
RAG - 进阶
高级 RAG 技术概览
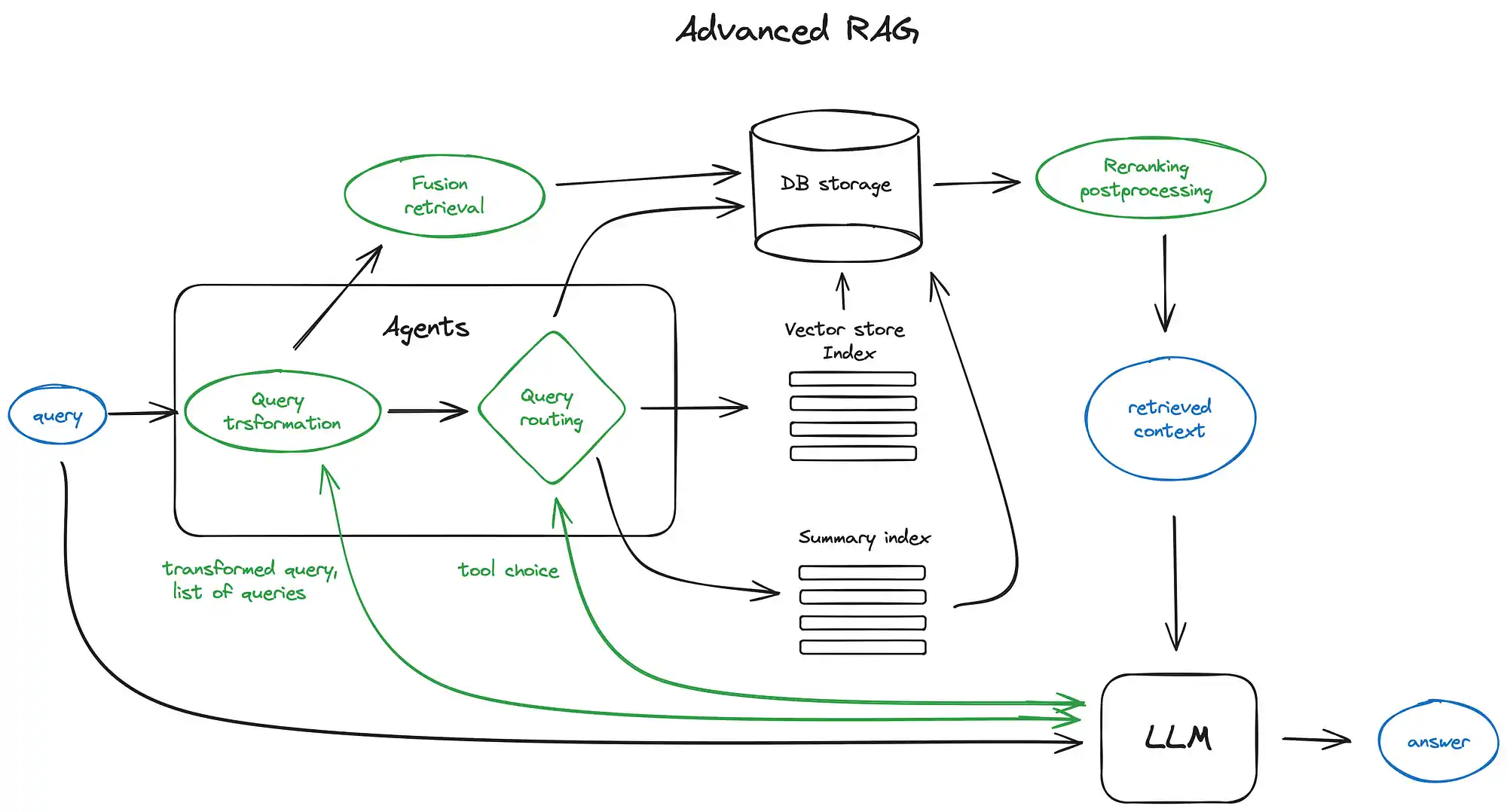
具体过程
本文详细探讨了高级检索增强生成(RAG)技术的各个过程,以下是各个关键步骤的总结:
数据准备:
- 分块(Chunking):将文档内容分割成适当大小的小块,以便更好地表示其语义。
- 向量化(Vectorisation):使用Embedding 模型(嵌入模型)将文本块转换为向量,便于后续的检索。
- Embedding 是将高维离散数据(如单词、句子)映射到低维连续向量空间的过程。(词嵌入、句子嵌入、文档嵌入、多模态嵌入)
搜索索引(RAG的核心):
- 向量存储索引:构建一个索引来存储向量,以便快速检索相关文本块。
- 分层索引:策略:构建摘要索引和各部分文档块索引。先通过摘要筛选相关文档,再在此筛选出的相关文档中继续深度搜索,以此来优化检索效率。
- 假设性问题和HyDE:生成与文档相关的问题向量,以提升检索的精准度。(让大语言模型为文档的每个部分产生一个问题,并把这些问题转换成数学上的向量)
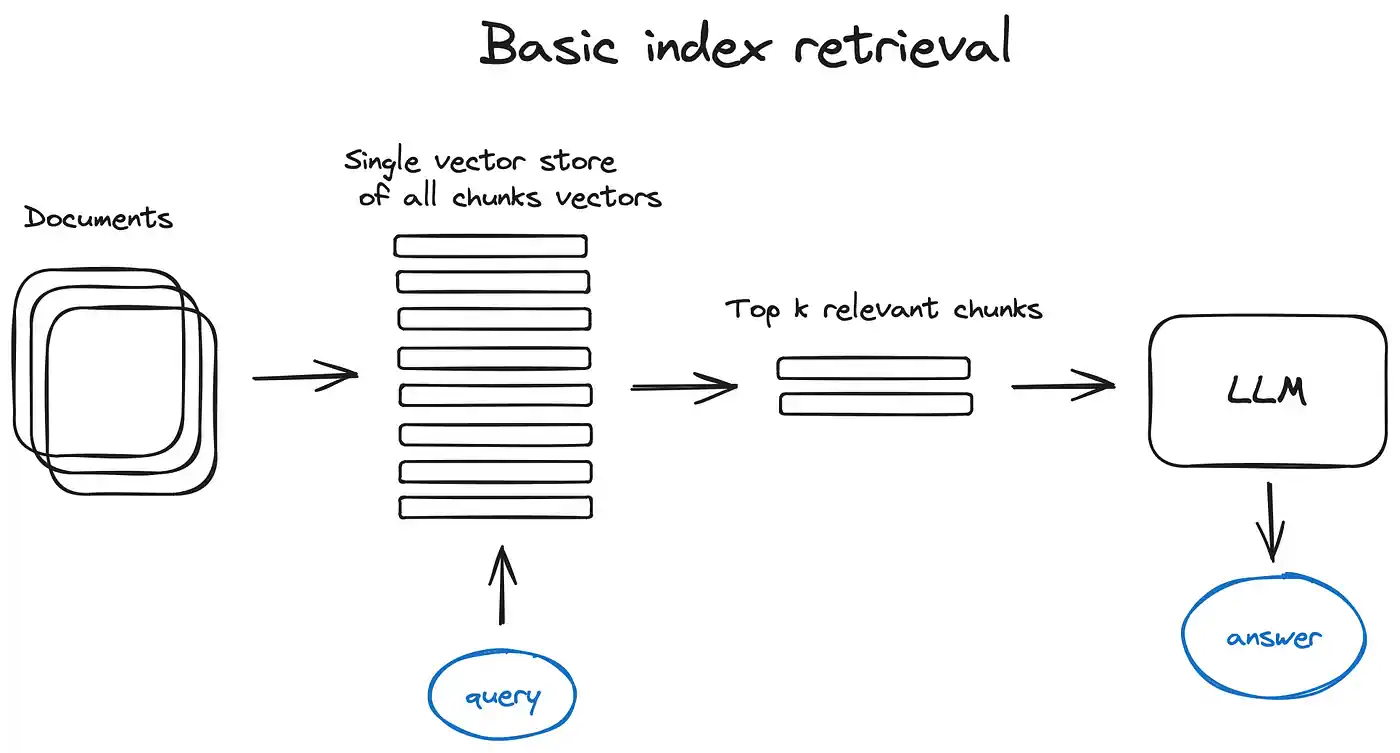
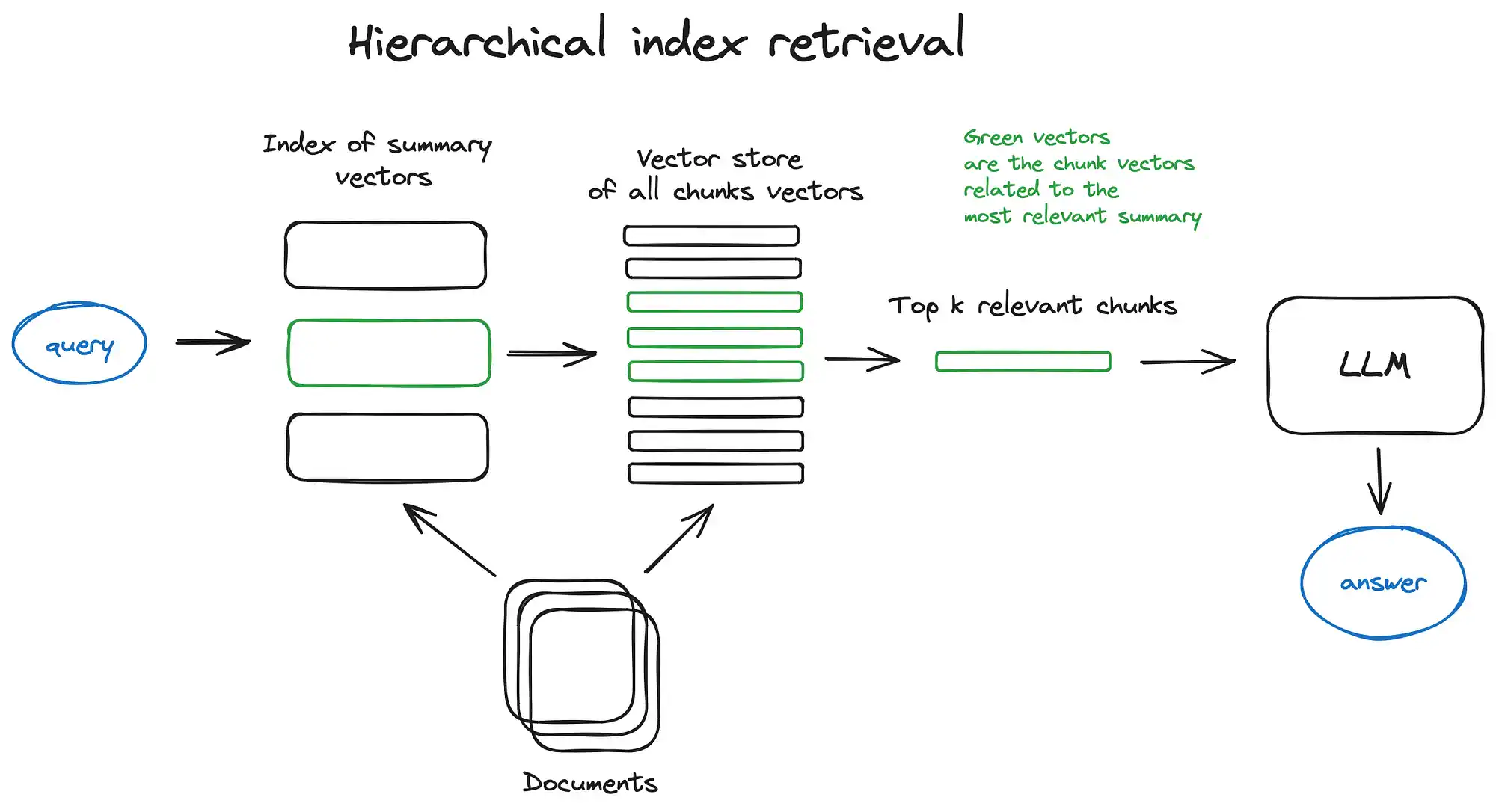
- 检索过程:
- 语境增强:通过检索更小的信息块来提高搜索质量,同时为大语言模型增加更多周围语境以便其进行推理。
- 融合检索或混合搜索:结合传统的基于关键词的搜索和现代的语义或向量搜索。
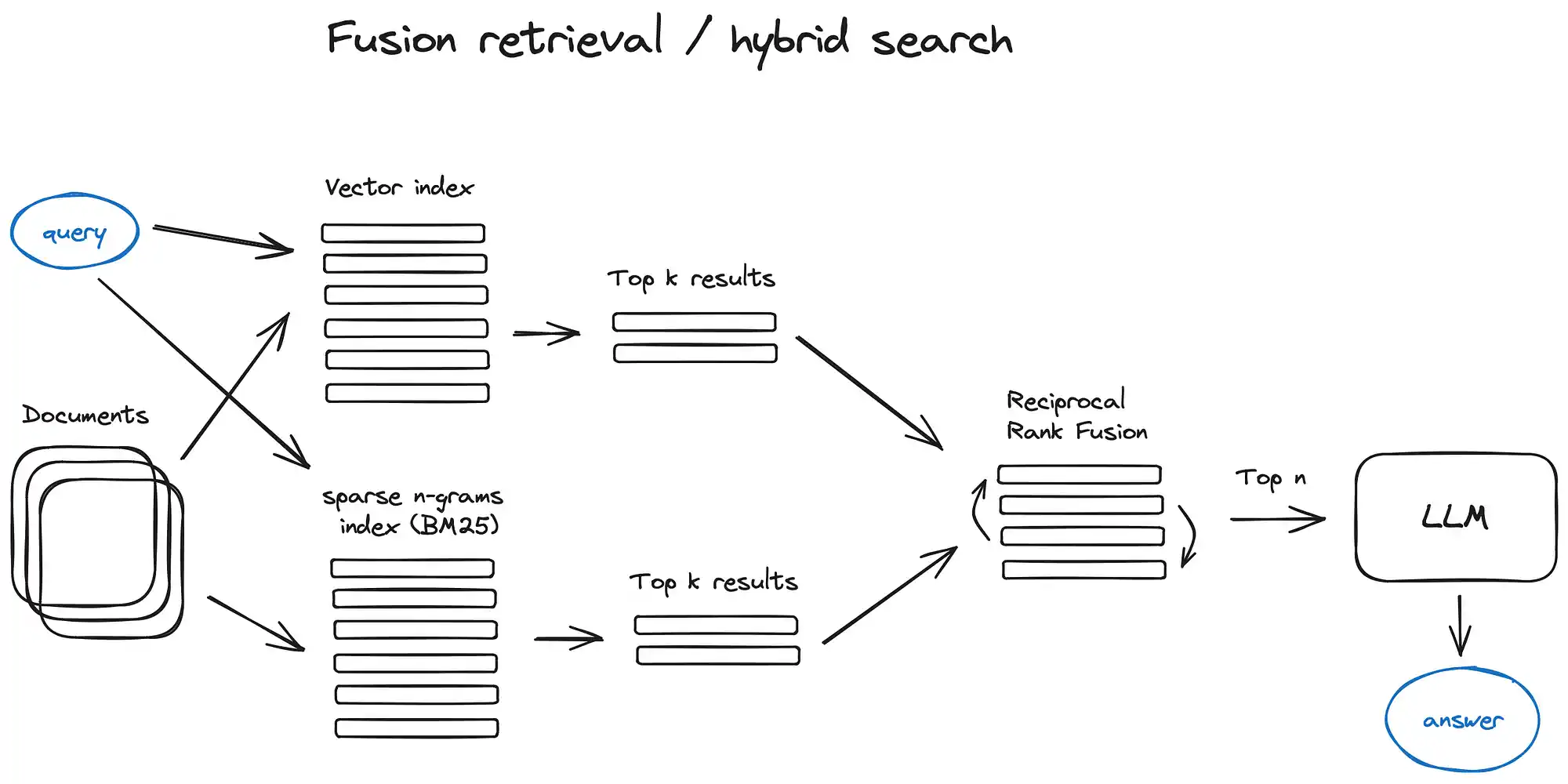
- 结果处理:
- 重新排名与过滤:对初步检索结果进行过滤和重新排序,以优化最终输出。
- 查询变换:利用大语言模型作为推理引擎,对用户输入进行调整的一系列技术,目的是提升检索的质量。(对于复杂的查询,大语言模型能够将其拆分为多个子查询。)
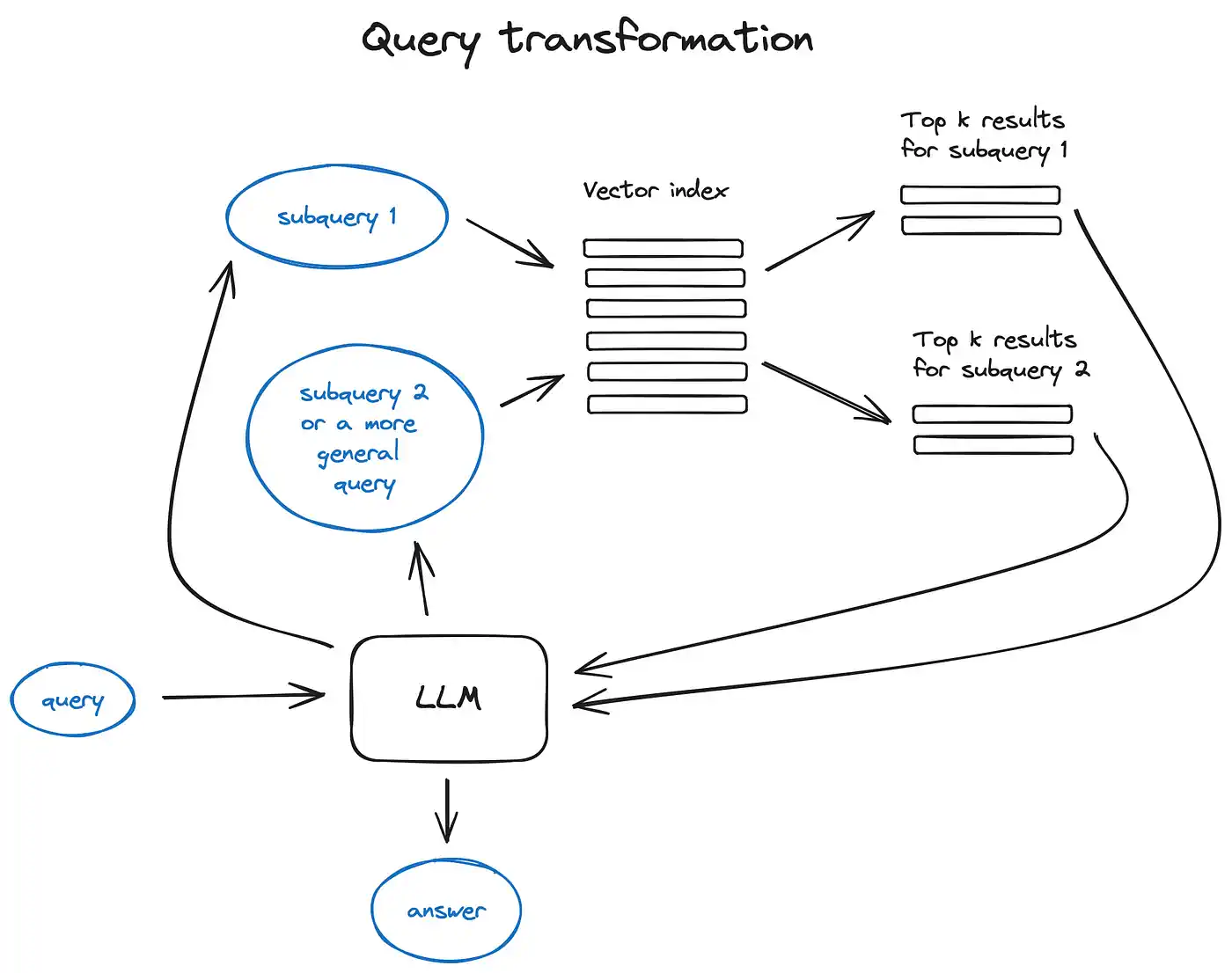
查询路由:
- 接收到用户的查询后,由大语言模型决定接下来的操作步骤。
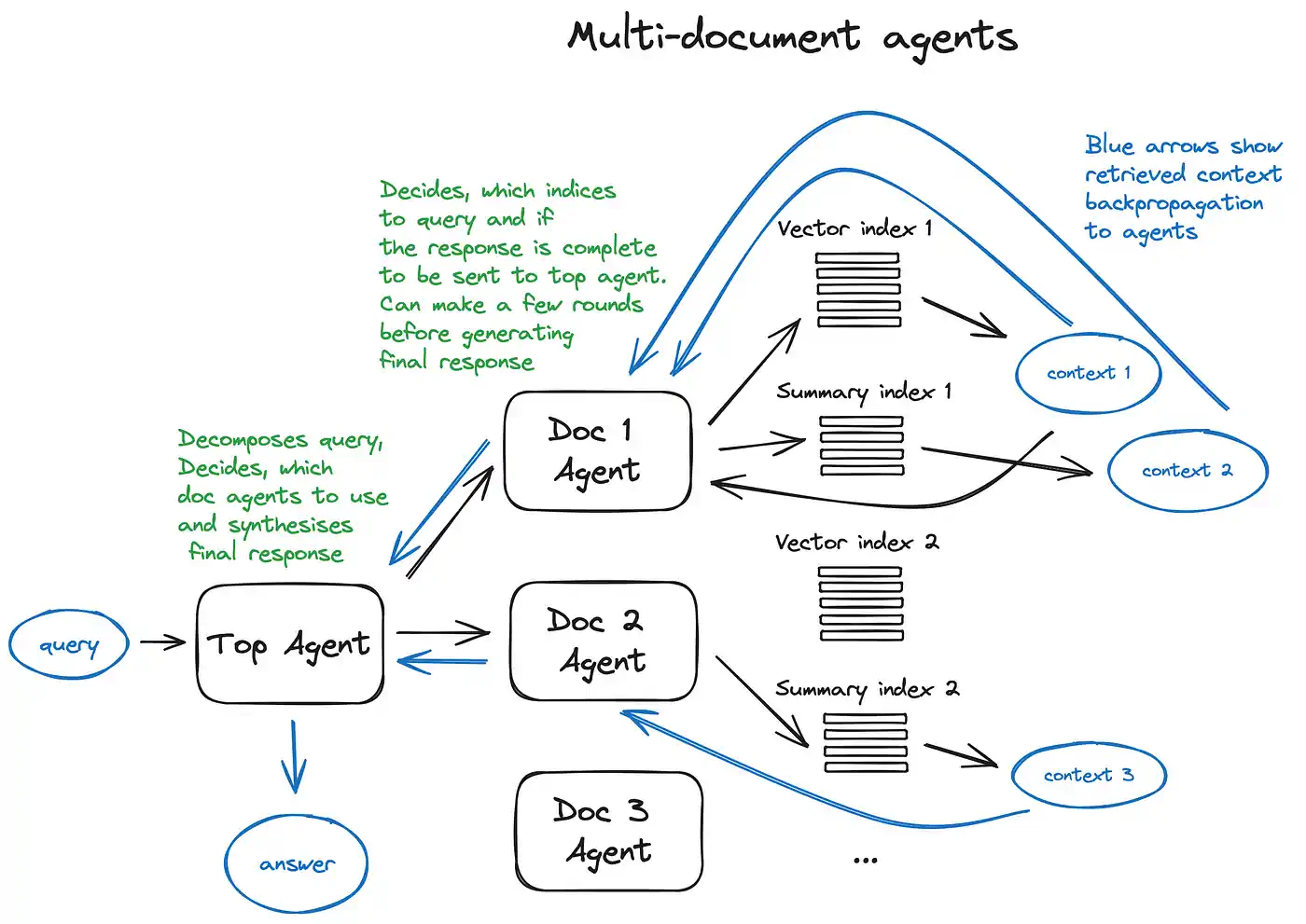
RAG 中的 AI 智能体:
- 多文档智能体的方案。
响应合成:
- 通过逐块发送检索的上下文到大语言模型,以逐步优化答案
- 概括检索的上下文,使其适应提示条件
- 根据不同的上下文块生成多个答案,然后将它们整合或概括。
模型微调:
- 编码器微调 (Encoder fine-tuning)
- 排序器微调 (Ranker fine-tuning)
- 大语言模型微调
- 对编码器和大语言模型进行微调,以提高检索和生成答案的质量。
评估:
- 使用多种指标评估RAG系统的性能,包括答案的相关性、真实性和检索内容的相关性。
- 评估指标: 答案的相关性、答案的基于性、真实性和检索到的内容的相关性等。
- 使用多种指标评估RAG系统的性能,包括答案的相关性、真实性和检索内容的相关性。
这些步骤共同构成了RAG技术的核心流程,旨在通过结合信息检索与生成模型,提供更准确和相关的答案。