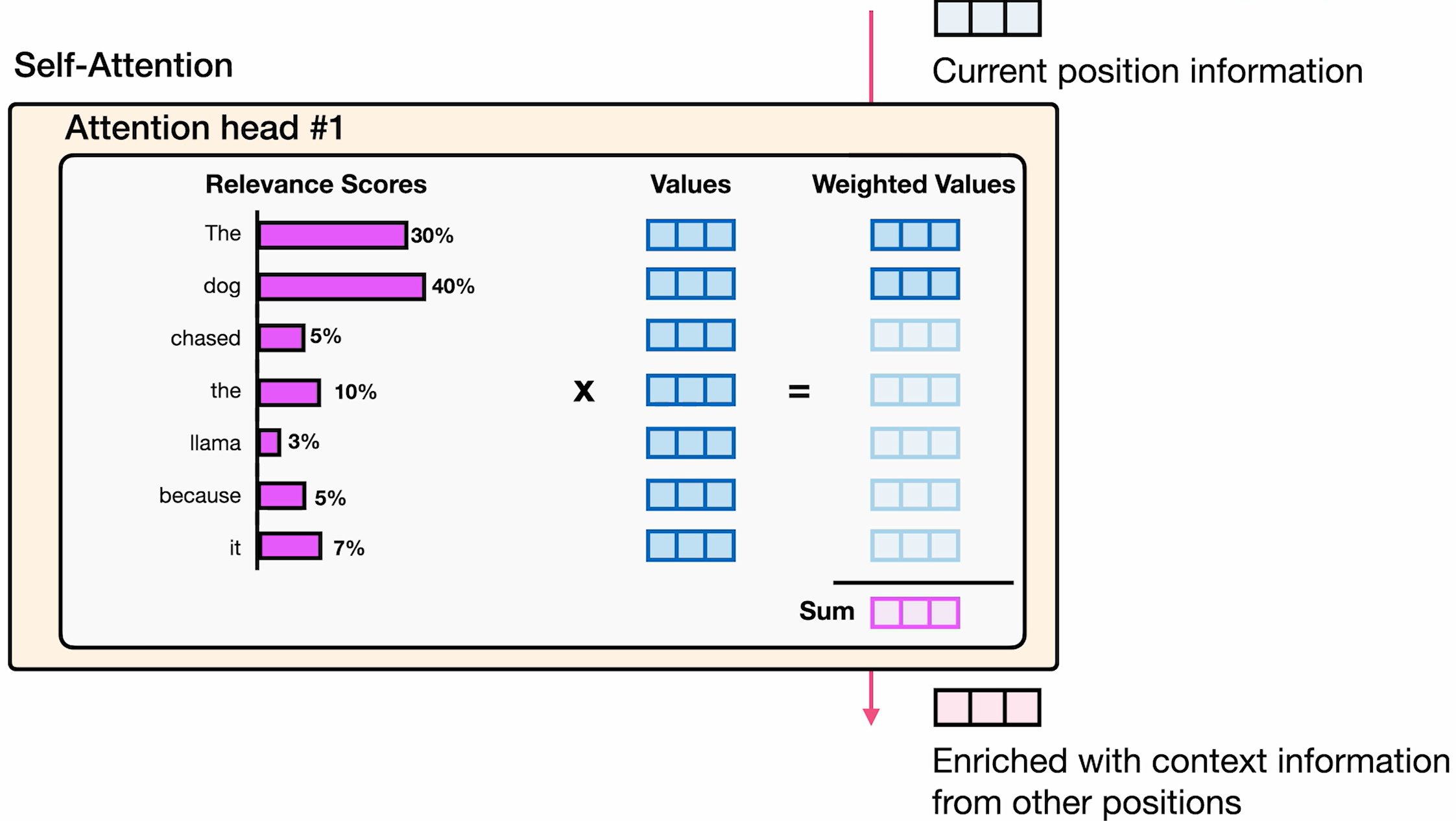
与其他token的联合信息
Multi-Head Attention
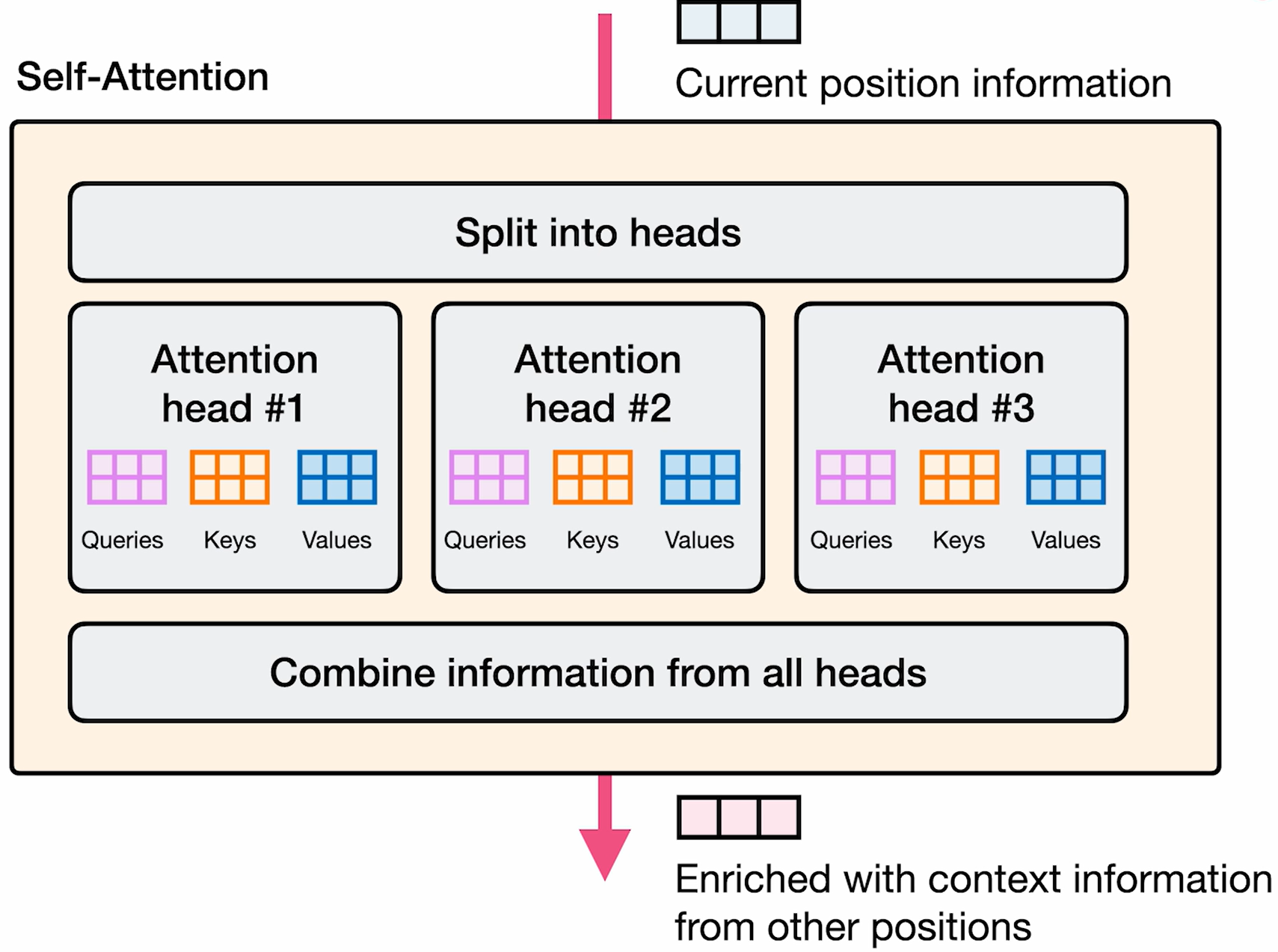
每个注意力头都有自己的键、查询、值矩阵
Multi-Query Attention
- 高效计算自注意力的方法之一
- 自注意力组件贡献了大部分计算
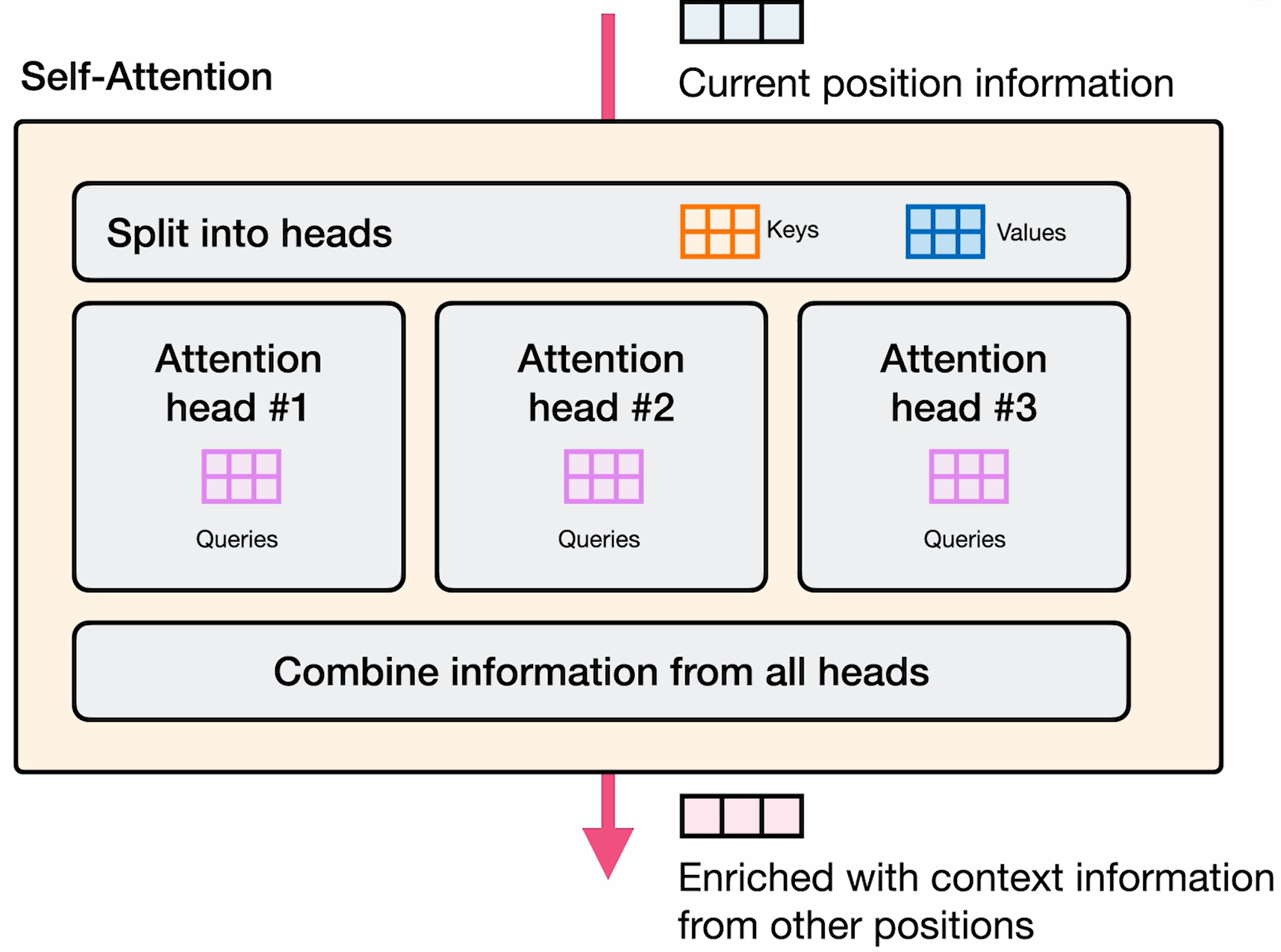
- 每个转换器块共享键和值矩阵
- 可以视为参数的压缩
Grouped-Query Attention
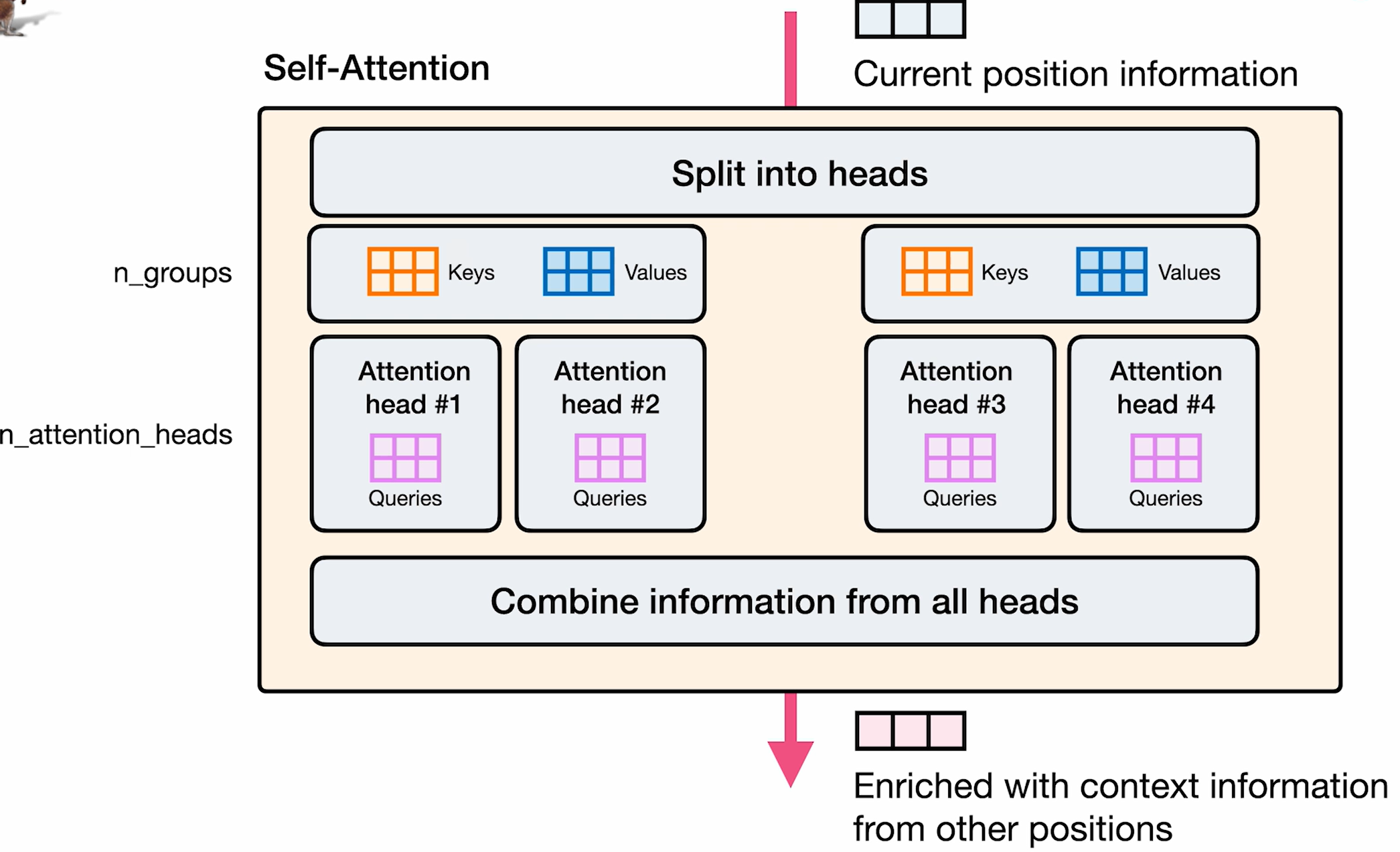
- 它不是单个键和值矩阵,而是具有相同数量的组。
- 对于大型模型,其效果比多查询注意力更好。
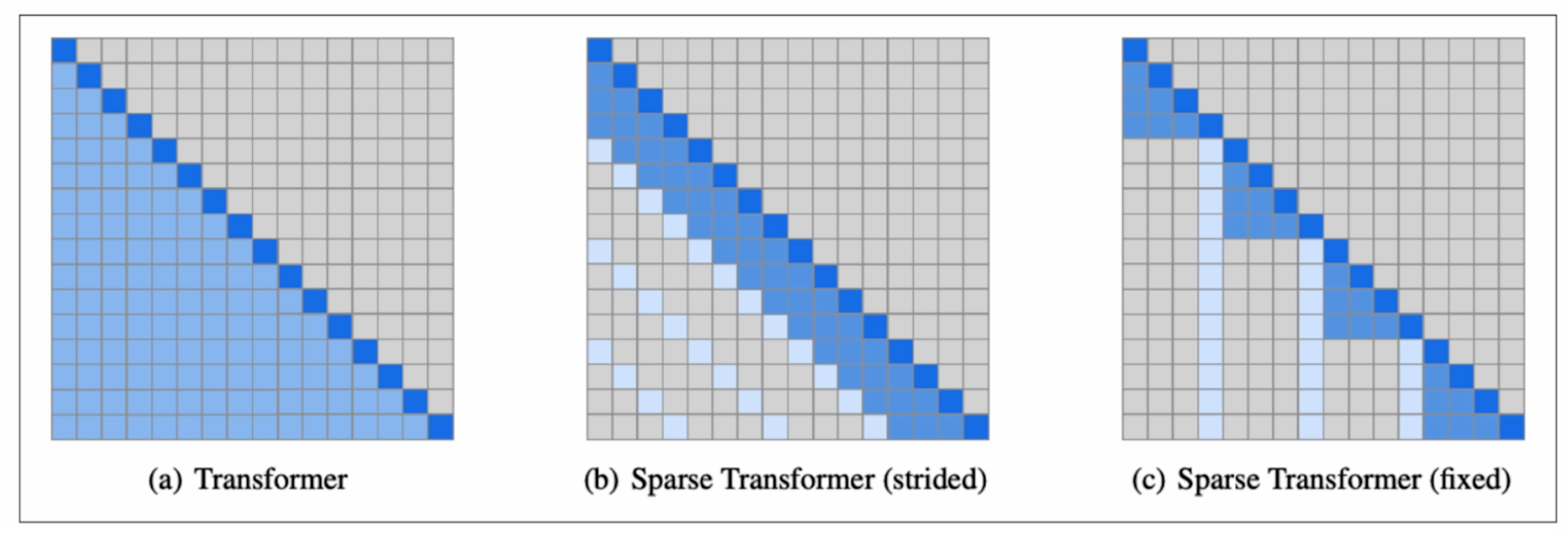
Sparse Attention, 稀疏注意力
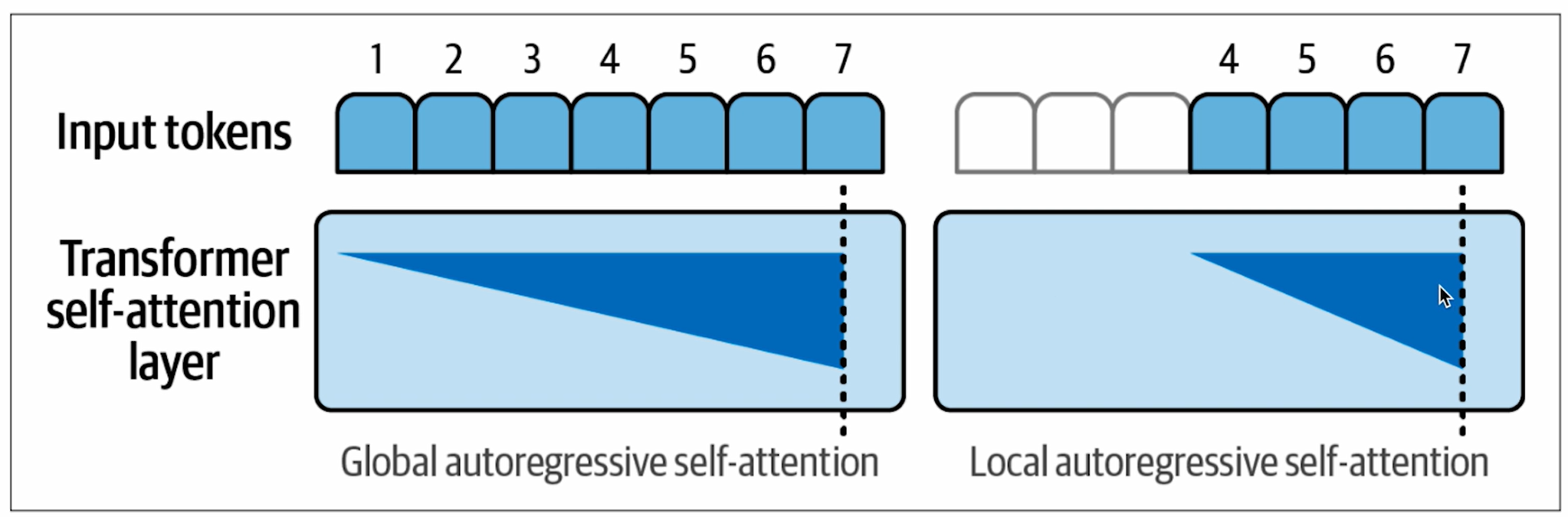
- 局部注意力通过仅关注少数先前位置来提高大型模型的性能。
- 这不需要应用于所有层。
- 第一层可以关注所有先前位置。
- 但交错层可以关注少数先前位置。
- 完全注意力 vs 稀疏注意力
Ring Attention
使用多个设备扩展到接近无限的上下文窗口
Referred blog: Coconut Mode
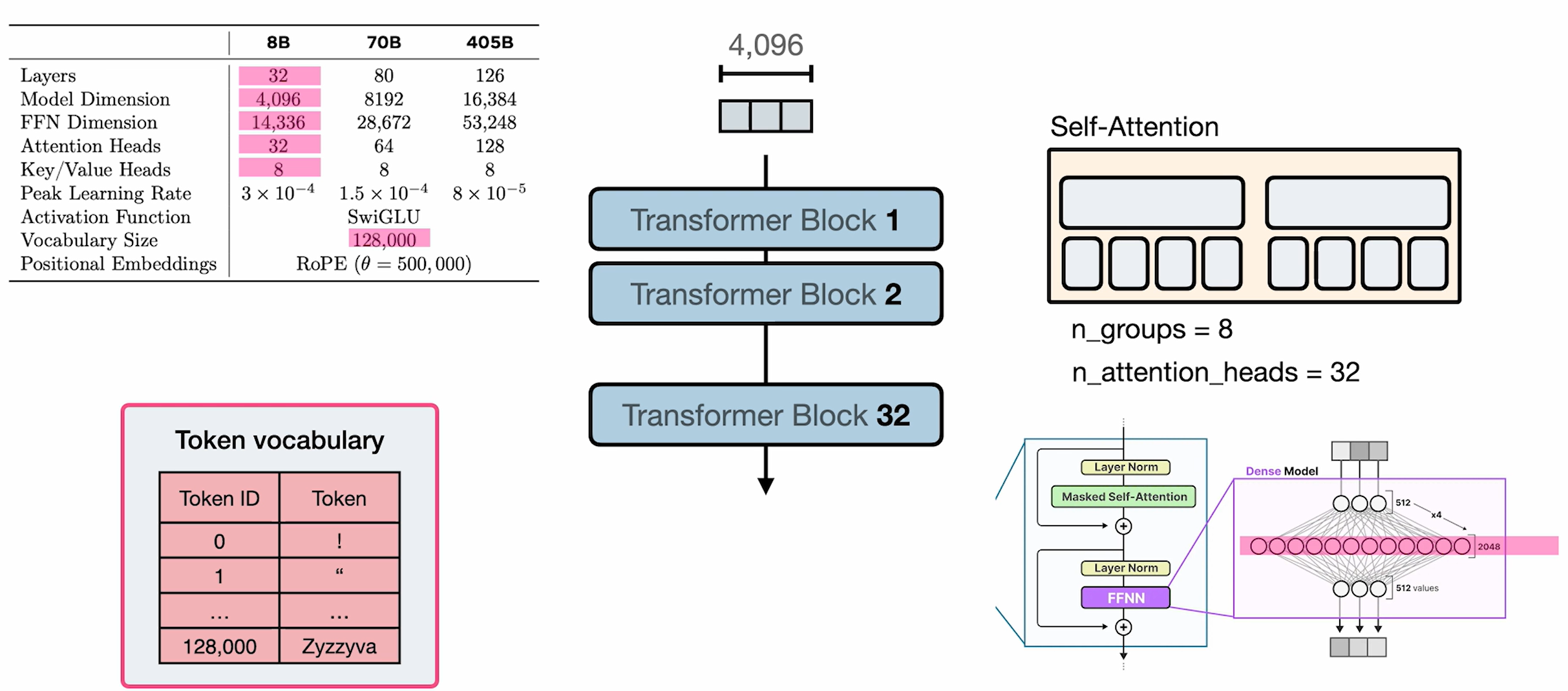
Paper: The Llama 3 Herd of Models
- 8B parameter model's hyperparameters visualization