
蒸馏 - 概述
概述
在知识蒸馏中,一个小的“学生”模型学习模仿一个大的“老师”模型,并利用老师的知识来获得相似或更高的准确率。基本原理所下图所示:
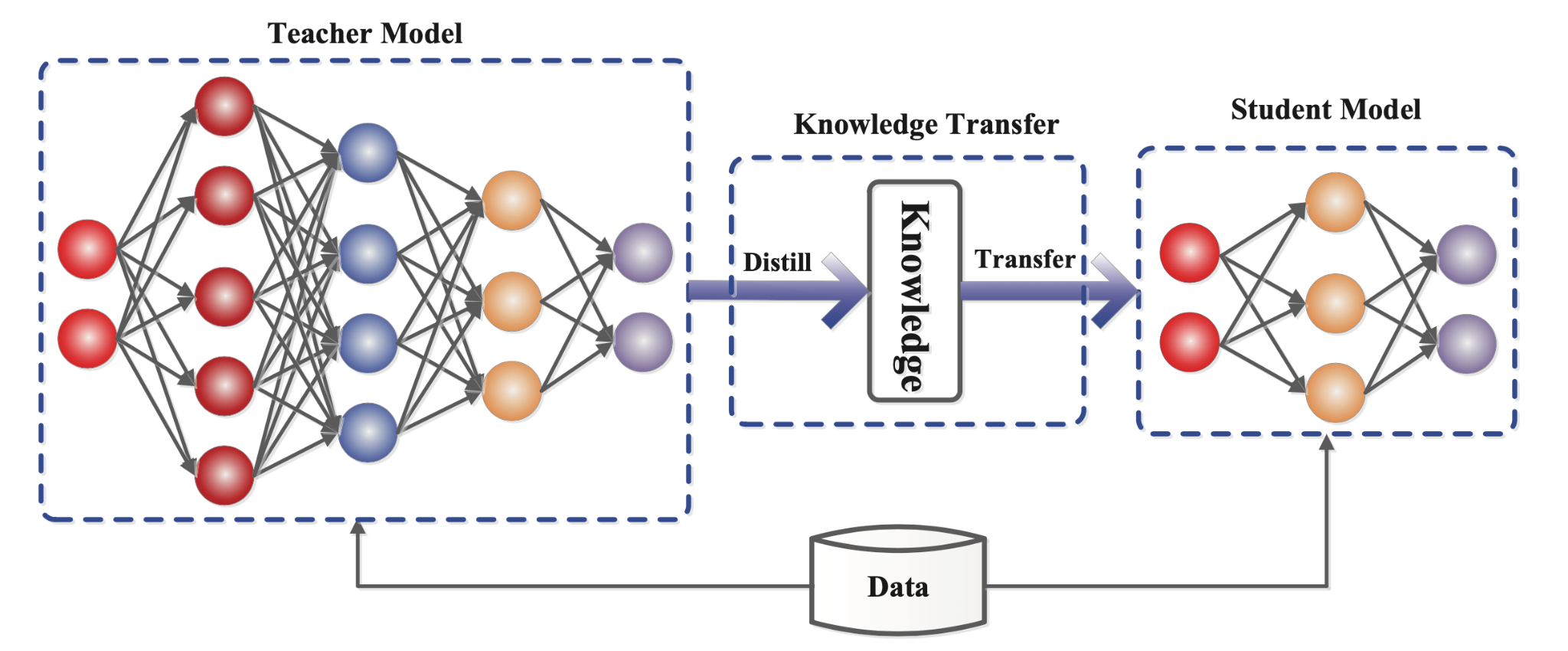
深入探索知识提炼
知识蒸馏系统由三个主要部分组成:知识、蒸馏算法和师生架构
知识
在神经网络中,知识通常是指学习到的权重和偏差。同时,大型深度神经网络中知识来源的多样性也十分丰富。典型的知识蒸馏使用 logits 作为教师知识的来源,而其他知识蒸馏则侧重于中间层的权重或激活。其他类型的相关知识包括不同类型的激活与神经元之间的关系或教师模型本身的参数。
不同形式的知识分为三种不同的类型:基于响应的知识、基于特征的知识和基于关系的知识。下图说明了教师模型中的这三种不同类型的知识。
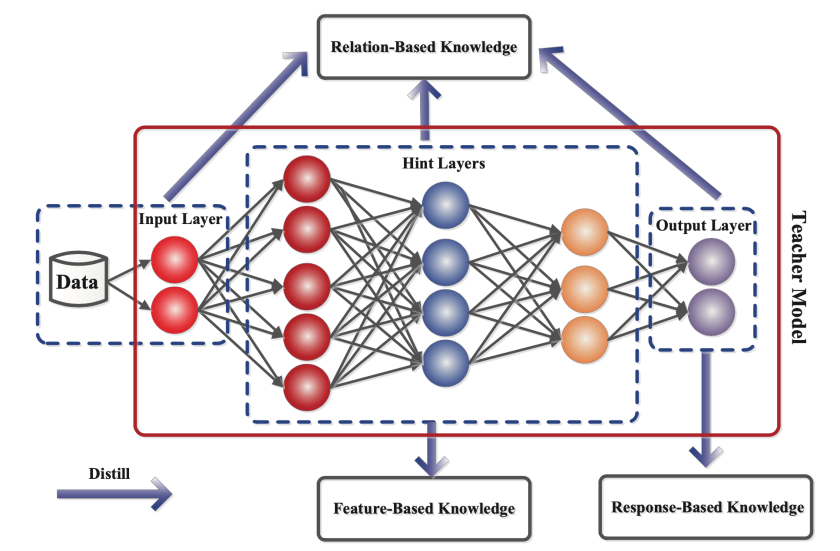
基于响应的知识
基于响应的知识侧重于教师模型的最终输出层。假设学生模型将学会模仿教师模型的预测。可以通过使用损失函数(称为蒸馏损失)来实现,该函数分别捕获学生和教师模型的对数之间的差异。随着这种损失在训练过程中最小化,学生模型将变得更善于做出与教师相同的预测。
在图像分类等计算机视觉任务中,软目标包含基于响应的知识。软目标表示输出类别的概率分布,通常使用 softmax 函数进行估计。每个软目标对知识的贡献都使用称为温度的参数进行调节。基于软目标的基于响应的知识提炼通常用于监督学习。
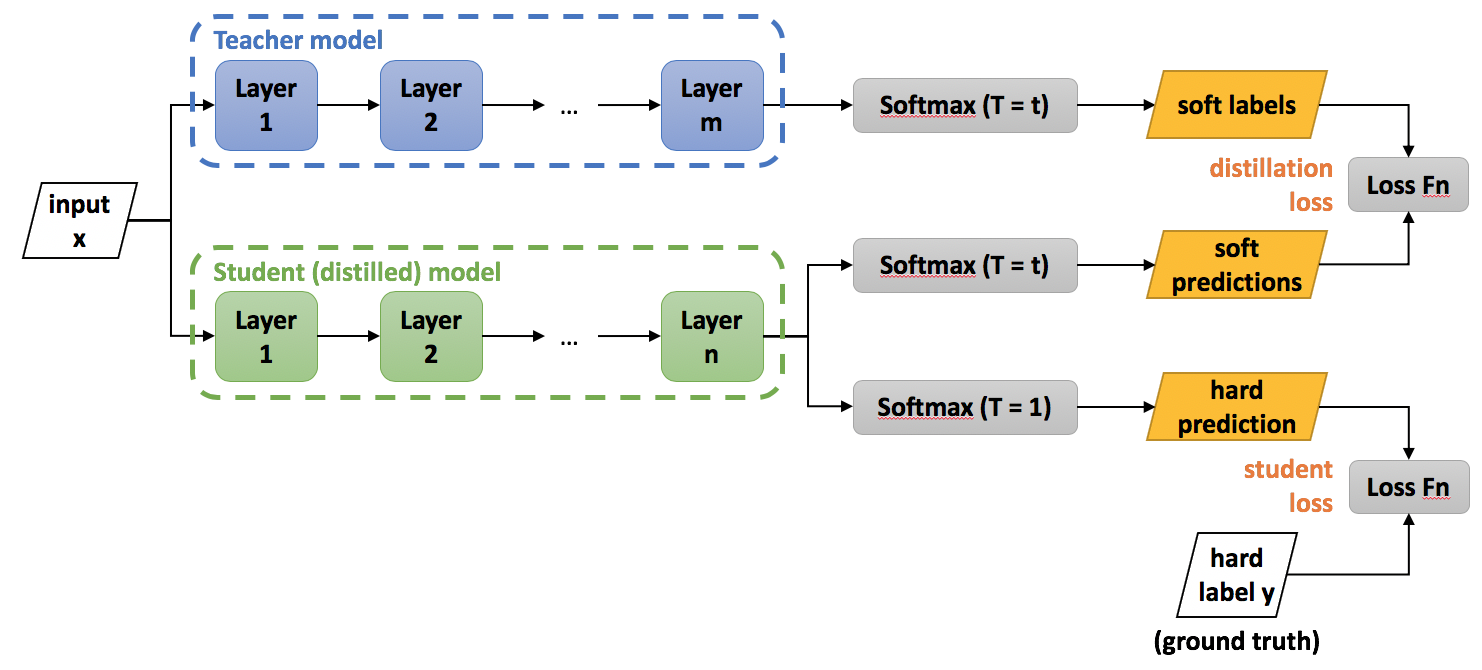
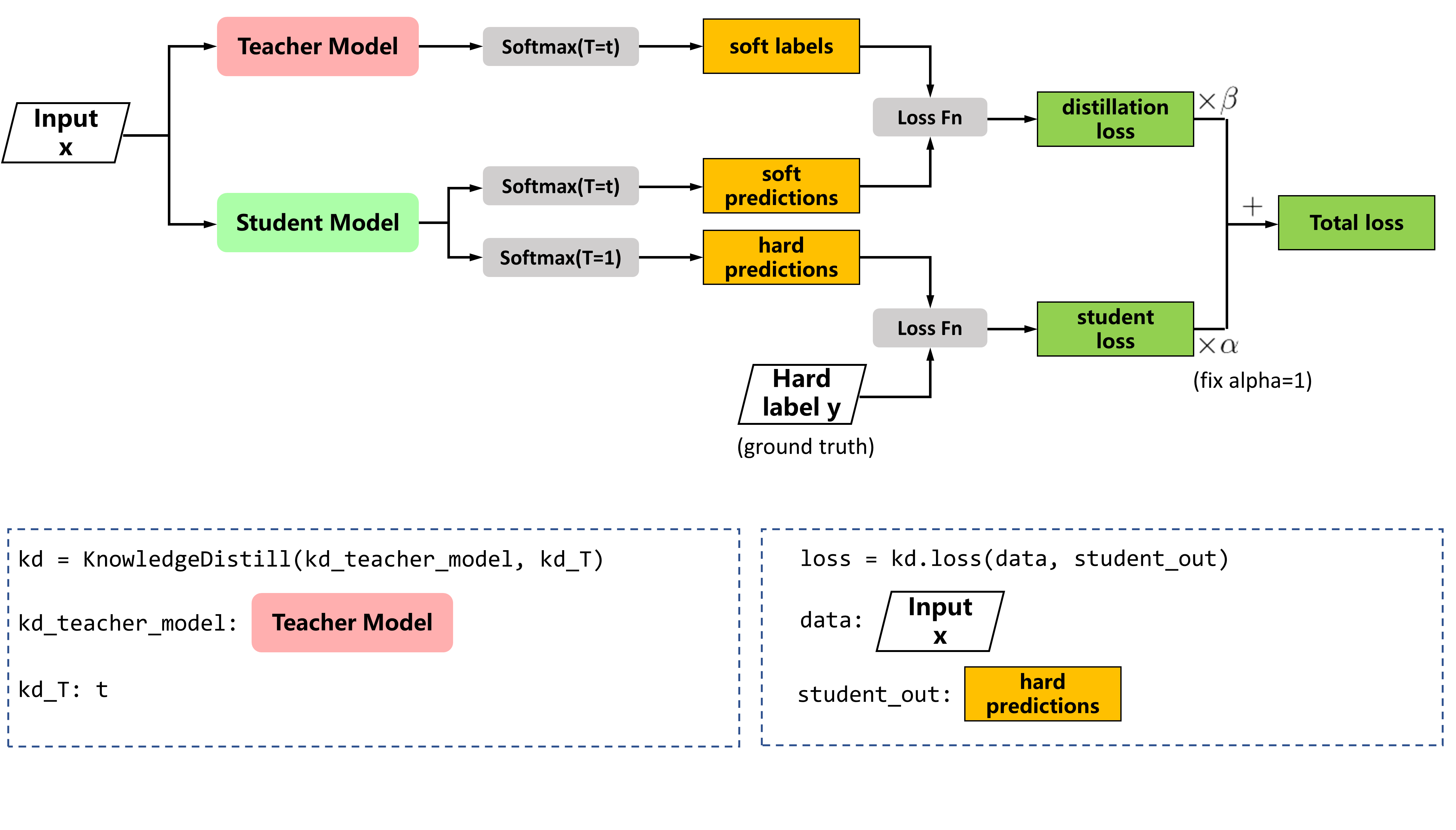
首先有一个已经训练好的教师网络(Teacher model),把很多数据(input)喂给教师网络,教师网络会给每个数据都给一个温度为T的时候的softmax(文中soft labels);
同时把数据(input)喂给学生网络(student model),也给学生网络一个温度T获得softmax(文中soft predictions),对soft labels和soft predictions做一个损失函数L(distillation loss也叫soft loss),让他们两个越接近越好,解释就是学生在模拟老师的预测结果;
学生网络经过一个T=1的普通的softmax(文中的hard prediction)和 hard label再做一个损失函数(student loss也叫hard loss),让他们两个越接近越好。所以这个学生网络既要在温度为T的预测结果和教师网络的预测结果尽可能接近,又要在温度为1的预测结果和标准答案更可能接近。
最终计算过程:
基于特征的知识
经过训练的教师模型还会在其中间层捕获数据知识,这对于深度神经网络尤其重要。中间层会学习区分特定特征,这些知识可用于训练学生模型。目标是训练学生模型学习与教师模型相同的特征激活。蒸馏损失函数通过最小化教师模型和学生模型的特征激活之间的差异来实现这一点。
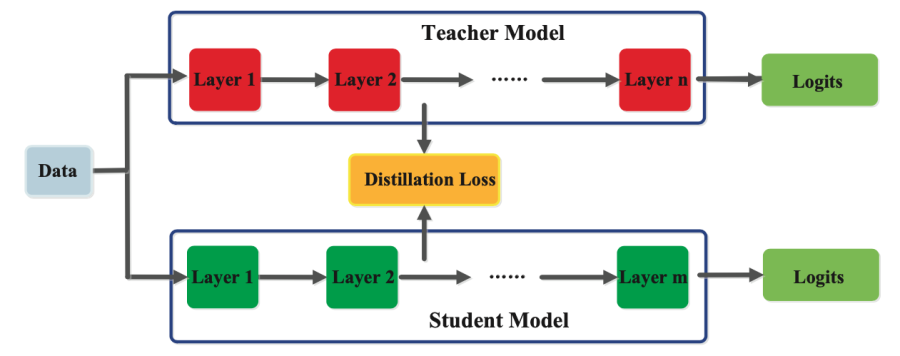
基于关系的知识
除了神经网络的输出层和中间层所表示的知识外,捕捉特征图之间关系的知识也可用于训练学生模型。这种形式的知识称为基于关系的知识。这种关系可以建模为特征图、图形、相似性矩阵、特征嵌入或基于特征表示的概率分布之间的相关性。
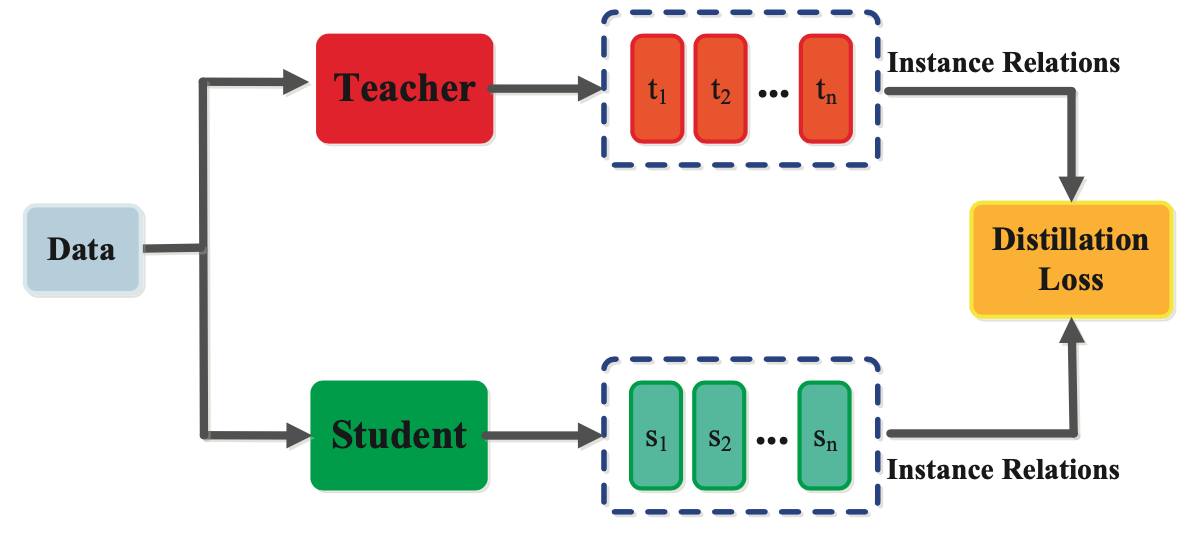
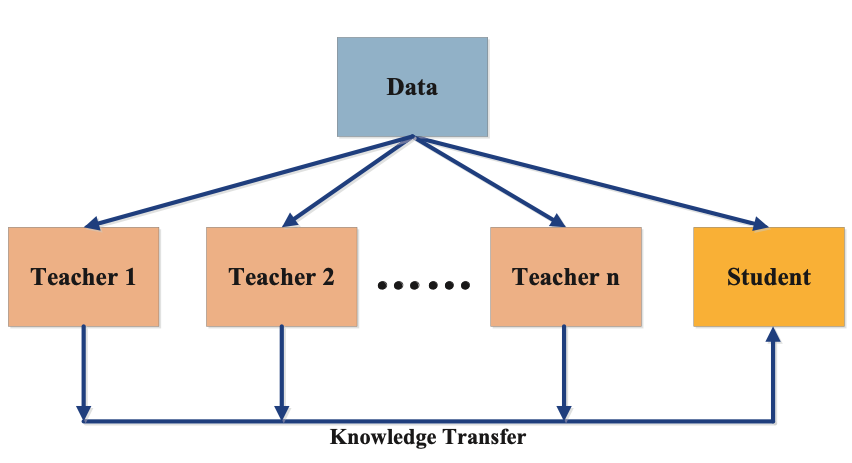
多教师提炼
在多教师提炼中,学生模型从几个不同的教师模型中获取知识。使用一组教师模型可以为学生模型提供不同类型的知识,这些知识比从单个教师模型获得的知识更有益。
来自多位教师的知识可以合并为所有模型的平均响应。通常从教师那里传递的知识类型基于逻辑和特征表示。多位教师可以传递不同类型的知识。
知识蒸馏的应用场景
- 模型压缩
- 优化训练、防止过拟合(潜在的正则化)
- 无限大、无监督数据集的数据挖掘
- 少样本、零样本学习
- 迁移学习和知识蒸馏
- 领域迁徙 模型蒸馏
知识蒸馏发展趋势
- 教学相长(老师和学生模型是否可以相互学习)
- 引入助教,多个老师、多个同学
- 刚才的知识只通过soft targets来表示,只是网络最后一层的预测结果,网络的中间层是不是也可以解刨出来进行知识蒸馏,例如,如下图所示,让学生网络的第一层模拟教师网络的第五层,让学生网络的第二层模拟教师网络的第十层,这样,老师不仅把最后结果告诉你,也把对这个问题的思考告诉学生网络;还可以对数据集进行蒸馏,对比学习进行蒸馏
- 多模态:既有视觉又有文本又有语音怎么蒸馏,对知识图谱进行蒸馏,对预训练大模型进行知识蒸馏
为什么蒸馏这么有效?
- 在许多方面,语言建模是NLP的“终极”任务。
- 一个完美的语言模型也是一个完美的问答/蕴蕴性/情感分析模型
- 训练一个大规模的语言模型学习数以百万计的潜在特征,这些潜在特征对其他NLP任务有用
- 微调大多只是挑选和调整这些现有的潜在特征
- 这需要一个超大的模型,因为只有一部分特征对任何给定的任务有用
- 蒸馏允许模型只关注那些特征
- 支持证据:简单的自蒸馏(提取一个较小的BERT模型)行不通